[논문리뷰] IV-CoT: Implicit Visual Chain-of-Thought for Structure-Aware Text-to-Image Generation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zixuan Li, Haokun Lin, Yicheng Xiao, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- IV-CoT (Implicit Visual Chain-of-Thought): 명시적인 텍스트나 중간 이미지 디코딩 과정 없이, latent query 공간에서 구조적 계획(Structural Planning)과 의미론적 렌더링(Semantic Rendering)을 분리하여 수행하는 추론 프레임워크입니다.
- Structural-to-Semantic Query Cascade: MLLM의 causal self-attention을 활용하여 구조적 쿼리(
Structural Queries)를 먼저 배치하고, 이를 기반으로 의미론적 쿼리(Semantic Queries)가 생성되도록 유도하는 순차적 의존성 구조입니다. - Sketch-Supervised Structural Constraint: 학습 과정에서만 사용되는
PiDiNet기반의 스케치 감독(Supervision)을 통해, 구조적 쿼리가 객체의 윤곽, 배치, 형태 정보를 인코딩하도록 강제하는 학습 기법입니다. - MLLM-DiT (Multimodal Large Language Model - Diffusion Transformer): 텍스트 프롬프트를 입력받아 연속적인 비주얼 쿼리(Visual Queries)를 생성하는 MLLM과, 해당 쿼리를 컨디셔닝(Conditioning)으로 사용하여 이미지를 생성하는 DiT의 통합 모델 구조입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 통합형 MLLM 기반 이미지 생성 모델들이 복잡한 구조적 요구사항(객체 수, 공간적 관계, 속성 결합 등)을 따르는 데 어려움을 겪는 구조적 불투명성 문제를 해결하고자 합니다. 기존 모델들은 장면 구조와 외형(Appearance) 정보를 단일한 컨디셔닝 스트림에 혼합(Entangled)하여 처리하므로, 복잡한 프롬프트에서 객체 위치 오류나 속성 누락을 빈번하게 발생시킵니다 [Figure 1]. 또한, 이를 해결하기 위한 기존의 Explicit CoT 방법론들은 추가적인 텍스트 생성 단계나 중간 이미지 디코딩 과정을 요구하여 추론 효율성을 저하시키는 한계가 있습니다. 이에 저자들은 명시적인 중간 디코딩 없이 latent 공간에서 구조적 추론을 내재화(Internalize)하는 새로운 프레임워크의 필요성을 제기합니다 [Figure 1].
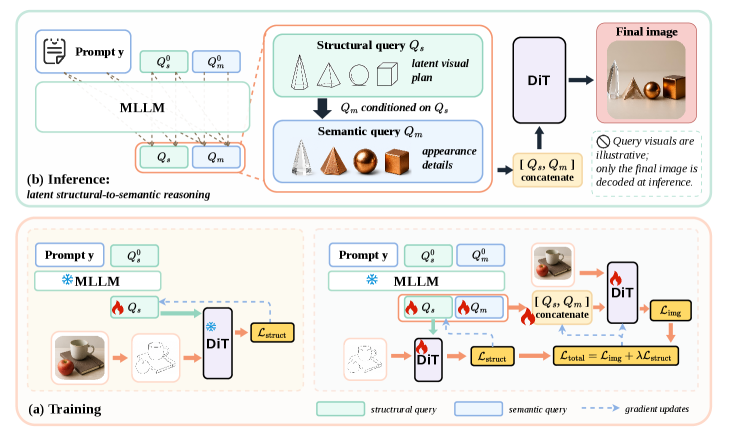
Figure 1 — 기존 CoT와 IV-CoT의 추론 패러다임 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Implicit Visual Chain-of-Thought(IV-CoT)를 제안하여, 구조적 계획과 의미론적 렌더링을 ordered dependency로 분리함으로써 구조 인식 성능을 극대화합니다 [Figure 2]. 제안 모델은 학습 단계에서 스케치 기반의 구조적 제약(Structural Constraint)을 통해 Structural Queries가 객체 레이아웃을 형성하도록 유도하고, Semantic Queries가 이를 기반으로 디테일을 생성하도록 최적화됩니다 [Figure 2]. 정량적 실험 결과, IV-CoT는 GenEval 점수를 기존 0.86에서 0.88로, T2I-CompBench 점수를 0.5448에서 0.5743으로 향상시키는 우수한 성과를 거두었습니다 [Table 1]. 특히, 추론 효율성 측면에서 기존 Explicit CoT 방법들 대비 9~15배 낮은 Latency를 달성하면서도 더 높은 compositional 생성 품질을 유지합니다 [Table 2]. 시각적 분석을 통해 Structural Queries가 객체 윤곽 및 공간적 경계에 집중적으로 관여함을 확인했으며, 쿼리 재조합 실험을 통해 구조와 외형의 독립적인 제어 가능성까지 입증했습니다 [Figure 5, Figure 6].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 latent 공간 내에서 구조적 의존성을 명시적으로 설계한 IV-CoT를 통해, 명시적 중간 단계 없이도 복잡한 구조를 완벽하게 제어할 수 있는 효율적인 이미지 생성 프레임워크를 정립했습니다. 이 연구는 기존의 복잡하고 느린 Explicit CoT 패러다임을 효율적인 latent reasoning 패러다임으로 전환할 수 있는 기술적 토대를 마련했습니다. 향후 IV-CoT는 실시간 이미지 생성 시스템이나 복잡한 레이아웃 제어가 필요한 산업적 디자인 도구 등 다양한 생성형 AI 애플리케이션에 폭넓게 적용될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Latent Reasoning with Normalizing Flows
- [논문리뷰] LatentOmni: Rethinking Omni-Modal Understanding via Unified Audio-Visual Latent Reasoning
- [논문리뷰] Unlocking Complex Visual Generation via Closed-Loop Verified Reasoning
- [논문리뷰] PLUME: Latent Reasoning Based Universal Multimodal Embedding
- [논문리뷰] CoCo: Code as CoT for Text-to-Image Preview and Rare Concept Generation
Review 의 다른글
- 이전글 [논문리뷰] EBench: Elemental Diagnosis of Generalist Mobile Manipulation Policies
- 현재글 : [논문리뷰] IV-CoT: Implicit Visual Chain-of-Thought for Structure-Aware Text-to-Image Generation
- 다음글 [논문리뷰] Improved Large Language Diffusion Models
댓글