[논문리뷰] DecQ: Detail-Condensing Queries for Enhanced Reconstruction and Generation in Representation Autoencoders
링크: 논문 PDF로 바로 열기
메타데이터
저자: Tianhang Wang, Yitong Chen, Wei Song, Zuxuan Wu, Min Li, Jiaqi Wang
1. Key Terms & Definitions (핵심 용어 및 정의)
- RAE (Representation Autoencoders): Frozen Vision Foundation Models(VFMs)를 인코더로 활용하여 고수준의 의미론적 특징(semantic representations)을 추출하고, 이를 바탕으로 데이터 생성 및 재구성을 수행하는 프레임워크입니다.
- Detail-Condensing Queries: Frozen VFM의 중간 계층(intermediate layers)에서 세밀한 시각적 세부 정보(fine-grained details)를 추출하기 위해 도입된 학습 가능한 쿼리 토큰입니다.
- Condenser Module: VFM의 중간 계층 패치 토큰에서 쿼리 토큰으로 정보를 집약(aggregate)하는 모듈로, Cross-Attention과 FFN으로 구성됩니다.
- Reconstruction–Generation Trade-off: VFM의 의미적 일관성을 유지하면서 재구성 정확도를 높이려 할 때, 오히려 생성 성능이 저하되는 현상입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 RAE의 frozen VFM 인코더가 갖는 낮은 공간적 재구성 능력이 고품질 이미지 생성 및 세밀한 편집을 제한하는 문제를 해결하고자 합니다. 기존의 RAE 모델은 고수준의 의미론적 정보를 잘 유지하지만, VFM 학습 목적 상 색상이나 텍스처와 같은 저수준 세부 정보가 누락되는 경향이 있습니다 [Figure 1]. 이러한 문제를 해결하기 위해 VFM을 파인튜닝하거나 추가적인 재구성 신호를 결합하면, 기존에 확보한 강력한 의미적 잠재 공간(semantic latent space)이 오염되는 부작용이 발생합니다 [Figure 1]. 따라서 저자들은 기존 VFM의 의미적 구조를 전혀 건드리지 않고도 재구성 품질과 생성 성능을 동시에 향상할 수 있는 새로운 접근 방식을 제안합니다.
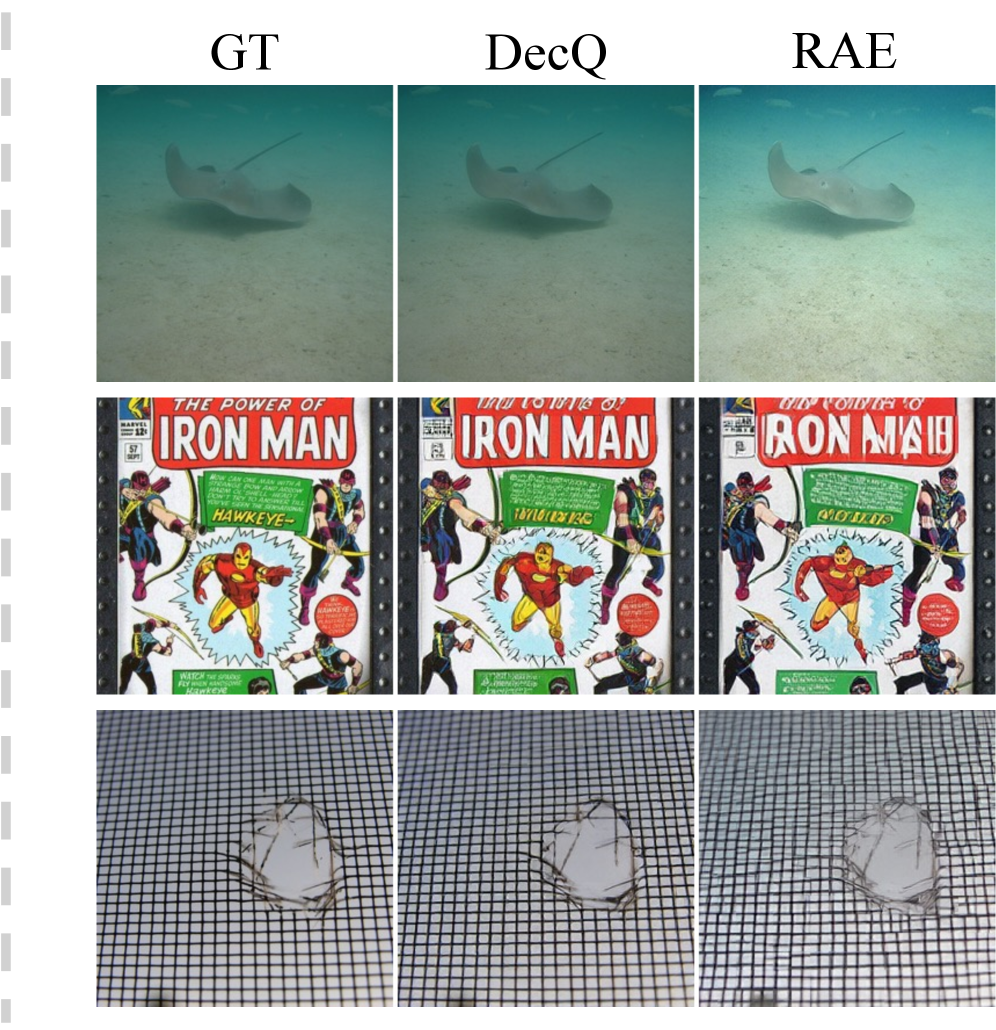
Figure 1 — VFM 토크나이저 패러다임 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 DecQ라는 프레임워크를 제안하여, Frozen VFM에 8개의 학습 가능한 Detail-Condensing Queries를 결합함으로써 재구성과 생성 성능을 최적화합니다 [Figure 2]. Condenser 모듈은 VFM의 중간 계층(layer 0, 3, 6, 9)에서 Cross-Attention을 통해 세밀한 정보를 추출하며, 이렇게 추출된 쿼리 토큰은 생성 모델링 과정에서 패치 토큰과 함께 공동으로 노이즈 제거(jointly denoising)됩니다 [Figure 3, Figure 4]. 실험 결과, DecQ는 frozen DINOv2 기반 RAE 대비 PSNR 수치를 19.13 dB에서 22.76 dB로 크게 향상시켰습니다 [Table 1]. 생성 측면에서도 RAE보다 3.3배 빠른 수렴 속도를 보였으며, 가이드 없이 FID 1.41, 가이드 포함 FID 1.05라는 우수한 성능을 달성하였습니다 [Table 2]. 이는 제안된 쿼리 구조가 원본 의미 공간을 훼손하지 않고도 추가적인 저수준 정보를 효과적으로 보완함을 입증합니다.
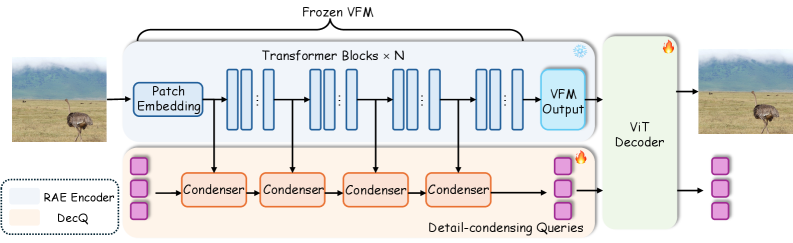
Figure 2 — DecQ 전체 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 연구는 DecQ 프레임워크를 통해 VFM 기반 생성 모델의 고질적인 재구성-생성 간 상충 관계(trade-off)를 성공적으로 해결하였습니다. 학습 가능한 쿼리 토큰을 사용하여 세부 정보를 효율적으로 집약함으로써, 모델의 파라미터나 계산 비용을 3.9% 수준의 최소한의 오버헤드로 유지하면서도 이미지 재구성 및 생성 품질을 극대화했습니다. 이 연구는 대규모 사전 학습된 VFM을 고성능 이미지 생성 토크나이저로 변환하는 실용적인 방법론을 제시하며, 향후 더 복잡한 시각 생성 작업에서 VFM의 가치를 효과적으로 활용할 수 있는 토대를 마련했습니다.
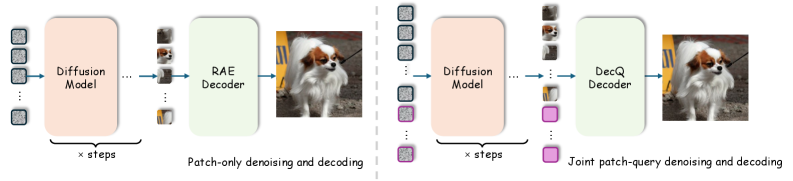
Figure 4 — 쿼리 기반 이미지 생성
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Boosting Latent Diffusion Models via Disentangled Representation Alignment
- [논문리뷰] REGLUE Your Latents with Global and Local Semantics for Entangled Diffusion
- [논문리뷰] VideoRAE: Taming Video Foundation Models for Generative Modeling via Representation Autoencoders
- [논문리뷰] RaysUp: Ultra-light Universal Feature Upsampling via Geometry-Aware Ray Representation
- [논문리뷰] FedOT: Ownership Verification and Leakage Tracing via Watermarks for Federated LDMs
Review 의 다른글
- 이전글 [논문리뷰] ClinSeekAgent: Automating Multimodal Evidence Seeking for Agentic Clinical Reasoning
- 현재글 : [논문리뷰] DecQ: Detail-Condensing Queries for Enhanced Reconstruction and Generation in Representation Autoencoders
- 다음글 [논문리뷰] DelTA: Discriminative Token Credit Assignment for Reinforcement Learning from Verifiable Rewards
댓글