[논문리뷰] RoPE-Aware Bit Allocation for KV-Cache Quantization
링크: 논문 PDF로 바로 열기
메타데이터
저자: Fengfeng Liang, Yuechen Zhang, Jiaya Jia, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- RoPE (Rotary Position Embedding): 고차원 벡터를 2차원 블록 단위의 회전 행렬로 표현하여 상대적 위치 정보를 모델에 주입하는 기법입니다.
- TQ-MSE (TurboQuant-MSE): 벡터를 회전 및 양자화하여 Near-optimal한 Distortion Rate를 달성하는 로컬 벡터 양자화 기법입니다.
- Block-GTQ: RoPE 블록별 에너지 점수를 기반으로 Greedy하게 Bit Allocation을 수행하여 고에너지 블록에 더 많은 비트를 할당하는 방식입니다.
- KV-Cache: 대규모 언어 모델(LLM)의 Autoregressive Decoding 과정에서 재사용되는 이전 토큰들의 Key와 Value 상태 정보를 저장하는 메모리 캐시입니다.
- Packed-Cache: 압축된 K/V 데이터를 직접적으로 사용하여 HBM 대역폭 효율을 극대화하고, fp16 KV Cache의 완전한 형상화(Materialization)를 방지하는 서비스 경로입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 KV-Cache 양자화 기법들이 Key를 단순한 평면 벡터(Flat Vector)로 취급하여 발생하는 정보 손실 문제를 해결하고자 합니다. RoPE 기반의 Attention에서 Query와 Key의 연산은 특정 주파수 블록들의 합으로 분해되는데, 기존의 균일한(Uniform) 비트 할당 방식은 에너지(중요도)가 높은 RoPE 블록과 낮은 블록을 구분하지 못해 성능 저하를 초래합니다 [Figure 1]. 이러한 비효율은 특히 Long-context 추론 시 Cache Capacity와 HBM 대역폭 병목 현상을 심화시키며, 정확도 저하로 이어집니다. 따라서 저자들은 로짓(Logit) 보존을 위해 RoPE 블록별 중요도를 고려한 동적 비트 할당 전략의 필요성을 제기합니다.
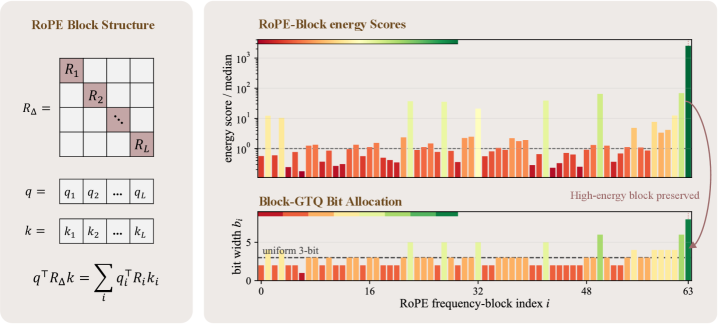
Figure 1 — RoPE 블록 기반 비트 할당 개념
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 RoPE 블록의 기하학적 에너지를 활용하여 각 블록에 차등적인 정수 비트를 할당하는 Block-GTQ를 제안합니다. 제안 방법론은 먼저 Calibration 데이터를 통해 레이어 및 헤드별 RoPE 블록의 에너지 점수 $s_i$를 산출하고, TQ-MSE의 $4^{-b}$ 속도를 기반으로 전체 Budget 내에서 가장 Marginal Gain이 큰 블록에 우선적으로 비트를 할당하는 Greedy Algorithm을 수행합니다 [Figure 1]. 실험 결과, Block-GTQ는 다양한 10개 모델 패널에서 Uniform TQ-MSE 대비 per-layer RoPE-logit MAE를 32%~80% 감소시키며 모든 레이어 비교에서 우위를 점했습니다 [Table 1]. Llama-3.1-8B-Instruct 모델 기준, K2V2 설정에서 NIAH(Needle In A Haystack) 성능을 70.6에서 97.4로, LongBench-EN 성능을 36.87에서 53.31로 대폭 향상했습니다. 또한 Packed-Cache 배포 환경에서 Qwen2.5-3B-Instruct 모델을 통해 fp16 대비 3.24배의 압축률을 달성하고, 128K 컨텍스트에서 fp16 FlashAttention-2 대비 1.34배 빠른 Decode Latency를 기록했습니다 [Figure 2].
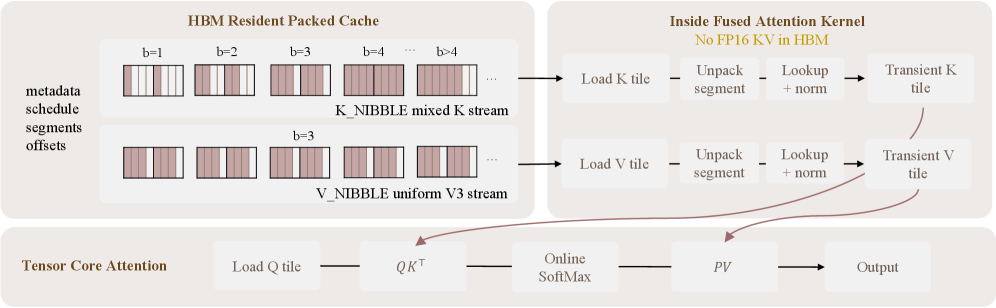
Figure 2 — Packed-Cache 서비스 경로
4. Conclusion & Impact (결론 및 시사점)
본 연구는 RoPE 구조와 연계된 차등적 비트 할당 전략이 LLM의 KV-Cache 효율성을 획기적으로 개선할 수 있음을 입증했습니다. Block-GTQ는 로짓 보존 성능뿐만 아니라 실질적인 Long-context 추론 및 메모리 압축 측면에서 탁월한 효율을 보여주었습니다. 이 연구는 고성능 LLM 추론을 위한 메모리 제약 완화 기술로서, 특히 제한된 GPU 자원 하에서 초장문 컨텍스트(512K 이상)를 다루는 서비스에 있어 핵심적인 시사점을 제공합니다. 향후 다양한 모델 아키텍처 및 하드웨어 환경으로의 확장이 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] JetSpec: Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree Drafting
- [논문리뷰] When is Your LLM Steerable?
- [논문리뷰] VIA-SD: Verification via Intra-Model Routing for Speculative Decoding
- [논문리뷰] PianoKontext: Expressive Performance Rendering from Deadpan Context
- [논문리뷰] Echo-Infinity: Learning Evolving Memory for Real-Time Infinite Video Generation
Review 의 다른글
- 이전글 [논문리뷰] ReNIO: Reweighting Negative Trajectory Importance for LLM On-Policy Distillation
- 현재글 : [논문리뷰] RoPE-Aware Bit Allocation for KV-Cache Quantization
- 다음글 [논문리뷰] ShutterMuse: Capture-Time Photography Guidance with MLLMs
댓글