[논문리뷰] OpenWebRL: Demystifying Online Multi-turn Reinforcement Learning for Visual Web Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Rui Yang, Qianhui Wu, Yuxi Chen, Hao Bai, Wenlin Yao, Hao Cheng, Baolin Peng, Huan Zhang, Tong Zhang, Jianfeng Gao
1. Key Terms & Definitions (핵심 용어 및 정의)
- MM-GRPO (Multimodal Multi-turn GRPO): 기존의 단일 응답 RL 기법을 멀티모달 멀티턴 에이전트 환경으로 확장하여, trajectory 단위의 보상을 통해 전체 대화와 액션 시퀀스를 최적화하는 기법입니다.
- Agent Harness: live-web 환경의 노이즈(pop-ups, redirects, 동적 콘텐츠 등)를 효과적으로 제어하기 위해 구현된 fault-tolerant 브라우저 인터페이스입니다.
- Trajectory-level Judging: 개별 액션이 아닌 전체 작업(task) 수행의 최종 결과와 경로를 평가하여 보상을 할당하는 방식으로, 복잡한 웹 에이전트 작업의 성공 여부를 판단합니다.
- Warm-start (Supervised Fine-tuning): 본격적인 online RL을 시작하기 전, 제한된 수의 고품질 데모 데이터를 사용하여 정책(policy)을 초기화함으로써 효율적인 탐색 공간으로 유도하는 단계입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 시각적 웹 에이전트(visual web agents)의 학습을 위해 사용되는 기존의 supervised post-training 방식이 가진 확장성 한계와 고비용 데이터를 해결하고자 합니다. 기존 open-source 모델들은 정적인 데이터셋에 의존하며, 복잡하고 동적인 실제 웹 환경에서 충분한 범용성을 확보하지 못하는 문제가 있습니다. 또한, 강력한 성능을 가진 closed-source proprietary 시스템들은 접근이 제한되어 있어 연구 커뮤니티의 기술 공유를 저해합니다. 저자들은 이러한 격차를 줄이기 위해 live-web 환경에서 직접 상호작용하며 학습할 수 있는 온라인 강화학습 프레임워크인 OpenWebRL을 제안합니다 [Figure 1].
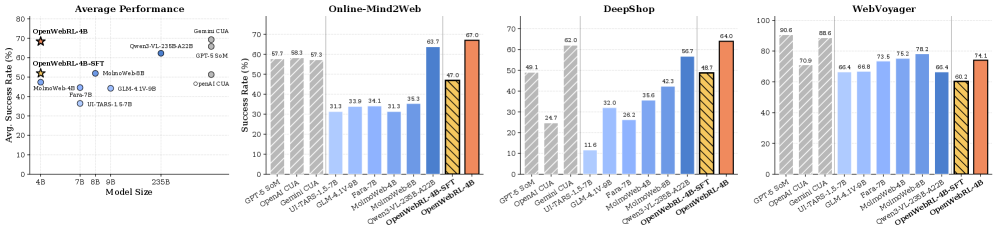
Figure 1 — 웹 에이전트 성능 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 범용 VLM을 기반으로 live-web 환경에서 온라인 학습을 수행하는 end-to-end 프레임워크인 OpenWebRL을 제안합니다. 이 방법론은 크게 0.4K trajectories를 사용한 supervised warm-start, 신뢰성 있는 browser-use를 보장하는 Agent Harness, 그리고 trajectory-level 보상을 활용한 MM-GRPO 최적화로 구성됩니다. 저자들은 특히 멀티턴 환경에서의 효율성을 위해 최근 스크린샷만을 사용하고 과거 이력을 텍스트 정보로 요약하는 문맥 관리 기법을 채택하였습니다. 실험 결과, OpenWebRL-4B 모델은 단 4B 파라미터 규모임에도 불구하고, Online-Mind2Web 벤치마크에서 67.0%, DeepShop 벤치마크에서 64.0%의 성공률을 달성했습니다 [Table 2]. 이는 이전의 오픈소스 에이전트들을 압도하며, 더 큰 규모의 proprietary 모델들과도 경쟁 가능한 성능입니다. 또한, SFT로 초기화된 모델이 그렇지 않은 모델 대비 10% 이상의 안정적인 성능 우위를 보임을 입증하였습니다 [Figure 2].
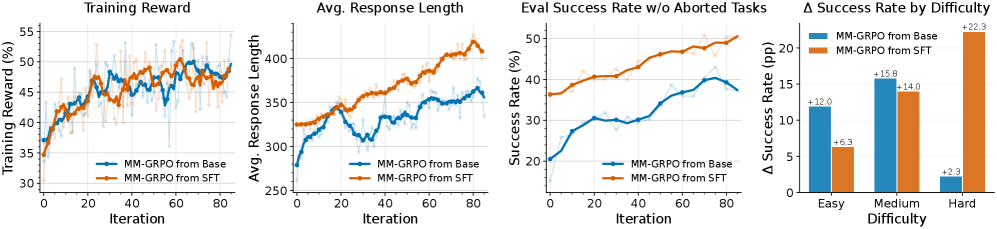
Figure 2 — MM-GRPO 학습 역학
4. Conclusion & Impact (결론 및 시사점)
OpenWebRL은 시각적 웹 에이전트의 온라인 강화를 위한 실용적이고 재현 가능한 오픈 프레임워크로서, 소형 모델(4B-8B)이 대형 proprietary 모델과 경쟁할 수 있음을 입증했습니다. 이 연구는 고비용의 정적 데이터셋 의존성에서 벗어나 실제 웹 환경과의 직접적인 상호작용을 통한 에이전트 학습의 가능성을 제시합니다. 향후 웹 에이전트 분야에서 더욱 효율적이고 확장성 있는 연구를 촉진하며, 복잡한 대리 업무를 수행하는 에이전트의 기술적 토대를 강화할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Hierarchical Advantage Weighting for Online RL Fine-Tuning of VLAs from Sparse Episode Outcomes
- [논문리뷰] Long Live The Balance: Information Bottleneck Driven Tree-based Policy Optimization
- [논문리뷰] SafeDiffusion-R1: Online Reward Steering for Safe Diffusion Post-Training
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] xHC: Expanded Hyper-Connections
Review 의 다른글
- 이전글 [논문리뷰] On the Scaling of PEFT: Towards Million Personal Models of Trillion Parameters
- 현재글 : [논문리뷰] OpenWebRL: Demystifying Online Multi-turn Reinforcement Learning for Visual Web Agents
- 다음글 [논문리뷰] PARCEL: Pool-Anchored Resampling with Conditioned Elastic Queries for Efficient Vision-Language Understanding
댓글