[논문리뷰] OneRank: Unified Transformer-Native Ranking Architecture for Multi-Task Recommendation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jiakai Tang, Sunhao Dai, Kun Wang, Zhiluohan Guo, Yu Zhao, Cong Fu, Kangle Wu, Yabo Ni, Anxiang Zeng, Xu Chen, Jun Xu
1. Key Terms & Definitions (핵심 용어 및 정의)
- Encoder-Predictor Separation: Raw input을 처리하는 shared encoder(Transformer 등)와 이후 독립적인 task-specific head(MLP 등)를 분리하는 기존의 이분법적 구조를 지칭합니다.
- Seesaw Phenomenon: 다중 작업 학습 시 특정 작업을 위한 파라미터 업데이트가 다른 작업의 성능을 저하시키는 Gradient conflict 현상을 의미합니다.
- Strategic Gradient Detachment: Cross-task attention을 통해 forward pass에서는 지식 공유를 허용하되, backward pass에서는 파라미터 업데이트가 다른 작업으로 전파되지 않도록 차단하여 최적화 간섭을 방지하는 기법입니다.
- Candidate-Aware Contextualization: 전체 후보군(Candidate set)의 분포 정보를 situational descriptor를 통해 집계하여, 개별 항목 점수를 매길 때 문맥적 경쟁 관계를 고려하는 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 Transformer 기반 다중 작업 추천 모델들이 여전히 Encoder-Predictor 구조를 답습하고 있어, 근본적인 성능 한계와 확장성 제약에 직면해 있음을 지적합니다 [Figure 1]. 기존 구조는 shared representation이 task-agnostic한 Information Bottleneck으로 작용하여 작업별 고유 신호를 희석시키며, shared-bottom 구조 내의 Gradient 간섭으로 인해 Seesaw Phenomenon을 빈번하게 유발합니다. 또한, 문맥 중심의 Attention 기반 인코딩과 정적인(static) MLP 기반 예측 헤드 사이의 계산 Paradigm 불일치가 모델의 효율적인 엔드투엔드(End-to-End) 학습을 저해합니다. 따라서 저자들은 이러한 구조적 분리를 제거하고 다중 작업 추론을 Transformer 내부로 통합(Internalize)하는 새로운 아키텍처를 제안합니다.
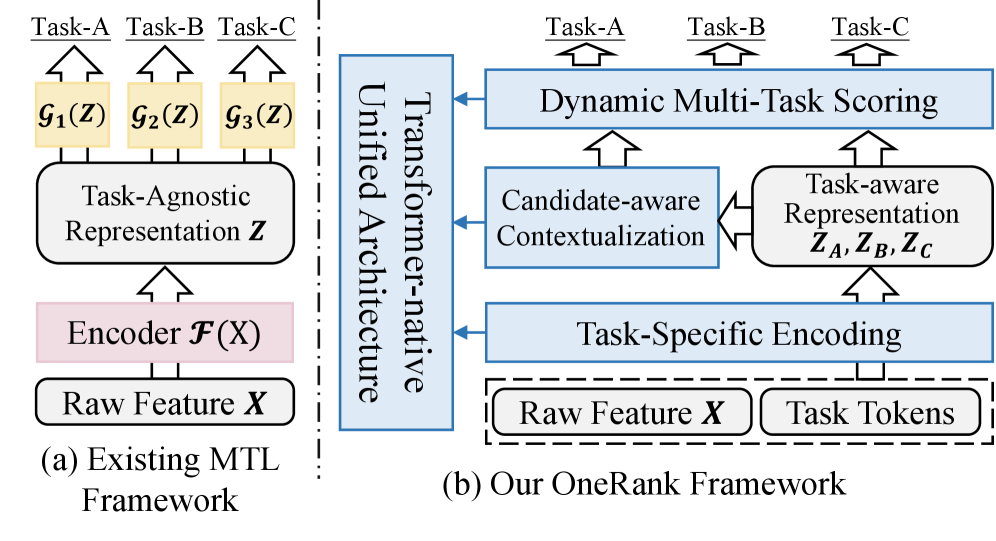
Figure 1 — 전통적 구조와 OneRank 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 OneRank 프레임워크를 제안하여, 입구(Input)부터 예측(Prediction)까지 전 과정에서 작업별 특수성(Task-specificity)과 정보 공유를 동시에 달성합니다. 먼저, Structured Tokenization을 통해 Interaction History와 Preference Anchor, Candidate-Task 그룹을 통합하며, 각 작업별 토큰에 Mutual Invisibility를 적용하여 조기 작업 특화(Early Specialization)를 구현합니다 [Figure 2]. Candidate-Aware Contextualization은 Situational Descriptors를 사용하여 전체 후보군의 문맥을 고려한 글로벌 표현을 학습하며, Strategic Gradient Detachment가 적용된 Cross-Task Relational Attention을 통해 작업 간 유익한 정보 전달은 유지하면서 최적화 시 불필요한 간섭을 제거합니다. 최종 점수는 정적인 MLP 대신 Dynamic Matching-based Scoring을 채택하여 문맥 적응형(Context-aware) 개인화 랭킹을 수행합니다. 실험 결과, OneRank는 산업용 대규모 데이터셋에서 기존 SOTA 모델인 MMoE, PLE, ResFlow 대비 유의미한 성능 향상을 보였으며, 특히 C-AUC, C-GAUC 등 주요 지표에서 더 높은 효율성과 효과성을 입증했습니다 [Table 1].
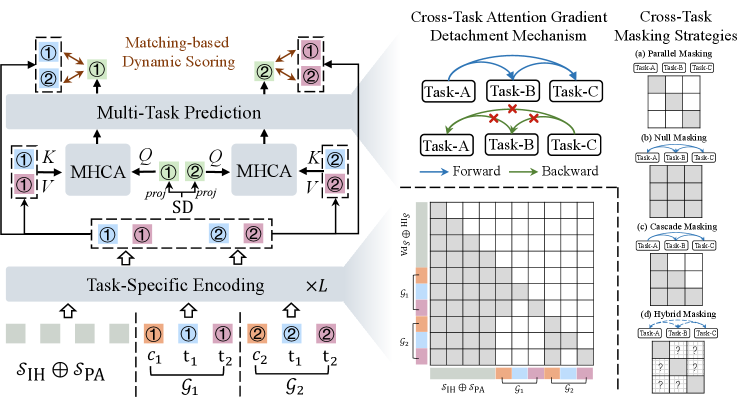
Figure 2 — OneRank 전체 아키텍처
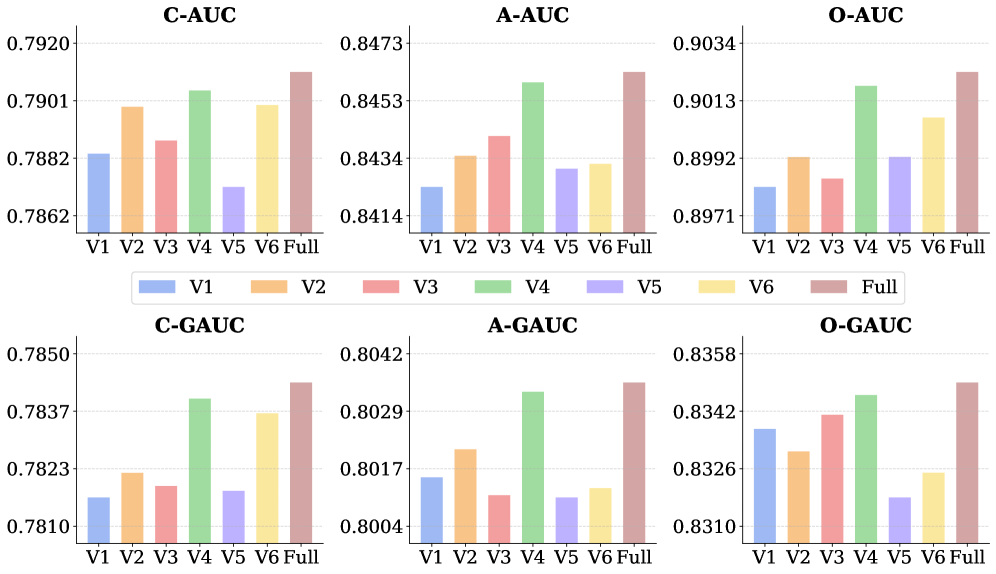
Table 1 — 모델 성능 비교 테이블
4. Conclusion & Impact (결론 및 시사점)
본 논문은 OneRank를 통해 기존 추천 시스템의 고질적인 문제인 작업 간 간섭과 정보 병목 현상을 Transformer 아키텍처의 재설계를 통해 효과적으로 해결하였습니다. 이 연구는 모델의 아키텍처적 유연성을 확보함과 동시에, 추론 시의 Computational Efficiency를 크게 향상시키는 등 산업적 실용성 측면에서 강력한 베이스라인을 제공합니다. 향후 OneRank의 다중 작업 통합 설계 방식은 대규모 추천 시스템의 확장성(Scalability) 및 성능 최적화 연구에 중요한 표준이 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Why Larger Models Learn More: Effects of Capacity, Interference, and Rare-Task Retention
- [논문리뷰] Virtual Width Networks
- [논문리뷰] Language Models are Injective and Hence Invertible
- [논문리뷰] Bag of Dims: Training-Free Mechanistic Interpretability via Dimension-Level Sign Patterns
- [논문리뷰] Variable-Width Transformers
Review 의 다른글
- 이전글 [논문리뷰] Nemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
- 현재글 : [논문리뷰] OneRank: Unified Transformer-Native Ranking Architecture for Multi-Task Recommendation
- 다음글 [논문리뷰] PermaVid: Consistent Video Generation Across Edits via Disentangled Context Memory
댓글