[논문리뷰] RoboSemanticBench: Diagnosing Semantic Grounding in Action Prediction for VLA Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Bin Yu, Yao Zhang, Haishan Liu, Shijie Lian, Yuliang Wei, Xiaopeng Lin, Zhaolong Shen, Changti Wu, Ruina Hu, Bailing Wang, Cong Huang, Kai Chen
1. Key Terms & Definitions (핵심 용어 및 정의)
- VLA (Vision-Language-Action) Models: 웹 규모의 사전 학습된 시각-언어 모델(VLM)을 로봇 제어에 활용하여, 복잡한 지시어를 이해하고 로봇의 물리적 행동(Action)을 생성하도록 설계된 모델.
- Semantic Grounding: 로봇이 인간의 지시사항(Instruction) 내에 포함된 의미론적 정보를 해석하고, 이를 현재의 관찰 환경(Observation)과 연결하여 올바른 물리적 타겟을 선택하는 능력.
- TSR (Task Success Rate): 지시사항에 맞는 올바른 타겟을 선택하여 작업을 성공적으로 완료한 비율.
- GSR (Grasp Success Rate): 지시사항의 정확성과 무관하게, 로봇이 후보 타겟을 성공적으로 파지(Grasp)한 비율.
- nSG (Normalized Semantic Grounding): 파지 성공률을 고려하여, 로봇이 성공적으로 파지한 타겟이 실제 지시사항과 의미적으로 일치하는지를 측정하는 지표 (0은 무작위 선택, 1은 완벽한 선택).
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 VLA 모델들이 학습 과정에서 진정한 의미적 이해보다는 시각적 혹은 지시어-행동 간의 통계적 Shortcut에 의존하는 문제를 해결하고자 한다 [Figure 1]. 저자들은 기존의 로봇 학습 벤치마크들이 단순한 형태의 명령어를 사용하여 모델의 진정한 의미론적 추론 능력을 검증하지 못하고 있다고 지적한다. 단순히 높은 TSR만으로는 모델이 지시어를 이해했는지, 아니면 단지 데이터셋의 규칙성을 학습했는지 판별하기 어렵다. 따라서 본 연구는 Semantic Grounding이 실제 행동 예측 단계에서 작동하는지 진단하는 새로운 프레임워크를 제안한다 [Figure 2].
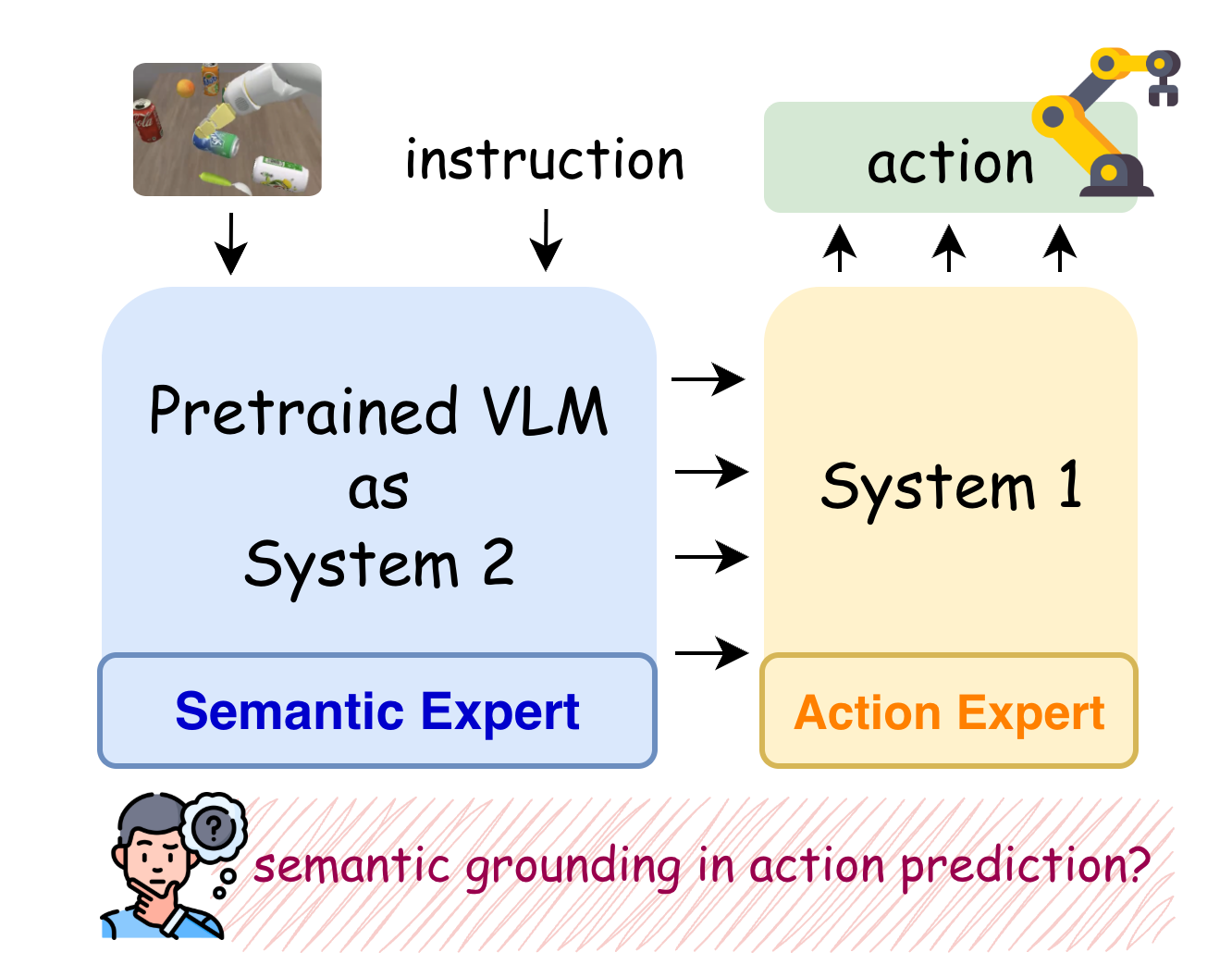
Figure 1 — Dual-system VLA 아키텍처
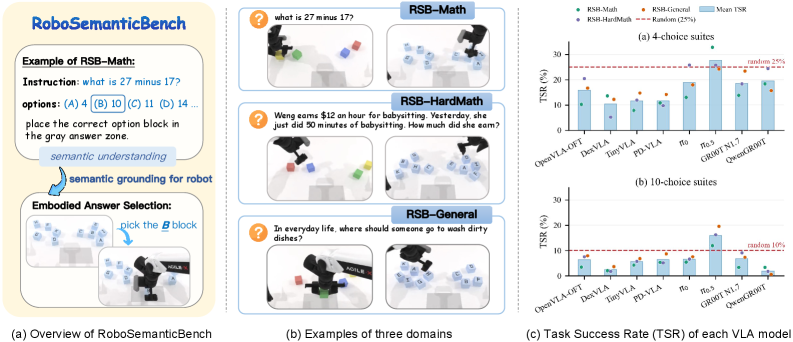
Figure 2 — RoboSemanticBench(RSB) 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들이 제안하는 RoboSemanticBench (RSB)는 수학 문제, 일반 상식, 논리적 질문을 로봇의 물리적 답안 선택 태스크로 변환하여 평가한다. 이 벤치마크는 질문의 의미가 정답 타겟을 결정하며, 동일한 파지 행위 안에서 어떤 타겟을 고르느냐에 따라 성공 여부가 갈리도록 설계되었다. 주요 실험 결과에 따르면, 대부분의 최신 VLA 모델들은 파지 능력(GSR)은 갖추었으나, 실제 정답을 선택하는 능력(TSR)은 무작위 선택 수준이거나 그 이하에 머무르는 것으로 나타났다 [Table 1]. nSG 지표를 분석했을 때, 대다수 모델이 파지 성공 후에도 의미론적으로 올바른 타겟을 고르는 데 실패하여 Semantic Grounding의 명확한 단절을 보여주었다 [Table 2]. 특히 10개 선택지 환경과 같이 탐색 공간이 넓어질수록 이러한 성능 저하는 더욱 두드러진다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 VLA 모델 내의 사전 학습된 언어 모델의 의미론적 능력이 로봇 행동 예측으로 효과적으로 전이되지 않고 있음을 실증적으로 규명했다. ReasoningVLA 및 VLA Cotraining과 같은 추가적인 시도들 또한 근본적인 문제를 해결하지 못하는 Failed Exploration임을 확인하였다 [Table 4]. 연구 결과는 향후 VLA 아키텍처 연구가 단순히 모델의 크기를 키우거나 사전 학습 데이터를 늘리는 것에 그치지 않고, 선택된 의미론적 정답을 행동 모듈로 안정적으로 전달할 수 있는 새로운 인터페이스 설계에 집중해야 함을 시사한다.
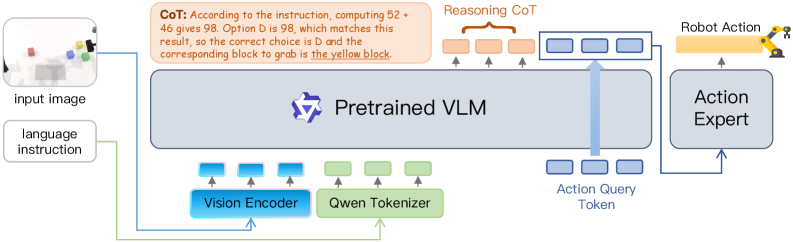
Figure 4 — ReasoningVLA 프레임워크
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Learning to Move Before Learning to Do: Task-Agnostic pretraining for VLAs
- [논문리뷰] ACE-Ego-0: Unifying Egocentric Human and Robotic Data for VLA Pretraining
- [논문리뷰] Hy-Embodied-0.5-VLA: From Vision-Language-Action Models to a Real-World Robot Learning Stack
- [논문리뷰] Robots Need More than VLA and World Models
- [논문리뷰] Silent Failures in Physical AI: A Literature Review of Runtime Action Authorization for Autonomous Systems
Review 의 다른글
- 이전글 [논문리뷰] Policy and World Modeling Co-Training for Language Agents
- 현재글 : [논문리뷰] RoboSemanticBench: Diagnosing Semantic Grounding in Action Prediction for VLA Models
- 다음글 [논문리뷰] RoboStressBench: Benchmarking VLM Robustness to Physical Visual Stress in Embodied Scenes
댓글