[논문리뷰] SoundnessBench: Can Your AI Scientist Really Tell Good Research Ideas from Bad Ones?
링크: 논문 PDF로 바로 열기
메타데이터
저자: Sy-Tuyen Ho, Minghui Liu, Huy Nghiem, Furong Huang
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- SoundnessBench:
ICLR제출 논문들의Reviewer평가Soundness점수를 활용하여 재구성한 1,099개의 ML 연구 제안(Proposal) 데이터셋입니다. - Optimism Bias: LLM이 낮은
Methodological Soundness를 가진 연구 제안을 높은 확률로Sound하다고 잘못 판단하는 시스템적 경향성입니다. - First-gate Evaluation: 연구가 수행되기 이전(Pre-execution) 단계에서 제안된 아이디어와 실험 설계의 타당성을 평가하여 연구 자원 낭비를 방지하는 필터링 과정입니다.
- Aggressive Prompting: 모델의 판단 기준을 엄격하게 강화하여, 명확한 근거가 없는 경우 기본적으로
Lowsoundness로 분류하도록 유도하는 평가 프로토콜입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Autonomous AI Agents가 연구 파이프라인을 자동화함에 따라, 무분별한 실험 수행 전에 아이디어의 타당성을 걸러내는 First-gate 단계가 필수적임을 강조합니다. 기존 연구들은 주로 Execution 중심의 성능 평가에 집중되어 있어, 아이디어 자체의 Methodological Soundness를 사전에 평가하는 능력은 제대로 검증되지 않았습니다. 저자들은 현재의 LLM이 잘못된 설계에 기반한 연구를 무비판적으로 추구할 위험이 있다고 지적하며, 이를 체계적으로 평가할 수 있는 SoundnessBench를 구축했습니다 [Figure 1].
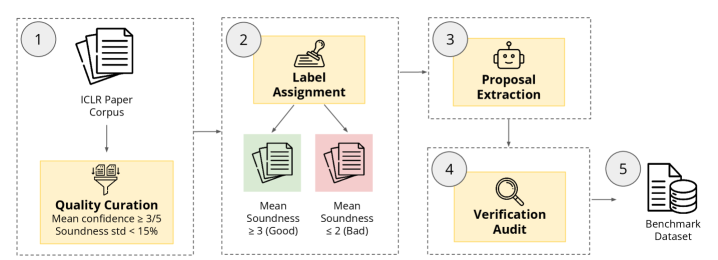
Figure 1 — SoundnessBench 구축 파이프라인
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 ICLR 제출 이력에서 높은 Reviewer 동의율을 보인 1,099개의 제안을 선별하고, Atomic-claim Auditing 기법을 통해 데이터의 신뢰성을 확보한 SoundnessBench를 구축했습니다 [Figure 1], [Figure 2]. 12개의 Frontier LLM을 대상으로 성능을 측정한 결과, Standard Prompting 환경에서 Mean false-positive rate가 74.0%에 달하는 심각한 Optimism Bias가 발견되었습니다 [Figure 3]. 이를 교정하기 위해 적용한 Aggressive Prompting은 False-positive를 19.9%로 낮추었으나, 반대로 High-soundness 연구를 거부하는 False-negative가 급증하여 High-soundness recall이 36.1%까지 하락하는 성능 저하를 보였습니다 [Table 2]. 특히 모델의 Scale을 키워도 이러한 Optimism Bias는 해결되지 않았으며, 오히려 더 큰 모델에서 더욱 permissive한 태도를 보이는 경향이 확인되었습니다 [Figure 4]. 이러한 결과는 현재의 LLM이 전문적인 연구 게이트키퍼 역할을 수행하기에는 프롬프트 변화에 지나치게 민감하며, 안정적인 판단 역량이 부족함을 시사합니다 [Figure 5].
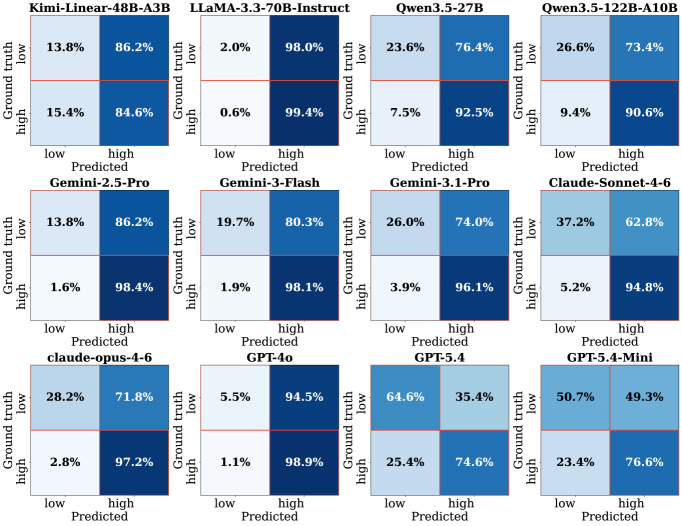
Figure 3 — 모델별 판단 정확도 비교(표준 프롬프트)
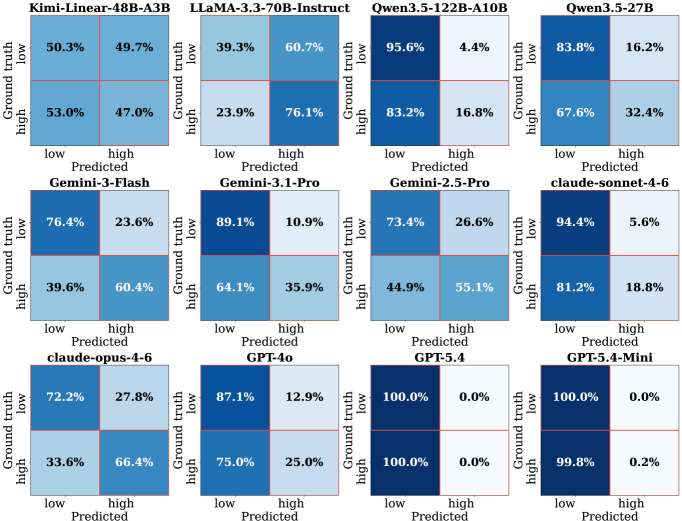
Figure 5 — 공격적 프롬프트 시 결과 변화
## 4. Conclusion & Impact (결론 및 시사점)
본 연구는 LLM 기반의 AI Scientist 에이전트가 연구 초기 단계에서 마주하는 과학적 타당성 평가의 취약성을 명확히 규명했습니다. 연구 결과는 단순히 프롬프트 엔지니어링이나 모델 크기 확대만으로는 과학적 엄밀성을 보장할 수 없음을 보여주며, Targeted training이나 Calibration과 같은 근본적인 보완책이 필요함을 시사합니다. 이 연구는 미래의 자율 연구 에이전트가 더 안전하고 효율적으로 작동하도록 돕는 중요한 평가 지표를 제공하며, 학계와 산업계 전반에 걸쳐 AI의 과학적 추론 신뢰성을 재고하는 계기가 될 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] RecGPT-V3 Technical Report
- [논문리뷰] Agon: Competitive Cross-Model RL with Implicit Rival Grading of Reasoning
- [논문리뷰] Spectral Rewiring for Exploration, Purification, and Model Merging
- [논문리뷰] SEED: Self-Evolving On-Policy Distillation for Agentic Reinforcement Learning
Review 의 다른글
- 이전글 [논문리뷰] Seeing Isn't Knowing: Do VLMs Know When Not to Answer Spatial Questions (and Why)?
- 현재글 : [논문리뷰] SoundnessBench: Can Your AI Scientist Really Tell Good Research Ideas from Bad Ones?
- 다음글 [논문리뷰] SwanVoice: Expressive Long-Form Zero-Shot Speech Synthesis for Both Monologue and Dialogue
댓글