[논문리뷰] DelTA: Discriminative Token Credit Assignment for Reinforcement Learning from Verifiable Rewards
링크: 논문 PDF로 바로 열기
메타데이터
저자: Kaiyi Zhang, Wei Wu, Yankai Lin, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- RLVR (Reinforcement Learning from Verifiable Rewards): 모델이 생성한 응답에 대해 정답 여부와 같은 검증 가능한 보상 신호를 사용하여 정책을 학습시키는 강화학습 패러다임입니다.
- Token-Gradient Vector: 특정 토큰이 정책의 로그 확률에 미치는 영향력을 나타내는 파라미터 공간상의 벡터로, 본 논문에서는 정책 업데이트 방향을 분석하는 핵심 단위로 사용됩니다.
- Centroid: 특정 Advantage(보상 이득) 측면(Positive 또는 Negative)의 토큰-그래디언트 벡터들을 가중 평균하여 구성한 참조 방향(Reference Direction)입니다.
- DelTA (Discriminative Token Credit Assignment): 토큰-그래디언트 벡터들이 각 측면(Positive/Negative)을 얼마나 잘 구분하는지에 따라 가중치를 부여하여, 정책 업데이트 방향을 보다 대조적(Contrastive)으로 재형성하는 방법론입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 시퀀스 단위의 보상을 토큰 단위의 학습 신호로 변환할 때 발생하는 불투명성을 해결하기 위해 DelTA를 제안합니다. 기존의 RLVR 방식은 응답 전체에 대해 단일 스칼라 보상을 부여하지만, 실제 정책 업데이트는 토큰별로 이루어지므로 Granularity(세분성)의 불일치가 존재합니다. 연구진은 RLVR 업데이트가 암시적으로 토큰-그래디언트 공간에서 선형 판별기(Linear Discriminator) 역할을 한다는 점을 규명하였습니다 [Figure 1]. 그러나 기존 방식은 자주 등장하는 서식 토큰 등 공통적인 배경 패턴으로 인해 판별기의 성능이 저하되며, 이는 실제 보상 차이를 구분하는 핵심적인 토큰 신호를 희석시키는 결과를 초래합니다.
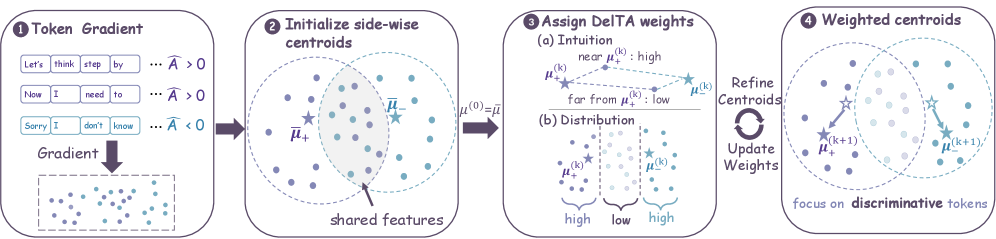
Figure 1 — DelTA 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
DelTA는 토큰-그래디언트 벡터 간의 차별적 신호를 추정하여, 각 측면에 특화된 방향은 증폭하고 공유되거나 약한 신호는 억제하는 방식으로 정책 업데이트 방향을 재형성합니다. 구체적으로 DelTA는 초기 Centroid를 설정한 후, 반복적인 정제(Refinement) 과정을 통해 토큰별 가중치 계수를 산출하고, 이를 바탕으로 DAPO와 같은 기존 RLVR 서로게이트를 재가중(Reweight)합니다 [Figure 1]. 실험 결과, DelTA는 7개 수학적 벤치마크에서 기존 최고 수준의 베이스라인 대비 평균 점수를 크게 향상시켰습니다. 예를 들어, Qwen3-8B-Base 모델에서는 기존 25.14에서 28.40으로, Qwen3-14B-Base 모델에서는 37.29에서 39.91로 성능을 개선하였습니다 [Table 1]. 또한, 학습 동역학 분석을 통해 DelTA가 더 높은 보상을 유지하면서도 보다 자신감 있고 안정적인 장기 추론(Long-reasoning) 능력을 유도함을 확인하였습니다 [Figure 2].
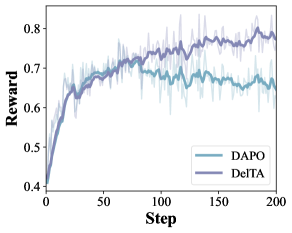
Figure 2 — 학습 동역학 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 RLVR 업데이트를 로컬 판별기로 해석하는 관점을 제시하고, 이를 최적화하기 위한 DelTA 방법론을 도입하였습니다. 이 연구는 기존의 응답 단위 보상이 가진 한계를 토큰 단위의 차별적 신호 할당을 통해 극복함으로써, 모델의 추론 능력 향상에 크게 기여합니다. DelTA의 성능 개선은 수학적 추론을 넘어 코드 생성 및 범용 도메인으로 확장 가능함을 입증하였으며, 향후 LLM 학습 시 보다 효율적이고 해석 가능한 Credit Assignment 기술 개발에 중요한 토대가 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] From Reasoning Chains to Verifiable Subproblems: Curriculum Reinforcement Learning Enables Credit Assignment for LLM Reasoning
- [논문리뷰] CEPO: RLVR Self-Distillation using Contrastive Evidence Policy Optimization
- [논문리뷰] Self-Distilled RLVR
- [논문리뷰] When Does Muon Help Agentic Reinforcement Learning?
- [논문리뷰] Beyond Entropy: Correctness-Aware Advantage Shaping via Contrastive Policy Optimization
Review 의 다른글
- 이전글 [논문리뷰] DecQ: Detail-Condensing Queries for Enhanced Reconstruction and Generation in Representation Autoencoders
- 현재글 : [논문리뷰] DelTA: Discriminative Token Credit Assignment for Reinforcement Learning from Verifiable Rewards
- 다음글 [논문리뷰] Diversed Model Discovery via Structured Table Discovery
댓글