[논문리뷰] Full Attention Strikes Back: Transferring Full Attention into Sparse within Hundred Training Steps
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yanke Zhou, Yiduo Li, Hanlin Tang, Maohua Li, Kan Liu, Lan Tao, Lin Qu, Yuan Yao, Xiaoxing Ma
1. Key Terms & Definitions (핵심 용어 및 정의)
- Retrieval Heads: 전체 컨텍스트 중 장거리(long-range) 의존성을 파악하는 특화된 어텐션 헤드로, full KV cache를 유지하여 주요 정보를 검색함.
- Low-dimensional Projection: RoPE의 거리 민감성을 회피하기 위해 pre-RoPE 레이어에서 수행하는 저차원(16-dim) 투영으로, 효율적인 토큰 중요도 평가를 가능하게 함.
- Dynamic Top-pp Selection: 고정된 수의 토큰을 선택하는
top-kk방식과 달리, 쿼리별 중요도에 따라 동적으로 토큰을 선택하여 Attention Mass를 확보하는 기법. - Self-distillation: sparsified 모델이 dense 모델의 출력(logit)을 모방하도록 훈련하여 성능 저하를 최소화하는 경량화 학습 기법.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Long-context 추론 시 발생하는 full attention의 이차 비용(quadratic cost) 문제를 해결하기 위해 효율적인 스파스(sparse) 구조로의 전환을 제안한다. 기존의 sparse attention 방식들은 모델 학습 초기부터 native한 sparse 사전 학습을 요구하거나, 휴리스틱한 토큰 제거(token eviction)를 사용하여 효율성과 정확도 사이의 trade-off를 유발한다. 저자들은 사전에 학습된 LLM이 이미 head-wise 및 token-wise 수준에서 내재적인 스파스성을 보유하고 있음을 발견하였다 [Figure 2]. 따라서, 별도의 대규모 사전 학습 없이 경량화된 surgery만으로 모델의 Long-context 능력을 보존하면서 추론 성능을 극대화하는 것이 본 연구의 목표이다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 RTPurbo라는 head-wise sparse attention 프레임워크를 제안하며, 3단계의 핵심 프로세스를 포함한다 [Figure 4]. 첫째, 오프라인 교정(calibration)을 통해 모델을 Retrieval heads와 Local heads로 구분한다. 둘째, 16차원의 저차원 투영기를 활용하여 효율적인 토큰 중요도를 계산하고, Dynamic Top-pp Selection을 통해 상황에 맞는 가변적인 토큰 예산을 할당한다 [Table 1]. 마지막으로, 원본 모델을 teacher로 삼아 sparse 모델이 이를 모방하도록 약 100회 정도의 학습 단계에서 end-to-end Self-distillation을 수행한다.
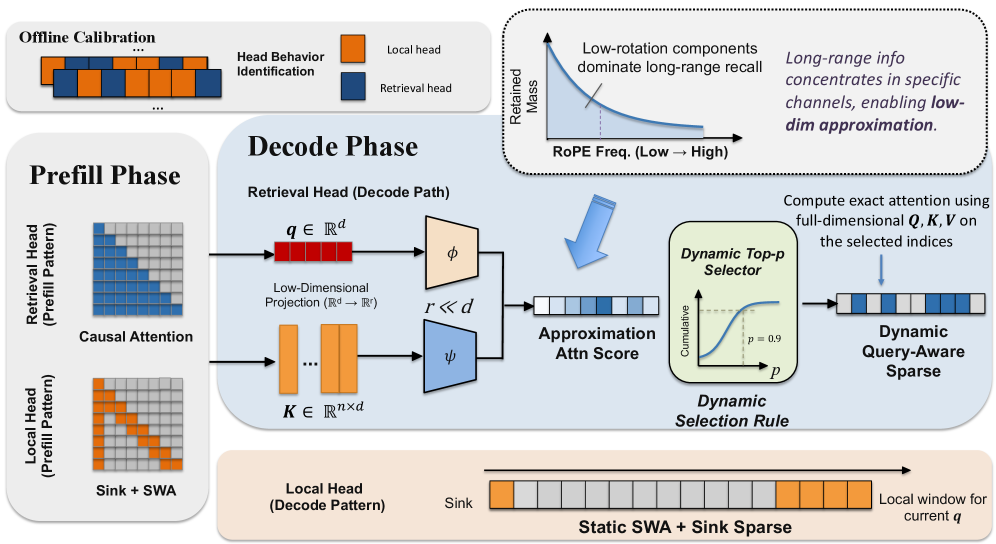
Figure 4 — RTPurbo 전체 아키텍처
실험 결과, RTPurbo는 다양한 Long-context 및 추론 벤치마크에서 near-lossless 정확도를 유지하면서도 탁월한 효율성을 입증하였다 [Table 3, Table 4]. 특히, 1M context 환경에서 prefill 단계는 최대 9.36×, decode 단계에서는 **2.01×**의 속도 향상을 기록하였다 [Figure 1, Figure 7]. 또한, 극단적인 컨텍스트 길이(512K)에서도 타 스파스 모델 대비 훨씬 robust한 성능을 보였다 [Figure 6].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 고비용의 full-attention 모델을 최소한의 적응(minimal adaptation)만으로 고효율 sparse 모델로 변환할 수 있음을 입증하였다. 100회 미만의 학습 단계만으로도 full-attention 모델의 강력한 성능을 보존할 수 있다는 점은 대규모 sparse 사전 학습의 대안으로서 큰 학술적·산업적 가치를 지닌다. 또한, 본 연구가 제안하는 RTPurbo 프레임워크는 Long-context LLM의 실시간 추론 효율성을 크게 개선하여, 복잡한 문서 분석 및 대규모 추론 서비스 환경에서 강력한 실용성을 발휘할 것으로 기대된다.
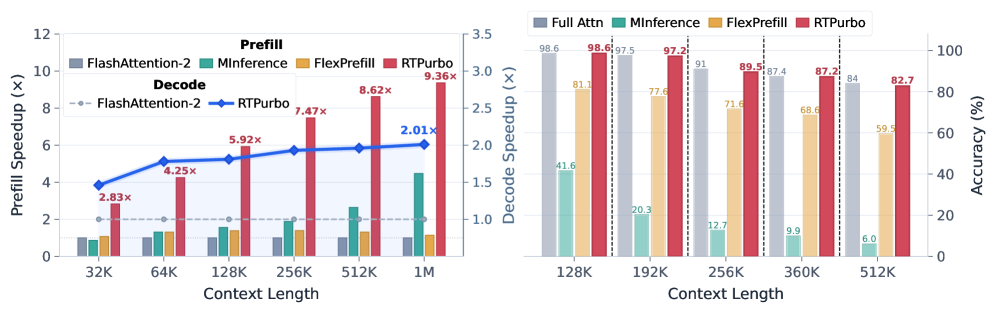
Figure 1 — RTPurbo의 효율성 및 정확도
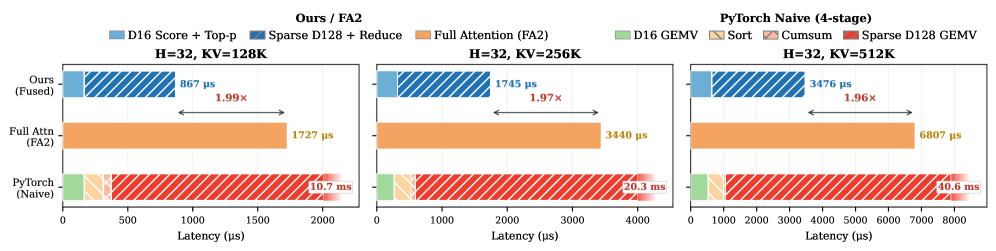
Figure 7 — Sparse 디코딩 속도 향상
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] HunyuanVideo 1.5 Technical Report
- [논문리뷰] AsySplat: Efficient Asymmetric 3D Gaussian Splatting for Long-Sequence Scene Modeling
- [논문리뷰] Hierarchical Sparse Attention Done Right: Toward Infinite Context Modeling
- [논문리뷰] KVpop -- Key-Value Cache Compression with Predictive Online Pruning
- [논문리뷰] One Forward Beats Two: InnerZoom for Accurate and Efficient GUI Grounding
Review 의 다른글
- 이전글 [논문리뷰] From Reasoning Chains to Verifiable Subproblems: Curriculum Reinforcement Learning Enables Credit Assignment for LLM Reasoning
- 현재글 : [논문리뷰] Full Attention Strikes Back: Transferring Full Attention into Sparse within Hundred Training Steps
- 다음글 [논문리뷰] Gated DeltaNet-2: Decoupling Erase and Write in Linear Attention
댓글