[논문리뷰] Long Live The Balance: Information Bottleneck Driven Tree-based Policy Optimization
링크: 논문 PDF로 바로 열기
Part 1: 요약 본문
저자: Hao Jiang, Shurui Li, Tianpeng Bu, Bowen Xu, Xin Liu, Qihua Chen, Hongtao Duan, Lulu Hu, Bin Yang, Minying Zhang
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- IB-Score: Information Bottleneck 이론을 기반으로, 추론 단계별 reasoning 다양성과 정답에 대한 상호 정보량(mutual information) 간의 균형을 정량화하는 신규 지표.
- IB-TPO: IB-Score를 fine-grained 최적화 목표로 통합하여 탐색과 활용의 균형을 능동적으로 조절하는 트리 기반 정책 최적화 프레임워크.
- IBTree: IB-Score를 가이드로 삼아 가장 유망하고 다양한 reasoning 경로를 선택적으로 확장하는 트리 기반 샘플링 전략.
- Eff-Rate: 0이 아닌 보상 분산을 가지는 유효한 샘플링 그룹의 비율로, 모델의 탐색 효율성을 측정하는 지표.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 온라인 RL 기반 LLM 학습 시 발생하는 탐색-활용 불균형(imbalanced exploration–exploitation trade-off) 문제를 해결하고자 합니다. 기존의 GRPO와 같은 방식은 초기 학습 단계에서 정책 엔트로피가 급격히 감소하여 모델이 너무 빨리 결정론적 상태로 수렴하는 '조기 수렴' 문제와, 이로 인한 탐색 능력 저하(Eff-Rate 감소)를 겪습니다. 반면, 엔트로피 기반의 무분별한 정규화는 학습 불안정성과 성능 저하를 초래하는 '엔트로피 폭발' 현상을 야기합니다. 이러한 한계를 극복하기 위해 저자들은 IB 이론을 도입하여 세밀하게 탐색을 제어할 새로운 메커니즘을 제안합니다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구가 제안하는 IB-TPO는 IB-Score를 RL 최적화 목표에 직접 반영하여 정책이 학습 과정 전반에 걸쳐 적응적으로 탐색과 활용을 조절하도록 설계되었습니다. 특히 IBTree 샘플링 전략은 고정된 토큰 예산 내에서 모델의 가장 다양한 reasoning 경로를 선택적으로 확장함으로써, 기존 독립적 샘플링 방식 대비 50% 더 많은 궤적(trajectories)을 생성하여 탐색 효율을 극대화합니다. 정량적 실험 결과, IB-TPO는 Qwen3-8B-Base 모델 기준 기존 GRPO 베이스라인 대비 평균 2.9%에서 3.6%의 성능 향상을 기록하였습니다. 또한 IB-TPO는 MATH-500, AIME 24/25, AMC 23/24 등 여러 벤치마크에서 TreeRL 및 TreePO와 같은 SOTA 방법론들을 상회하는 우수한 성능을 입증하였습니다. 특히 IB-Score 평가를 통해 모델이 더 높은 탐색 다양성과 안정적인 신뢰도 할당 능력을 유지하고 있음을 확인했습니다.
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 IB 이론을 온라인 RL에 성공적으로 접목하여 고질적인 탐색-활용 균형 문제를 정량적으로 해결하고 성능을 최적화하는 새로운 길을 제시하였습니다. 제안된 IB-Score와 IBTree 결합 프레임워크는 복잡한 수학적 추론 작업에서 LLM의 reasoning 능력을 향상시키는 데 있어 매우 효과적인 것으로 증명되었습니다. 향후 본 연구는 복잡한 reasoning이 요구되는 다양한 도메인으로의 확장 가능성을 열어두었으며, LLM의 안정적인 post-training 학습 체계를 구축하는 데 있어 중요한 학술적 기초를 마련하였습니다.
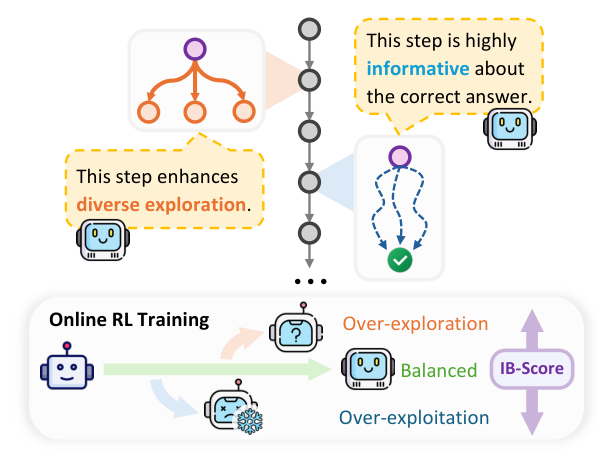
Figure 1 — 제안된 IB-Score의 핵심 개념을 설명하는 직관적인 다이어그램
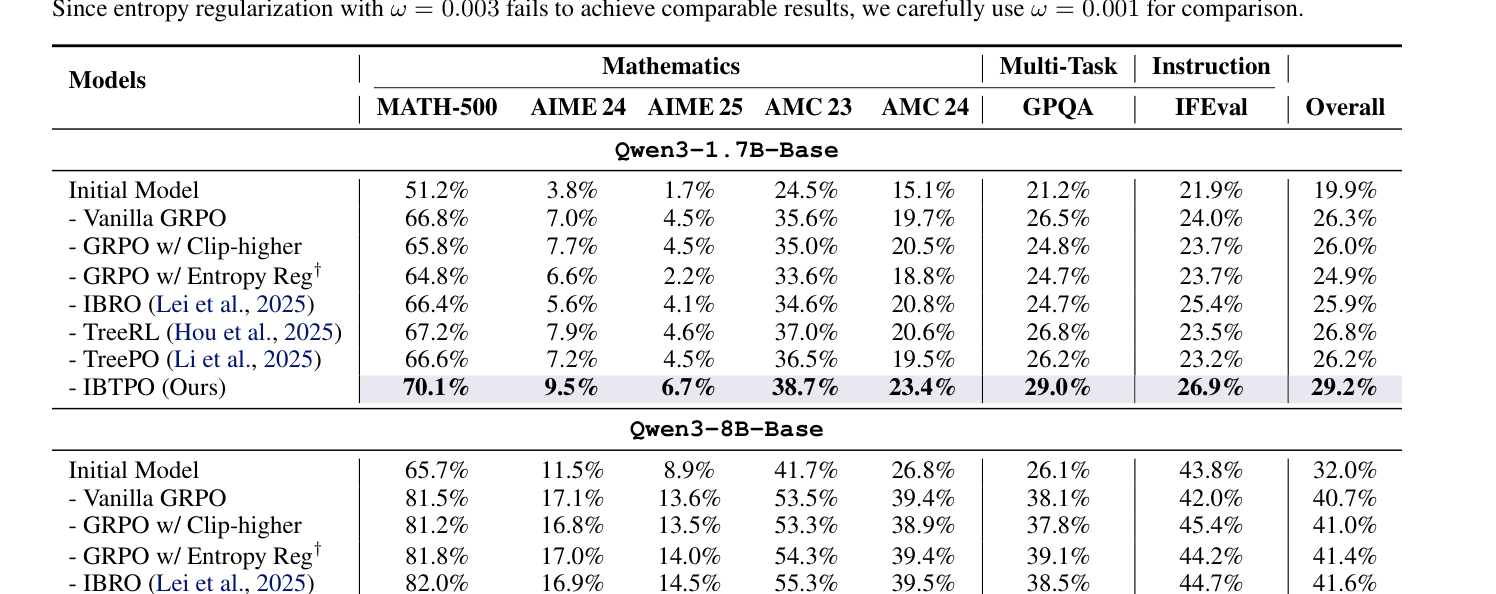
Table 1 — 다양한 수학 벤치마크 및 작업에서 제안 방법론의 성능 우위를 보여주는 핵심 결과 테이블
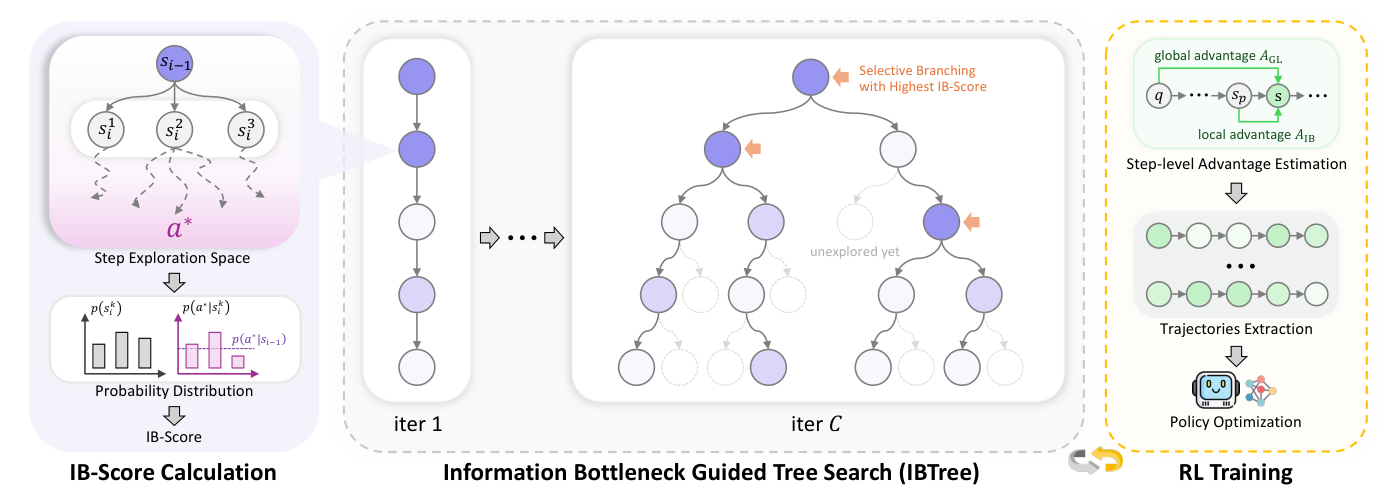
Figure 4 — IBTree를 활용한 샘플링과 RL 학습 파이프라인의 전체 구조를 보여주는 다이어그램
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Beyond Entropy: Correctness-Aware Advantage Shaping via Contrastive Policy Optimization
- [논문리뷰] Transferability for General Reasoning: An Automated Curriculum for Multi-Domain RLVR
- [논문리뷰] OneRank: Unified Transformer-Native Ranking Architecture for Multi-Task Recommendation
- [논문리뷰] Hierarchical Advantage Weighting for Online RL Fine-Tuning of VLAs from Sparse Episode Outcomes
- [논문리뷰] Cosine Misleads: Auxiliary Losses Reshape Vision Language Models, Not Their Latents
Review 의 다른글
- 이전글 [논문리뷰] LiveBrowseComp: Are Search Agents Searching, or Just Verifying What They Already Know?
- 현재글 : [논문리뷰] Long Live The Balance: Information Bottleneck Driven Tree-based Policy Optimization
- 다음글 [논문리뷰] Lost in Sampling: Assessing Lexical Reachability in LLMs via the Word Coverage Score (WCS)
댓글