[논문리뷰] EBench: Elemental Diagnosis of Generalist Mobile Manipulation Policies
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ning Gao, Jinliang Zheng, Xing Gao, Haoxiang Ma, Hanqing Wang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- EBench: 다양한
Mobile Manipulation과제를Capability와Generalization차원으로 상세히 분석할 수 있도록 설계된 시뮬레이션 벤치마크입니다. - VLA (Vision-Language-Action) Models: 시각적 입력과 자연어 명령을 처리하여 로봇의 행동(Action)을 생성하는 범용 인공지능 모델입니다.
- Capability Profiling: 모델의 단일 성공률(Success Rate) 수치 뒤에 숨겨진 세부 역량(조작 모드, 정밀도, 기술 유형 등)을 분석하여 모델의 강점과 약점을 파악하는 진단 방식입니다.
- Generalization Dimensions: 모델의 강건성을 평가하기 위해 배경, 객체, 지시어, 혼합(Mix) 등 4가지 제어된 환경 변화를 통해 분포 외(Out-of-Distribution) 성능을 측정하는 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 로봇 조작 벤치마크들이 단일 성공률(Success Rate) 스칼라 값에 의존하여 모델의 진정한 역량을 가리고 있다는 점을 해결하고자 합니다. 현재의 Generalist Manipulation 모델들은 유사한 성공률을 보고하지만, 실제 배포 시 성능이 크게 달라지는 구조적 한계를 가지고 있습니다. 기존 연구들은 과제나 환경의 범위를 제한하거나, 세부적인 역량 분석을 위한 체계적인 분류법이 부족하다는 단점이 있습니다. 따라서 연구자들은 장기 호흡(Long-horizon), 정교한 조작(Dexterous-and-precise), 이동형 조작(Mobile)을 포괄하면서도 다각적인 분석이 가능한 진단 프레임워크인 EBench를 제안합니다 [Figure 1].

Figure 1 — EBench 벤치마크 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 EBench를 통해 26개의 다양한 조작 과제를 5가지 역량 축(Scene, Atomic Skill, Range, Precision, Operating Mode)과 4가지 일반화 축으로 분류하여 체계적으로 평가합니다 [Figure 2]. 데이터 합성을 위해 정밀한 과제는 인간의 Teleoperation을, 이동 및 장기 과제는 Key-frame 방식과 cuRobo 모션 플래너를 결합한 하이브리드 파이프라인을 구축하였습니다. 실험 결과, π 0.5 모델이 29.5%의 가장 높은 성공률을 기록했으며, InternVLA-A1 모델은 이동 조작에는 강하지만 정교한 조작에서는 큰 성능 저하를 보였습니다 [Table 2]. 특히, π 0.5는 학습-평가 분포 유지율(Retention)에서 가장 우수한 성적을 거두어 분포 변화에 대한 높은 강건성을 입증하였습니다 [Figure 3]. 또한, 사전 학습(Pretraining) 효과를 측정한 결과, EBench는 기존 벤치마크들과 달리 사전 학습된 모델과 초기화 모델 간의 성능 격차를 명확하게 드러내는 유일한 벤치마크임이 확인되었습니다 [Table 3].
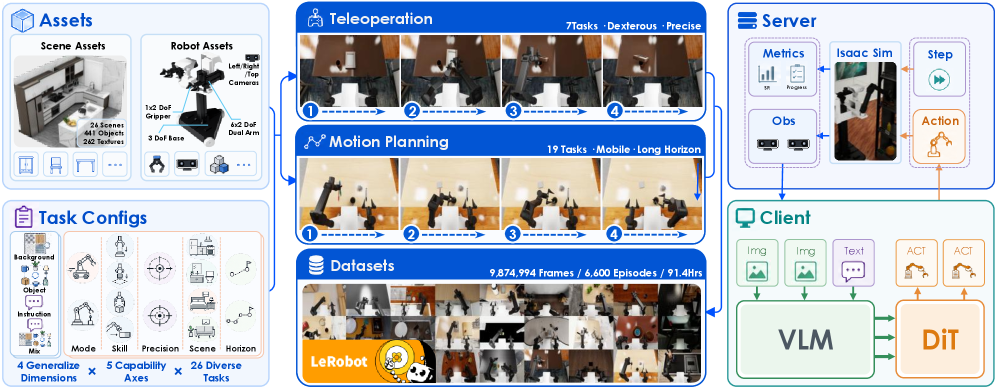
Figure 2 — EBench 데이터 합성 및 평가 파이프라인
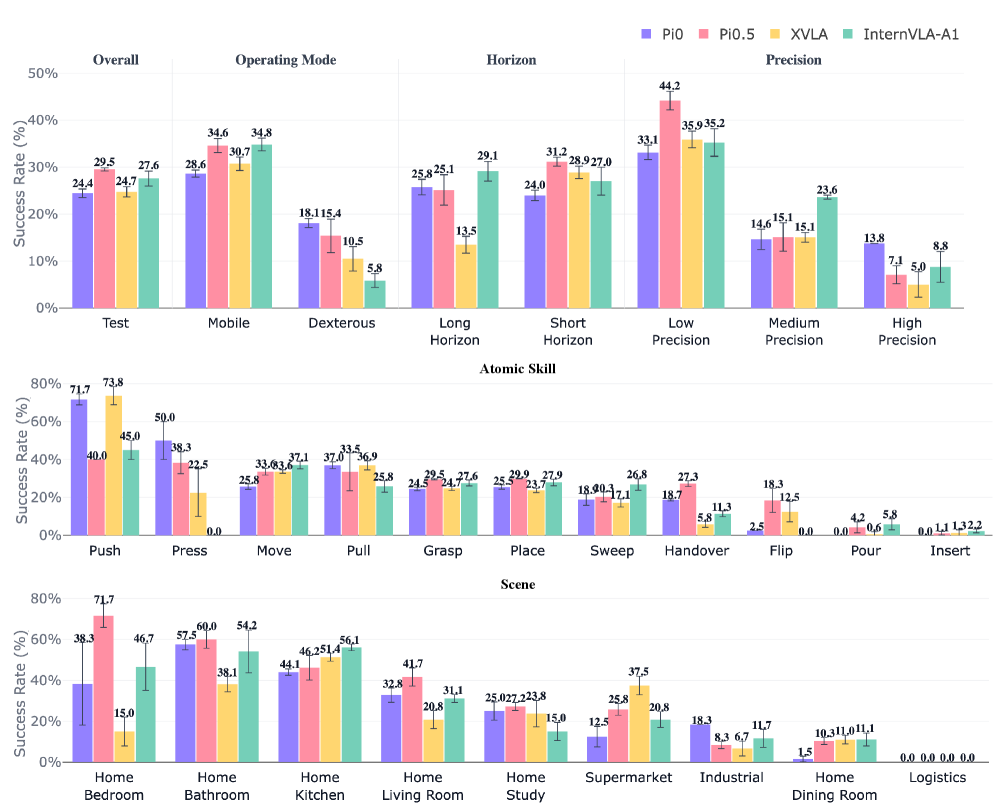
Figure 3 — 5가지 축에 따른 모델 역량 분석
4. Conclusion & Impact (결론 및 시사점)
본 연구는 범용 로봇 조작 모델의 역량을 다각도로 진단하는 EBench 프레임워크를 제시하며, 모델 선택 시 성공률 외에도 세부 역량 프로파일 분석의 중요성을 강조합니다. 이 연구는 모델의 강점과 약점을 구조적으로 파악하게 함으로써, 향후 Generalist Policy의 반복적 개발과 알고리즘 개선 방향을 제시합니다. EBench는 산업계와 학계가 더 강건한 Embodied AI를 개발할 수 있도록 돕는 정밀한 진단 도구로서 기능하며, 향후 로봇 조작 모델의 평가 지표 표준화에 기여할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] HumanScale: Egocentric Human Video Can Outperform Real-Robot Data for Embodied Pretraining
- [논문리뷰] WorldOlympiad: Can Your World Model Survive a Triathlon?
- [논문리뷰] OmniGameArena: A Unified UE5 Benchmark for VLM Game Agents with Improvement Dynamics
- [논문리뷰] RoboStressBench: Benchmarking VLM Robustness to Physical Visual Stress in Embodied Scenes
- [논문리뷰] MineExplorer: Evaluating Open-World Exploration of MLLM Agents in Minecraft
Review 의 다른글
- 이전글 [논문리뷰] DomainShuttle: Freeform Open Domain Subject-driven Text-to-video Generation
- 현재글 : [논문리뷰] EBench: Elemental Diagnosis of Generalist Mobile Manipulation Policies
- 다음글 [논문리뷰] IV-CoT: Implicit Visual Chain-of-Thought for Structure-Aware Text-to-Image Generation
댓글