[논문리뷰] RoboStressBench: Benchmarking VLM Robustness to Physical Visual Stress in Embodied Scenes
링크: 논문 PDF로 바로 열기
메타데이터
저자: Leyi Wu, Yifan Zhao, Jinjie Zhang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Physical Visual Stress: 실제 환경에서 물리적 장면 형성 과정(scene formation)으로 인해 발생하는 시각적 저하 현상으로, 작업과 관련된 정보가 왜곡되거나 가려지는 현상을 지칭합니다.
- Inverse Graphics Perspective: 이미지를 형성하는 물리적 요소(물질, 조명, 관점, 기하학)를 역으로 추적하여 시각적 인식을 분석하는 프레임워크입니다.
- StressDART: 테스트 시점(test-time)에서 시각적 스트레스를 탐지하고, 대상에 맞는 정교한 시각적 편집을 통해 모델의 추론 성능을 향상시키는 에이전트 기반 솔루션입니다.
- Robustness: 다양한 환경 변화나 노이즈가 존재하는 물리적 시나리오에서도 VLM이 일관되게 높은 성능을 유지하는 능력을 의미합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 VLM 벤치마크가 현실의 물리적 환경에서 발생하는 다양한 시각적 스트레스를 제대로 반영하지 못한다는 점을 해결하고자 합니다. 기존 연구들은 단순한 디지털 노이즈(pixelation, noise 등)에만 집중하거나 일반적인 능력만을 평가하여, 실제 Embodied AI 시스템이 직면하는 복잡한 시각적 도전 과제를 식별하는 데 한계가 있습니다 [Figure 2]. 따라서 저자들은 물리적 장면 형성 과정에 근거한 체계적이고 해석 가능한 Robustness 평가 방식의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 RoboStressBench를 제안하며, 이미지 형성 과정을 I=ℱ(M, V, L, G)로 정의하고 스트레스를 Material, Viewpoint, Lighting, Geometry의 4가지 차원으로 분류하였습니다 [Figure 1]. 이를 위해 약 7.2K 규모의 데이터셋을 필터링, 합성, 실측 데이터를 통해 구축하였습니다 [Figure 5]. 평가 결과, 최고 성능 모델조차도 물리적 시각 스트레스 환경에서는 성능이 상당히 저하되는 것으로 나타났으며, 단순히 모델의 규모(Scaling)를 키우는 것만으로는 특정 스트레스 요인에 취약한 근본적인 문제를 해결할 수 없음을 확인했습니다 [Table 2]. 특히, Geometry 스트레스는 위치 추정(Grounding) 작업에, Lighting 스트레스는 상태 이해(State Understanding) 작업에 더 치명적인 영향을 미치는 등 작업별로 민감도가 다름을 입증했습니다 [Figure 8]. 최종적으로 제안된 StressDART를 통해 모델 파라미터 업데이트 없이도 테스트 시점의 시각적 교정만으로 43.2%에서 49.0%로 정량적 성능 향상을 도출하였습니다 [Table 3].
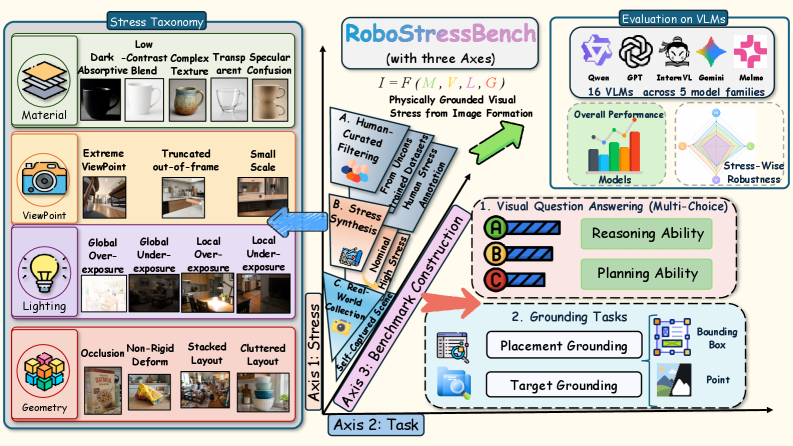
Figure 1 — RoboStressBench 전체 개요
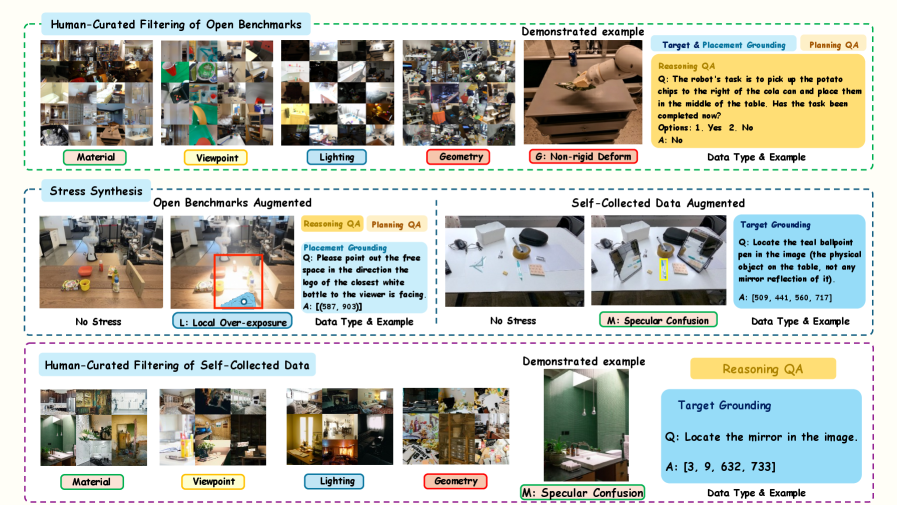
Figure 5 — 스트레스 분류 및 데이터셋 구축 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Embodied AI 환경에서 VLM의 실질적인 Robustness를 진단하기 위한 물리적 기반의 프레임워크인 RoboStressBench를 확립하였습니다. 연구 결과는 범용 VLM의 성능이 실제 물리적 장면의 복잡성을 해결하기에는 여전히 불충분함을 시사하며, 단순한 모델 크기 확대보다는 스트레스 요인을 명확히 진단하고 대응하는 에이전트 설계의 중요성을 강조합니다. 이 연구는 신뢰할 수 있는 Embodied AI 시스템 개발을 위한 새로운 평가 기준과 기술적 방향성을 제시한다는 점에서 학계 및 산업계에 중요한 기여를 합니다.
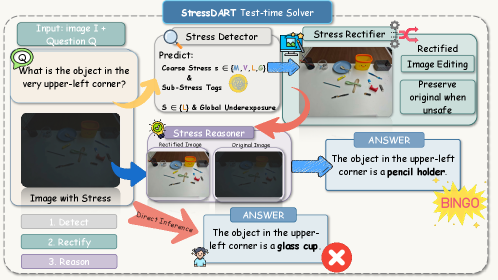
Figure 6 — StressDART 아키텍처
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LEGO-Eval: Towards Fine-Grained Evaluation on Synthesizing 3D Embodied Environments with Tool Augmentation
- [논문리뷰] DataComp-VLM: Improved Open Datasets for Vision-Language Models
- [논문리뷰] AnyGroundBench: A Specialized-Domain Benchmark for Video Grounding in Vision-Language Models
- [논문리뷰] AGVBench: A Reliability-Oriented Benchmark of Data Augmentation for Vein Recognition
- [논문리뷰] EBench: Elemental Diagnosis of Generalist Mobile Manipulation Policies
Review 의 다른글
- 이전글 [논문리뷰] RoboSemanticBench: Diagnosing Semantic Grounding in Action Prediction for VLA Models
- 현재글 : [논문리뷰] RoboStressBench: Benchmarking VLM Robustness to Physical Visual Stress in Embodied Scenes
- 다음글 [논문리뷰] SOCO: Benchmarking Semantic Object Correspondence in Vision Foundation Models
댓글