[논문리뷰] KVServe: Service-Aware KV Cache Compression for Communication-Efficient Disaggregated LLM Serving
링크: 논문 PDF로 바로 열기
저자: Zedong Liu, Xinyang Ma, Dejun Luo, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Disaggregated LLM Serving: Prefill/Decode 분리(PD separation) 또는 KV 상태 분리(KV state disaggregation)를 통해 컴퓨팅과 저장 자원을 계층적으로 분리하여 확장성과 비용 효율성을 높이는 추론 아키텍처.
- KV Cache: LLM의 autoregressive generation 과정에서 반복적으로 참조되는 Key 및 Value 상태값. 분산 환경에서는 네트워크를 통해 이동해야 하는 핵심 payload임.
- Service-Aware Adaptation: 고정된 압축 설정 대신 작업 부하(workload), 가용 대역폭(effective bandwidth), SLO, 품질 요구사항 등 동적인 서비스 컨텍스트를 고려하여 압축 전략을 선택하는 방식.
- MixHQ (Mixed-Precision Head-wise Quantization): Retrieval head와 Streaming head를 구분하여 차등적인 정밀도를 적용하고, layer/token 단위의 중요도에 따라 비트 폭을 할당하는 정교한 압축 기법.
- 3D Pareto Frontier: 품질(Accuracy), 압축률(Compression Ratio), 지연시간(Latency)이라는 세 가지 핵심 지표 간의 최적의 균형점을 나타내는 후보 집합.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 Disaggregated LLM Serving 환경에서 KV cache 통신이 전체 end-to-end 지연시간의 최대 60%를 차지하는 주요 병목 현상을 해결하고자 한다 [Figure 1]. 기존의 KV 압축 기법들은 주로 고정된 설정(static runtime configuration)을 사용하는데, 이는 실제 서비스 환경의 가변적인 대역폭과 워크로드 특성을 반영하지 못해 성능 저하를 초래하거나 심지어 'negative optimization'을 유발한다 [Figure 4]. 즉, KV 압축은 고정된 알고리즘 선택 문제가 아니라, 동적인 서비스 상태에 따라 제약 조건 내에서 최적의 전략을 선택하는 문제로 재정의되어야 한다. 이를 위해 저자들은 압축 전략의 combinatorial explosion과 실시간 적응성 문제를 해결해야 하는 도전 과제에 직면한다.
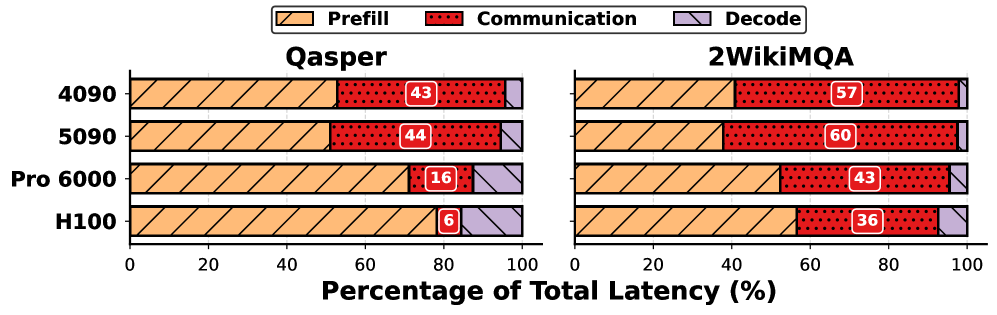
Figure 1 — PD 분리 환경의 시간 분석
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 저자들은 KV 압축을 모듈화하여 확장 가능한 전략 공간을 구성하고, Bayesian Profiling Engine과 Service-Aware Online Controller를 결합한 KVServe 프레임워크를 제안한다 [Figure 6]. Bayesian Profiling Engine은 Gaussian Process 기반의 BO(Bayesian Optimization)를 통해 기존 수천 시간의 오프라인 탐색 비용을 20시간 내외로 약 50배 단축하며, 3D Pareto Frontier를 생성한다 [Figure 10]. Service-Aware Online Controller는 해석 가능한 지연시간 모델을 통해 대역폭 임계값 기반의 프로필 필터링을 수행하고, lightweight bandit 알고리즘을 통해 오프라인-온라인 간의 미스매치를 실시간으로 보정한다 [Figure 11]. 평가 결과, KVServe는 PD-separated serving에서 JCT 기준 최대 9.13배, KV-disaggregated serving에서 TTFT 기준 최대 32.8배의 성능 향상을 달성하였다 [Figure 12, 14]. 특히, 정적 압축 기법들이 실패하는 낮은 대역폭 구간에서도 목표 품질(97% relative accuracy)을 안정적으로 유지하며 최적의 성능을 보였다 [Table 1].
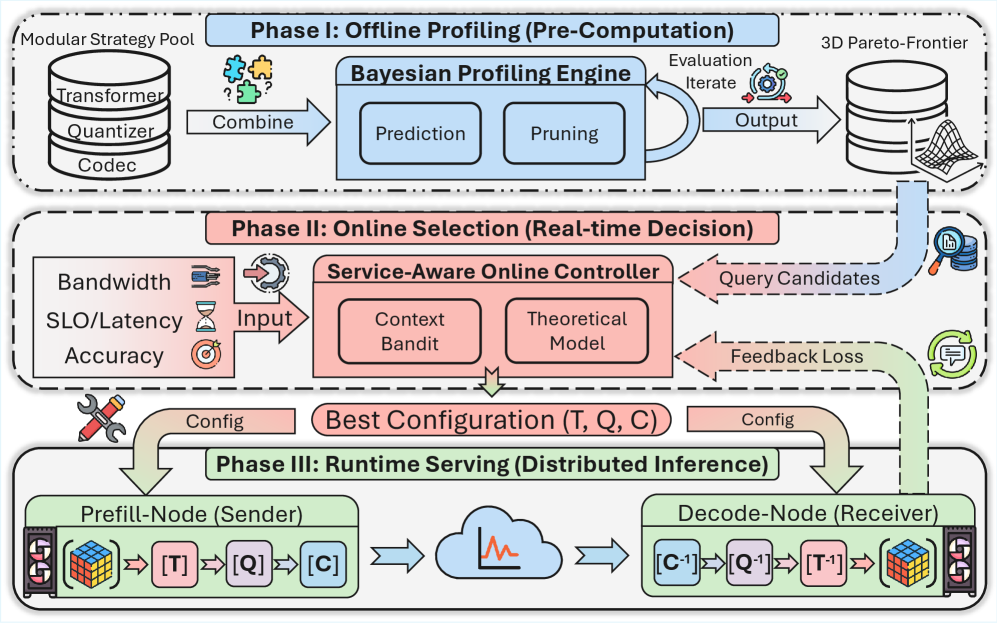
Figure 6 — KVServe 아키텍처 개요
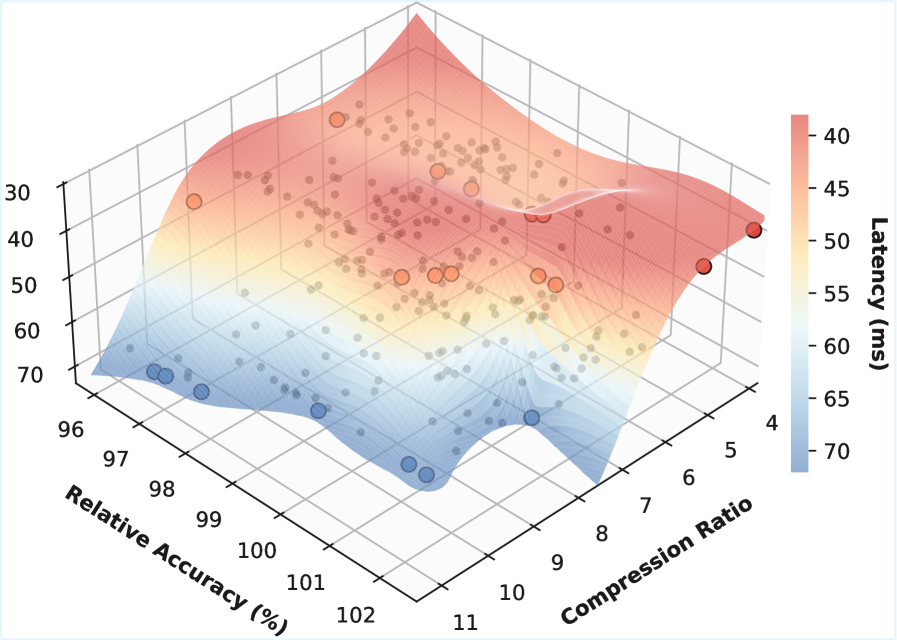
Figure 10 — 3D Pareto Frontier 최적값
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 KV cache 압축을 정적인 알고리즘 선택이 아닌, 서비스 상태 의존적인 제약 최적화 문제로 재정의하여 Disaggregated LLM Serving의 핵심 병목을 성공적으로 해결하였다. 이 연구는 단순히 KV 압축 효율을 높이는 것을 넘어, 통신 효율적인 분산 시스템 설계의 근본적인 프레임워크를 제시한다. KVServe의 서비스 인식 적응 기법은 향후 파라미터 오프로딩이나 임베딩 리트리벌 등 네트워크 기반 상태 이동이 필요한 다른 분산 컴퓨팅 영역으로도 광범위하게 확장될 수 있는 중요한 시사점을 갖는다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] The Price of Anarchy in Disaggregated Inference
- [논문리뷰] Tangram: Unlocking Non-Uniform KV Cache Compression for Efficient Multi-turn LLM Serving
- [논문리뷰] KVpop -- Key-Value Cache Compression with Predictive Online Pruning
- [논문리뷰] GORGO: Online Tuning for Cross-Region Network-Aware LLM Serving
- [논문리뷰] ReFreeKV: Towards Threshold-Free KV Cache Compression
Review 의 다른글
- 이전글 [논문리뷰] GenEvolve: Self-Evolving Image Generation Agents via Tool-Orchestrated Visual Experience Distillation
- 현재글 : [논문리뷰] KVServe: Service-Aware KV Cache Compression for Communication-Efficient Disaggregated LLM Serving
- 다음글 [논문리뷰] LatentOmni: Rethinking Omni-Modal Understanding via Unified Audio-Visual Latent Reasoning
댓글