[논문리뷰] ReNIO: Reweighting Negative Trajectory Importance for LLM On-Policy Distillation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Chen Lin, Kedi Chen, Wei Zhang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- OPD (On-Policy Distillation): 학생 모델이 스스로 생성한 출력(SGO)을 사용하여, 해당 경로의 prefix에서 교사 모델의 분포를 모방하도록 학습하는 방법론입니다.
- OPSD (On-Policy Self Distillation): 교사 모델 없이, 학생 모델 자신의 초기 파라미터를 기반으로 생성된 출력에 대해 자기 증류를 수행하는 방식입니다.
- SGO (Student-Generated Output): 학생 모델이 특정 프롬프트에 대해 스스로 생성한 추론 경로(reasoning trace)입니다.
- Pivotal Token: 학생 모델이 특정 prefix에서 교사 모델과 다른 선택을 하여 잘못된 추론 경로로 진입하게 만드는 결정적인 토큰을 의미합니다.
- Prefix-conditioned Probability: 전체 문장을 생성 완료하기 전, 현재까지의 prefix를 바탕으로 다음 토큰을 예측하는 확률 분포를 지칭합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 표준 OPD 및 OPSD가 모든 SGO를 균등하게 취급하여 효율적인 학습 기회를 놓치고 있다는 점을 문제로 지적합니다. 연구진의 실험 결과, 올바른 추론 결과물보다 잘못된 추론 결과물(incorrect SGO)로 학습할 때 성능 향상이 더 컸으며, 이는 잘못된 경로가 더 구조적이고 탐색적인 학습 신호를 포함하고 있기 때문임을 확인했습니다 [Figure 1]. 그러나 기존의 정답 여부에 기반한 가중치 부여 방식은 전체 추론 완료(full-rollout)를 기다려야 하므로 OPD의 주요 장점인 짧은 prefix 학습 효율성을 저해합니다. 따라서 정답 레이블 없이도 중요한 부정적(negative) 경로를 식별하고 강조할 수 있는 새로운 가중치 부여 방식이 필요합니다 [Figure 1].
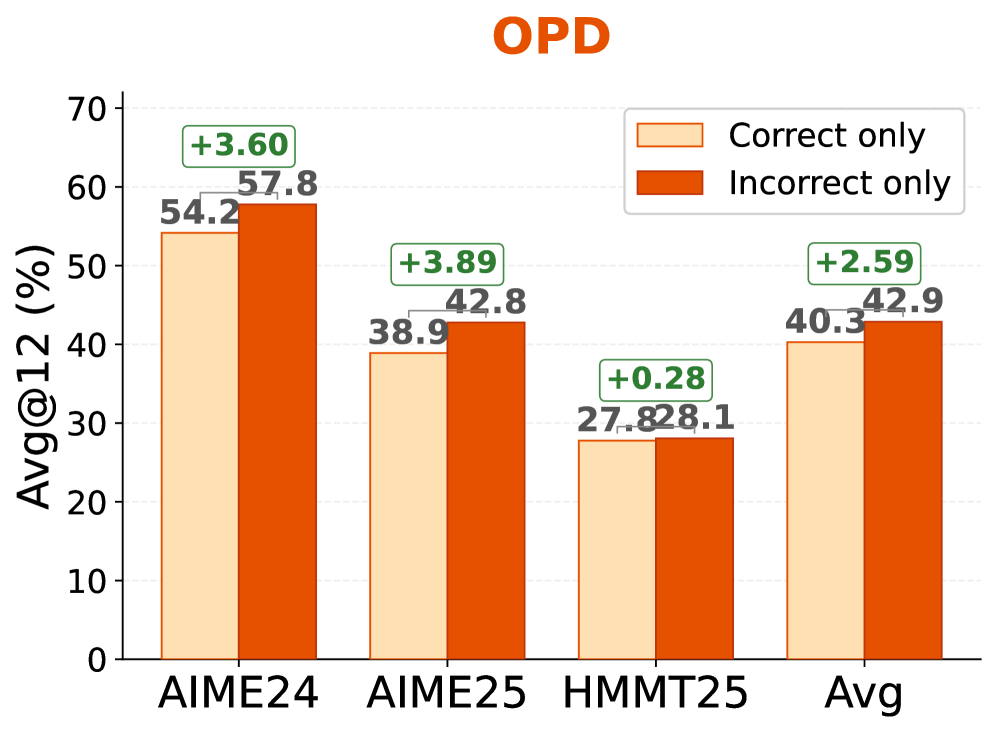
Figure 1 — 학습 방식별 성능 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 ReNIO(Reweighting Negative Trajectory Importance)를 제안하여, 정답 레이블 없이 prefix 수준의 학생-교사 확률 비율을 통해 SGO의 중요도를 자동 산출합니다 [Figure 2]. 핵심 아이디어는 학생의 다음 토큰 예측 확률이 교사보다 훨씬 높은 경우를 pivotal token으로 간주하고, 이들의 로그 비율(log-ratio)을 기하 평균으로 집계하여 배치 내 정규화된 샘플 가중치를 할당하는 것입니다 [Figure 2]. 이 방식은 정답 확인 없이도 학습 신호를 조정할 수 있어 기존 OPD의 저비용 학습 구조를 그대로 유지합니다 [Figure 3]. 실험 결과, ReNIO는 수학 및 코드 생성 작업에서 성능을 일관되게 개선했습니다. 대표적으로 Qwen3-1.7B 모델에서 최대 8.90%, R1-Distill-Qwen-7B 모델에서 최대 10.00%의 상대적 성능 향상을 기록했습니다 [Table 1]. 또한, OPSD에서 1024-token의 짧은 prefix를 사용하여 학습함에도 불구하고 더 긴 prefix를 사용하는 경우보다 우수한 효율성과 효과를 보였습니다 [Table 3].
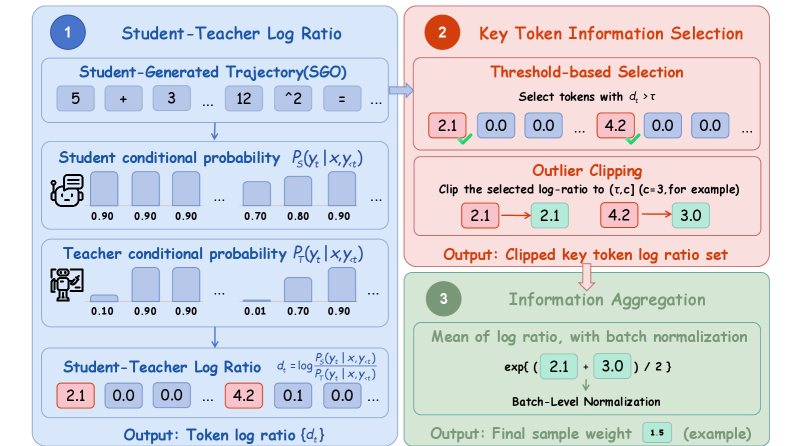
Figure 2 — ReNIO 전체 파이프라인
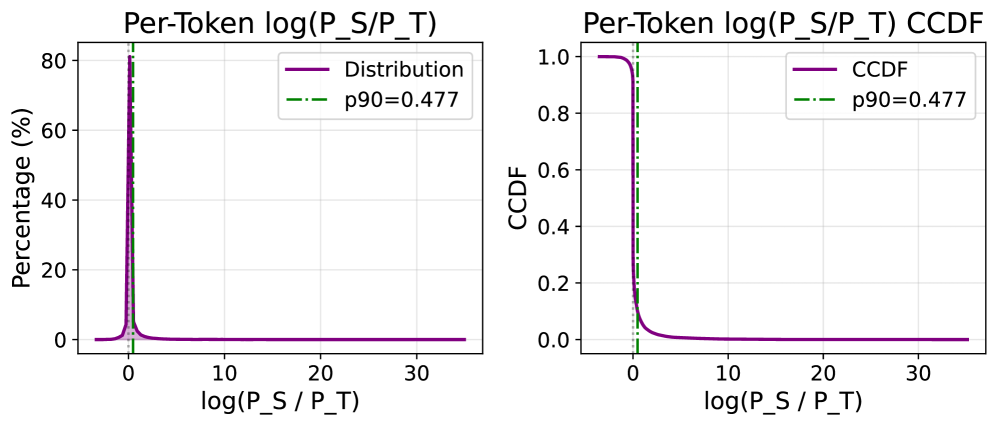
Figure 3 — 토큰 수준 로그 비율 분포
4. Conclusion & Impact (결론 및 시사점)
본 연구는 잘못된 추론 경로가 LLM의 추론 능력을 강화하는 데 더 가치 있는 학습 신호를 제공할 수 있음을 규명하고 이를 효과적으로 활용하는 ReNIO를 제안했습니다. ReNIO는 추가적인 답변 레이블이나 긴 전체 추론 경로 생성 비용 없이, 확률적 불일치만을 이용하여 효율적으로 학습 가중치를 조정할 수 있습니다. 이러한 접근은 대규모 언어 모델의 사후 학습(post-training) 효율성을 극대화하고, 특히 추론 능력을 요하는 복잡한 태스크에서 모델의 탐색적 능력을 보존하는 데 중요한 시사점을 제공합니다. 향후 본 기법은 더 큰 규모의 모델 및 다양한 추론 태스크로 확장 적용될 잠재력이 큽니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OPRD: On-Policy Representation Distillation
- [논문리뷰] Filter, Then Reweight: Rethinking Optimization Granularity in On-Policy Distillation
- [논문리뷰] Trust Region On-Policy Distillation
- [논문리뷰] ETCHR: Editing To Clarify and Harness Reasoning
- [논문리뷰] A Survey of On-Policy Distillation for Large Language Models
Review 의 다른글
- 이전글 [논문리뷰] RL-Index: Reinforcement Learning for Retrieval Index Reasoning
- 현재글 : [논문리뷰] ReNIO: Reweighting Negative Trajectory Importance for LLM On-Policy Distillation
- 다음글 [논문리뷰] RoPE-Aware Bit Allocation for KV-Cache Quantization
댓글