[논문리뷰] LatentOmni: Rethinking Omni-Modal Understanding via Unified Audio-Visual Latent Reasoning
링크: 논문 PDF로 바로 열기
저자: Yifan Dai, Zhenhua Wu, Bohan Zeng, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- LatentOmni: 오디오-비주얼 신호와 텍스트 추론을 결합하여 통합된 잠재 공간(Unified Latent Space)에서 추론을 수행하는 post-training 프레임워크.
- OSPE (Omni-Sync Position Embedding): temporally corresponding한 오디오와 비주얼 특징 간의 정렬을 유지하기 위해 공유 타임스탬프를 사용하는 위치 임베딩 기법.
- Explicit Text CoT: 오디오-비주얼 증거를 텍스트 토큰으로 변환하여 추론하는 기존의 데이터셋 및 방식.
- LatentOmni-Instruct-35K: 오디오-비주얼이 상호 결합된 추론 궤적(interleaved reasoning trajectories)을 포함하여 잠재 공간 추론을 감독하는 고품질 데이터셋.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 Explicit Text CoT 기반 MLLM이 고차원 오디오-비주얼 정보를 텍스트라는 좁은 병목으로 압축함에 따라, 다중 모달 간의 세밀한 시간적 정렬과 의미적 연결을 놓치는 문제를 해결하고자 한다. 기존 모델들은 텍스트 사전 학습(language priors)에 과도하게 의존하여 원본 감각 증거(sensory evidence)에 대한 주의력이 결여되는 'sensory detachment' 현상이 발생한다 [Figure 1]. 이러한 문제를 극복하기 위해 저자들은 텍스트 기반 추론의 구조적 장점은 유지하면서, 감각 데이터의 연속성을 보존하는 새로운 추론 프레임워크의 필요성을 제기한다.

Figure 1 — LatentOmni vs Explicit Text CoT 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 텍스트 생성과 연속적인 오디오-비주얼 잠재 상태(latent states)를 교차로 생성하는 LatentOmni를 제안한다 [Figure 2]. 이 모델은 <Unified_Latent> 토큰을 사용하여 디코딩 모드를 전환하며, OSPE를 도입하여 오디오와 비주얼 신호 간의 시간적 동기화를 보장한다. 또한, LatentOmni-Instruct-35K 데이터셋을 활용해 latent states를 원본 sensory features에 직접 정렬시키는 Latent Alignment Loss($\mathcal{L}{\text{latent}}$)와 시간적 일관성을 강화하는 Temporal Synchronization Objective($\mathcal{L}{\text{sync}}$)를 최적화한다 [Figure 3].
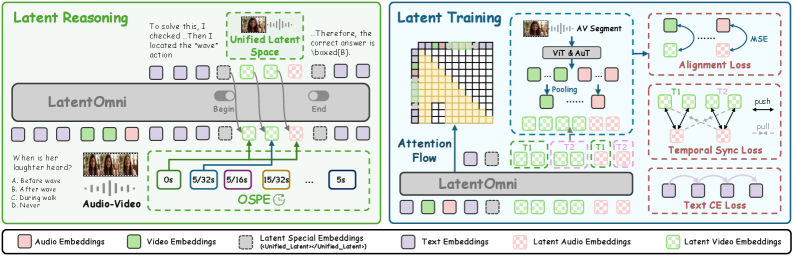
Figure 2 — LatentOmni 모델의 전체 구조
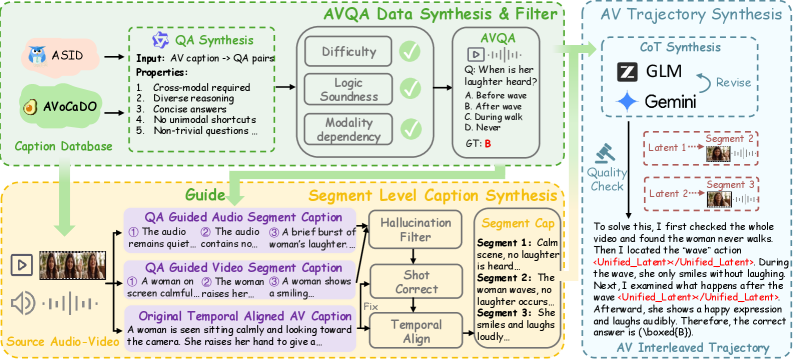
Figure 3 — 데이터셋 구축 파이프라인
실험 결과, LatentOmni는 Daily-Omni, WorldSense, OmniVideoBench, LVOmniBench 등 4개 주요 벤치마크에서 기존 오픈 소스 모델들을 압도하는 성능을 기록했다. 특히 OmniVideoBench에서 Qwen2.5-Omni-7B 베이스 모델 대비 평균 정확도에서 6.1pp의 향상을 보였으며, Explicit Text CoT 베이스라인과 비교해도 일관되게 높은 성능 우위를 점했다 [Table 2]. 아울러, 비전 전용 환경에서도 기존 잠재 추론 기법인 LVR 및 Monet를 상회하는 결과를 보여 범용적인 성능을 입증했다 [Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 잠재 공간에서의 통합 추론이 MLLM의 오디오-비주얼 이해도를 획기적으로 개선할 수 있음을 입증하였다. 텍스트 병목을 넘어 원본 감각 신호에 기반한 추론은 모델의 환각을 줄이고 신뢰성 높은 다중 모달 이해를 가능하게 한다. 제안된 LatentOmni 프레임워크와 학습 데이터셋은 향후 더 복잡하고 긴 호흡의 다중 모달 에이전트 시스템을 구축하는 데 중요한 학술적, 기술적 기반이 될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] PLUME: Latent Reasoning Based Universal Multimodal Embedding
- [논문리뷰] Audio-Visual Flamingo: Open Audio-Visual Intelligence for Long and Complex Videos
- [논문리뷰] Multimodal Continuous Reasoning via Asymmetric Mutual Variational Learning
- [논문리뷰] IV-CoT: Implicit Visual Chain-of-Thought for Structure-Aware Text-to-Image Generation
- [논문리뷰] Optical Reasoning: Rethinking Images as an Expressive Reasoning Medium Beyond Text
Review 의 다른글
- 이전글 [논문리뷰] KVServe: Service-Aware KV Cache Compression for Communication-Efficient Disaggregated LLM Serving
- 현재글 : [논문리뷰] LatentOmni: Rethinking Omni-Modal Understanding via Unified Audio-Visual Latent Reasoning
- 다음글 [논문리뷰] Lean Refactor: Multi-Objective Controllable Proof Optimization via Agentic Strategy Search
댓글