[논문리뷰] Lost in Sampling: Assessing Lexical Reachability in LLMs via the Word Coverage Score (WCS)
링크: 논문 PDF로 바로 열기
저자: Samer Awad, Javier Conde, Carlos Arriaga, Tairan Fu, Javier Coronado-Blázquez, Pedro Reviriego
1. Key Terms & Definitions (핵심 용어 및 정의)
- WCS (Word Coverage Score): 특정 Decoding 파라미터 환경에서 인간 언어의 문맥적으로 적절한 단어들이 실제로 생성될 수 있는지(Reachability)를 측정하는 정량적 지표입니다.
- Forced-Path Audit: 특정 단어 시퀀스를 모델이 생성하도록 강제한 뒤, 각 토큰이 표준 샘플링 알고리즘(예: Top-pp, Top-kk)의 필터를 통과할 수 있는지 추적하는 평가 프로토콜입니다.
- Lexical Reachability (ℛ): 모델의 Latent Probability 분포 내에 존재하는 단어가 실제 샘플링 단계에서 필터링되지 않고 출력 후보군으로 살아남을 확률을 의미하는 이진 지표입니다.
- Soft Erosion: 단어가 완전히 삭제(ℛ=0)되지는 않으나, 확률 질량(Probability Mass)이 유의미하게 감소하여 실제 생성 시 선택될 빈도가 극도로 낮아지는 현상입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대 LLM이 가진 방대한 어휘력에도 불구하고, 출력 텍스트가 구조적으로 동질화되고 표현의 다양성이 저하되는 'Lexical Homogenization' 문제를 해결하고자 합니다. 기존 연구들은 주로 모델의 사전 학습 데이터나 RLHF와 같은 정렬(Alignment) 기법에 주목했으나, 저자들은 실제 생성 과정에서 사용되는 Decoding Mechanics가 인간 언어의 풍부함을 의도치 않게 삭제하는 원인임을 지적합니다. 특히, Top-pp, Top-kk와 같은 표준 샘플링 알고리즘이 로컬 일관성(Local Coherence)을 위해 'Long-tail' 토큰을 과도하게 삭제하며, 이로 인해 언어 모델의 표현 능력이 인위적으로 제한되는 문제를 규명합니다 [Figure 1].
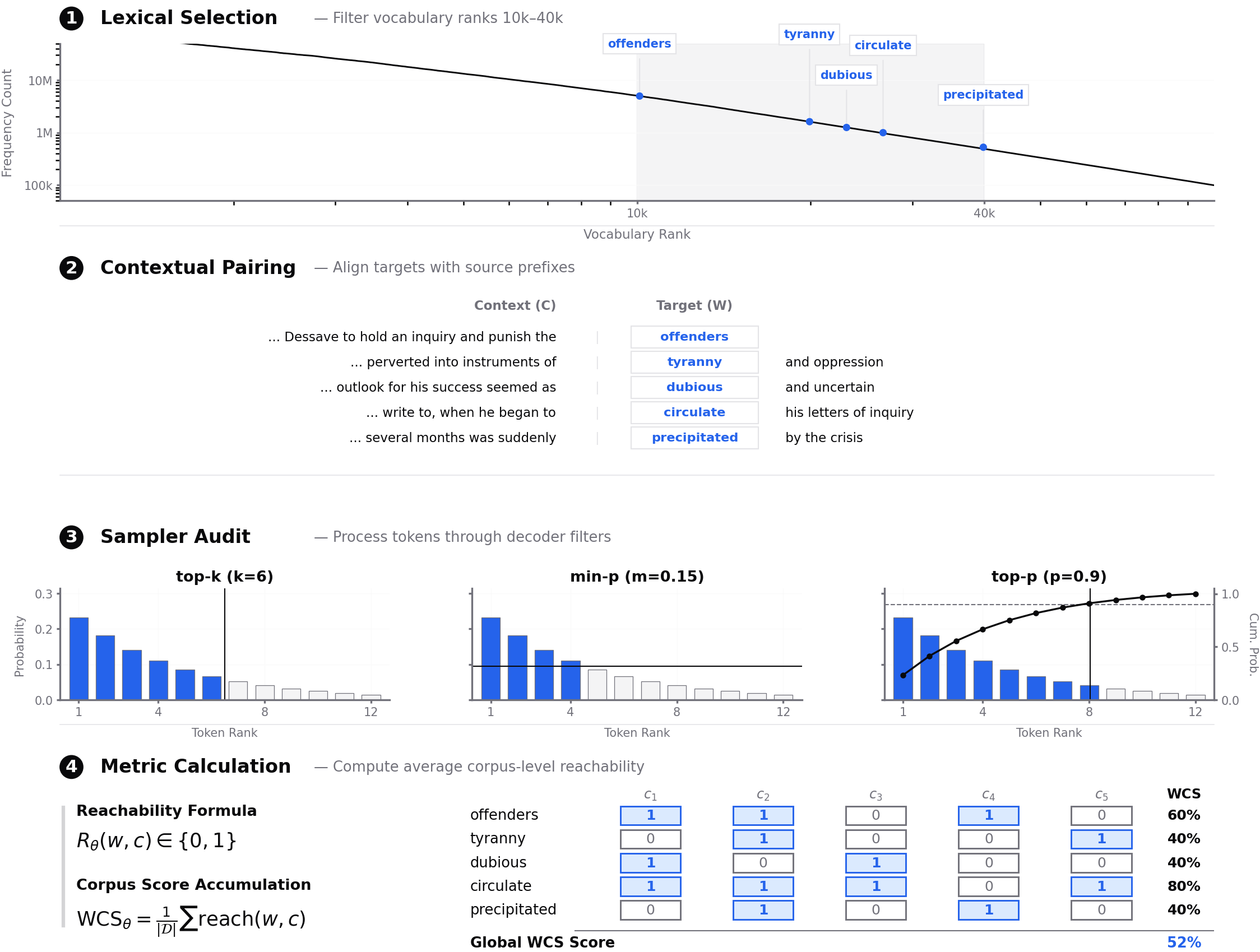
Figure 1 — WCS 계산을 위한 4단계 방법론
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 WCS를 도입하여 모델의 Latent Vocabulary가 Decoding 단계에서 얼마나 보존되는지를 체계적으로 분석합니다. 제안 방법론은 10,000에서 40,000 사이의 빈도수를 가진 'Middle-Long Tail' 단어들을 선정하고, 이를 PG-19 데이터셋의 실제 인간 저술 문맥에 배치하여 강제 경로 검사(Forced-Path Audit)를 수행하는 4단계 프로세스로 구성됩니다 [Figure 1].
실험 결과, industry-standard로 사용되는 Top-pp 및 Top-kk 샘플링 설정은 인간 어휘의 상당 부분을 삭제하는 'Unintended Censorship'을 유발함을 입증했습니다.
- 주요 모델(예: Qwen2.5-14B-Instruct, Llama-3.1-8B-Instruct)의 기본 설정값에서 약 22%에서 57%의 단어가 어떠한 문맥에서도 생성되지 못하는 'Erased' 상태가 됨을 확인했습니다 [Table 2].
- 정렬된(Instruct/It) 모델은 일반적으로 사전 학습된(Base) 모델보다 더 낮은 WCS를 보여, RLHF나 DPO와 같은 정렬 과정이 언어의 다양성을 축소하는 'Alignment Tax'를 부과하고 있음을 정량적으로 제시합니다 [Figure 2].
- Min-pp 샘플링 또한 rank-based pruning보다 나은 다양성 유지 가능성을 보이나, 전반적인 lexical decay 곡선상 여전히 심각한 어휘 손실이 발생함을 관찰했습니다 [Figure 4].
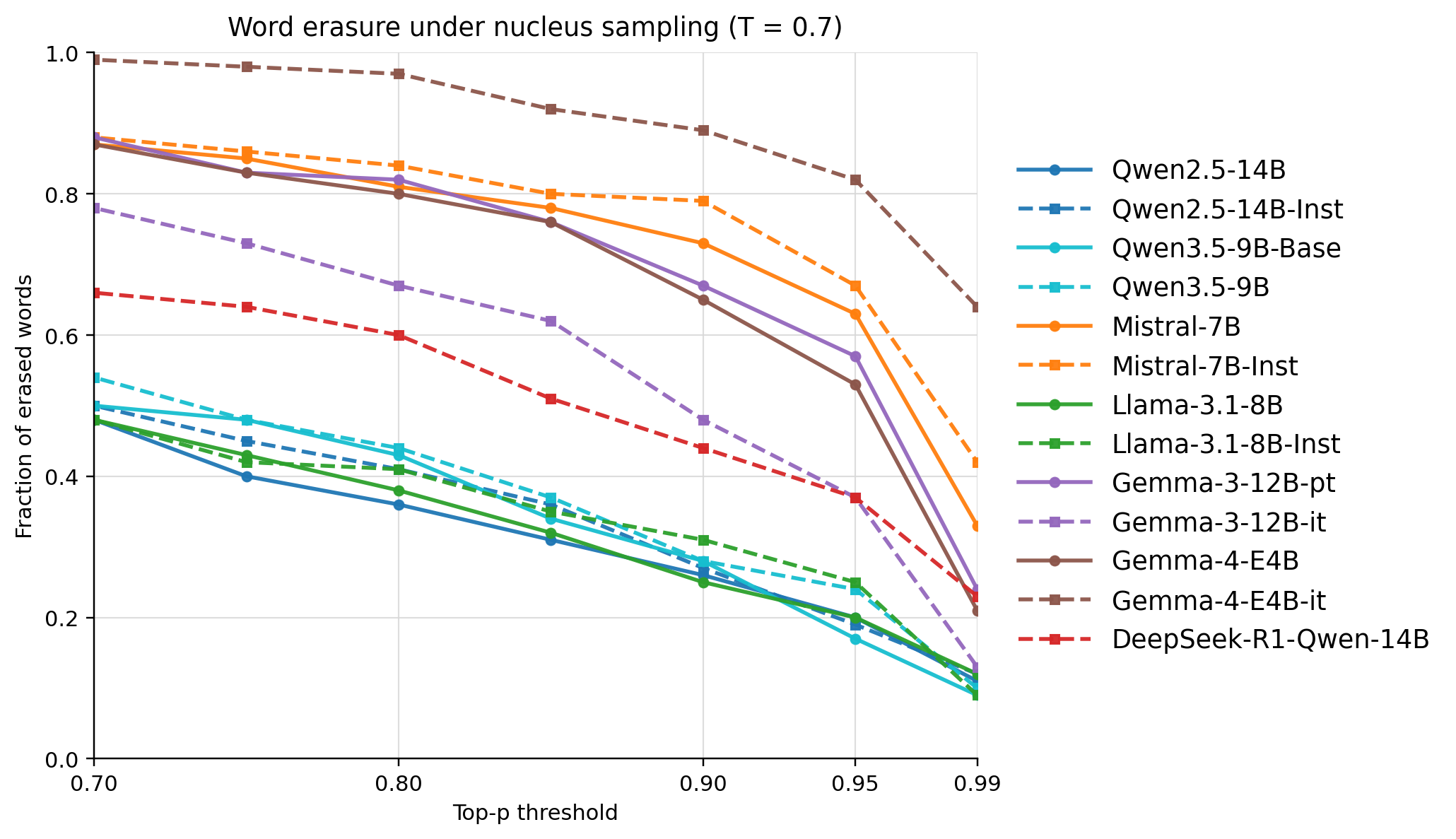
Figure 2 — Nucleus(Top-p) 샘플링 시 단어 삭제율
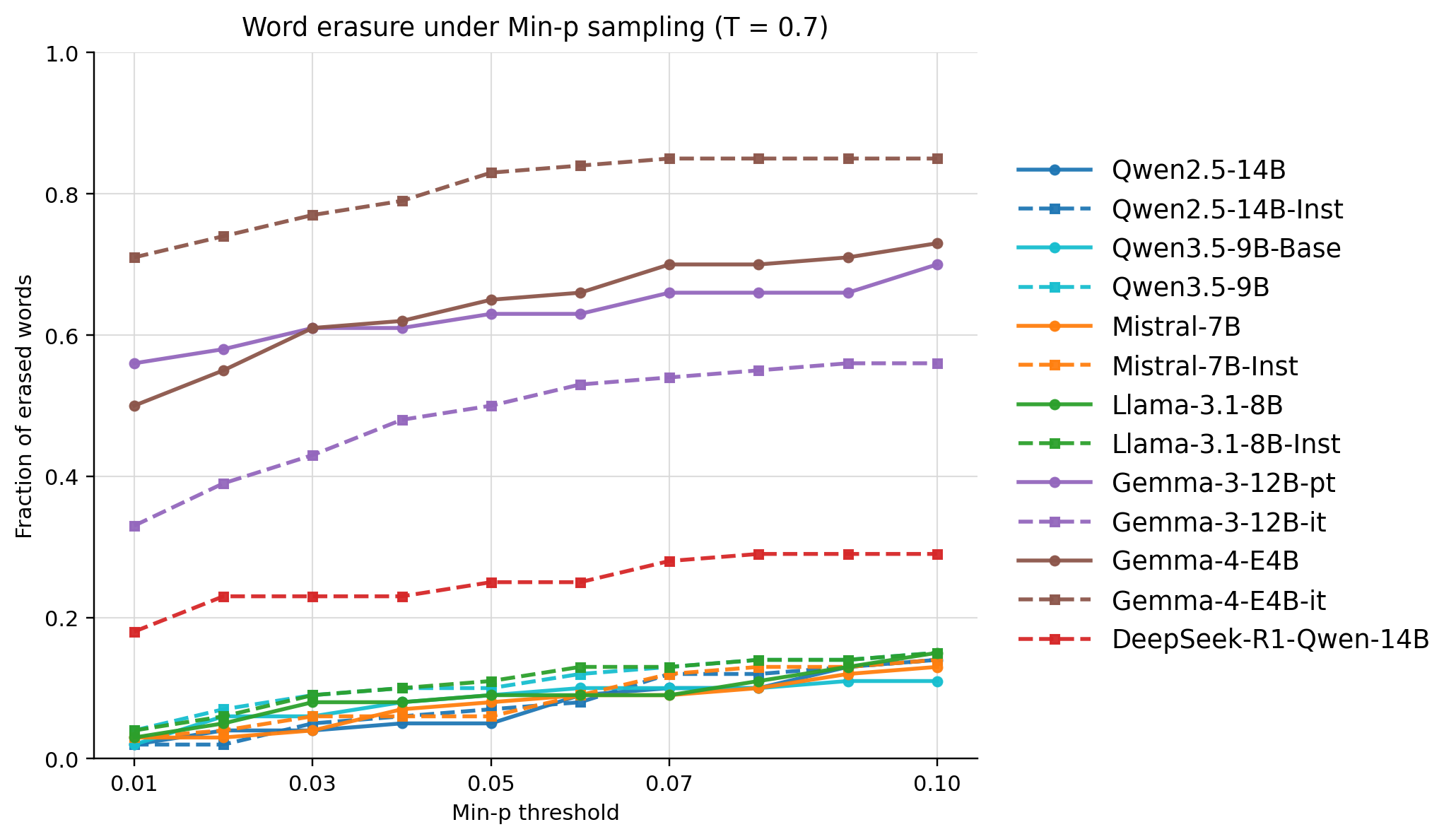
Figure 4 — Min-p 샘플링 시 단어 삭제율 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 표준 Decoding 알고리즘이 언어 모델의 창의적 표현을 체계적으로 억제하고 있음을 WCS를 통해 증명합니다. 이러한 lexical erosion은 단기적인 출력 품질 저하를 넘어, 모델이 생성한 데이터가 다시 학습 데이터로 투입되는 순환 구조 속에서 인류 언어 전체의 다양성을 위협할 수 있습니다. 저자들은 단순한 구조적 일관성 확보를 넘어, 언어 모델의 표현력 유지를 위한 Semantic-guided Decoder 개발 및 학습 목표(Loss Function) 내에 어휘 다양성 페널티를 포함하는 근본적인 패러다임 전환이 필요하다고 강조합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Epistemic Diversity and Knowledge Collapse in Large Language Models
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] RecGPT-V3 Technical Report
- [논문리뷰] Agon: Competitive Cross-Model RL with Implicit Rival Grading of Reasoning
- [논문리뷰] Spectral Rewiring for Exploration, Purification, and Model Merging
Review 의 다른글
- 이전글 [논문리뷰] Long Live The Balance: Information Bottleneck Driven Tree-based Policy Optimization
- 현재글 : [논문리뷰] Lost in Sampling: Assessing Lexical Reachability in LLMs via the Word Coverage Score (WCS)
- 다음글 [논문리뷰] MemTrace: Tracing and Attributing Errors in Large Language Model Memory Systems
댓글