[논문리뷰] PARCEL: Pool-Anchored Resampling with Conditioned Elastic Queries for Efficient Vision-Language Understanding
링크: 논문 PDF로 바로 열기
메타데이터
저자: Selim Kuzucu, Alessio Tonioni, Vasile Lup, Bernt Schiele, Federico Tombari, Muhammad Ferjad Naeem
1. Key Terms & Definitions (핵심 용어 및 정의)
- LVLM (Large Vision-Language Models): 이미지나 비디오 입력을 dense token sequence로 변환하여 처리하는 멀티모달 모델로, 연산 복잡도가 시퀀스 길이에 비례함.
- Elastic Inference: 단일 모델을 학습한 후, 배포 시점에 다양한 Visual-token budget에 맞추어 유연하게 추론을 수행하는 패러다임.
- PCQR (Pool-Conditioned Query Resampling): PARCEL의 핵심 기법으로, 공간적 정보를 보존하는 spatial pool tokens와 정교한 정보를 담당하는 query tokens 간의 상호작용을 통해 효율적인 특징 추출을 수행함.
- Spectral Aliasing: Rigid spatial downsampling 시 발생하는 현상으로, 고주파수 정보가 손실되어 해상도에 민감한 작업(예: Chart reasoning)의 성능을 저하시키는 문제.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 elastic vision-token compression 방식들이 가진 근본적인 표현력 한계를 극복하고자 한다. 기존 방법론인 M3는 rigid spatial pooling을 사용하여 spectral aliasing 문제를 일으키며, MQT는 query-only resampling을 통해 dense spatial grounding 능력을 희생시킨다 [Figure 2]. 이러한 병목 현상은 고도로 압축된 visual token budget 환경에서 모델의 성능을 급격히 저하시킨다. 따라서 저자들은 spatial layout과 fine-grained detail을 동시에 보존하면서도 다양한 budget에서 작동할 수 있는 동적인 특징 추출 구조를 제안한다.
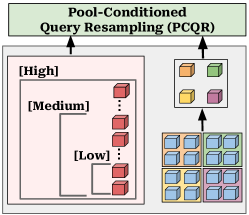
Figure 2 — PARCEL 아키텍처 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 PARCEL이라는 새로운 visual tokenization 아키텍처를 제안하여 특징 추출의 분업화를 실현한다 [Figure 4]. PARCEL은 vision transformer로부터 추출된 특징을 공간적 앵커(spatial pool tokens)로 활용하여 low-frequency layout을 확보하고, 이 앵커에 conditioned된 가변적인 query tokens를 통해 complementary한 visual detail을 추출한다. 특히 PCQR 메커니즘을 통해 쿼리 토큰이 앵커 정보를 기반으로 동작하도록 설계하여, 중복된 spatial mapping을 피하고 효율적인 feature exploration을 가능하게 한다. 실험 결과, PARCEL은 27개의 벤치마크에서 M3와 MQT 대비 일관되게 높은 성능을 기록하며 Pareto frontier를 크게 개선하였다 [Figure 1]. 특히 64 tokens budget에서 MQT 대비 RefCOCO 기준 최대 +6.1 포인트의 성능 향상을 보였으며, ChartQA와 같은 resolution-sensitive 태스크에서도 탁월한 성능 우위를 점하였다 [Table 2].
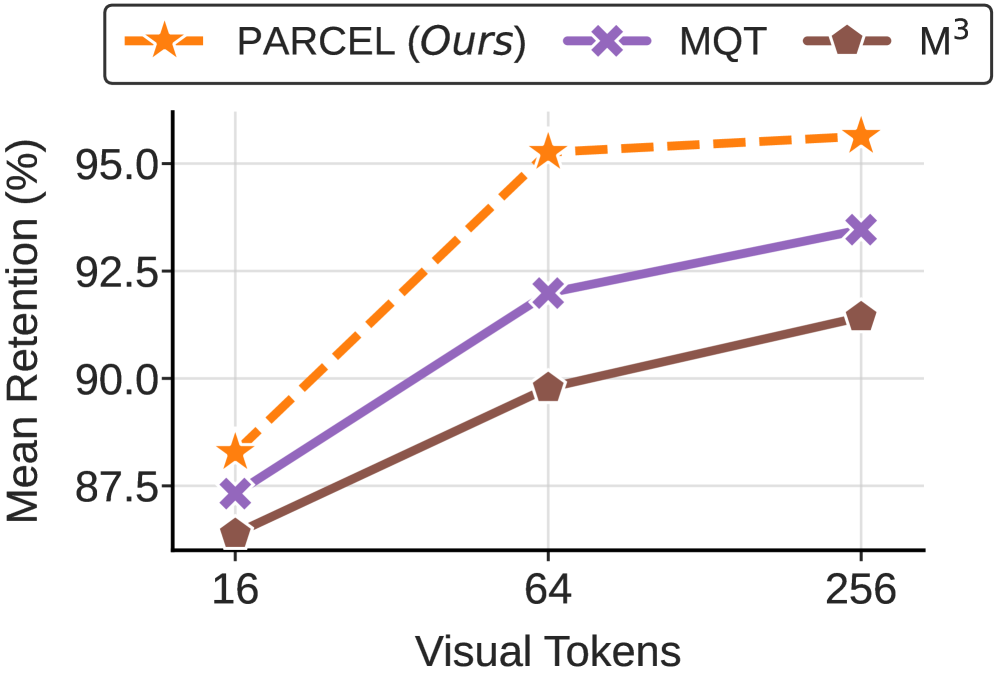
Figure 1 — 모델 성능-효율 트레이드오프
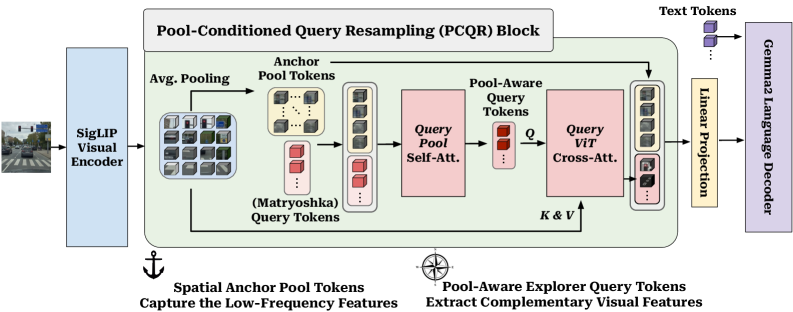
Figure 4 — PARCEL의 세부 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 PARCEL을 통해 elastic vision-token compression에서의 고질적인 표현력 문제를 성공적으로 해결하였다. PARCEL은 spatial pooling과 query resampling의 장점을 결합한 하이브리드 방식을 도입함으로써, 추론 효율성과 성능이라는 두 마리 토끼를 모두 잡는 데 기여했다. 이 연구는 자원이 제한된 엣지 디바이스부터 고성능 서버까지 다양한 환경에서 고품질의 비전-언어 이해를 가능하게 하는 "train once, deploy anywhere" 패러다임의 확장을 뒷받침한다. 향후 연구에서는 더욱 공격적인 압축 상황에서의 정보 손실 최소화 및 실시간 비디오 처리 효율 최적화가 중요할 것으로 예상된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MoME: Mixture of Matryoshka Experts for Audio-Visual Speech Recognition
- [논문리뷰] Omni-AVSR: Towards Unified Multimodal Speech Recognition with Large Language Models
- [논문리뷰] Towards Mixed-Modal Retrieval for Universal Retrieval-Augmented Generation
- [논문리뷰] MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction
- [논문리뷰] VaseMuseum: Digital Intelligent Museum for Ancient Greek Pottery
Review 의 다른글
- 이전글 [논문리뷰] OpenWebRL: Demystifying Online Multi-turn Reinforcement Learning for Visual Web Agents
- 현재글 : [논문리뷰] PARCEL: Pool-Anchored Resampling with Conditioned Elastic Queries for Efficient Vision-Language Understanding
- 다음글 [논문리뷰] Policy and World Modeling Co-Training for Language Agents
댓글