[논문리뷰] PermaVid: Consistent Video Generation Across Edits via Disentangled Context Memory
링크: 논문 PDF로 바로 열기
메타데이터
저자: Shuai Yang, Bingjie Gao, Ziwei Liu, Jiaqi Wang, Dahua Lin, Tong Wu
1. Key Terms & Definitions (핵심 용어 및 정의)
- Disentangled Context Memory: 시각적 맥락을 Semantic Appearance와 Geometric Structure라는 두 가지 독립적인 구성 요소로 분리하여 관리하는 메모리 설계 방식입니다.
- Edit-aware Memory Update/Retrieval: 편집 작업(Global/Local)에 따라 메모리 내용을 선택적으로 무효화하고 업데이트하며, 현재 편집 상태에 유효한 정보만을 검색하는 메커니즘입니다.
- Memory-guided Video Generation: DiT(Diffusion Transformer) 아키텍처에 메모리 컨텍스트 브랜치를 통합하여, 다중 모달(RGB 및 Depth) 레퍼런스를 기반으로 일관된 비디오를 생성하는 프레임워크입니다.
- UE-Mem: Unreal Engine 기반의 네비게이션 에이전트를 통해 구축된 대규모 비디오 데이터셋으로, 롱폼 비디오와 재방문(revisiting) 궤적을 포함하여 모델의 장기 일관성 학습을 지원합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 카메라 제어 비디오 생성에서 편집 작업(예: 스타일 변환, 객체 수정) 후 시간 및 시점 간의 일관성을 유지하는 문제를 해결합니다. 기존 메모리 기반 기법들은 Semantic Appearance와 Geometric Structure를 통합된 표현으로 저장하기 때문에, 편집이 발생하면 과거의 모든 맥락이 무효화되거나 불필요하게 폐기되는 한계가 있습니다. 이러한 정보의 결합은 특정 편집 시에도 모델이 과거의 유효한 기하학적 정보를 재사용하지 못하고 시각적 불일치나 내용 퇴보(reversion)를 겪게 합니다 [Figure 1]. 저자들은 편집에 대응하면서도 장면의 구조적 일관성을 보존하기 위한 새로운 메모리 분리 접근 방식이 필요함을 강조합니다.

Figure 1 — PermaVid 개념 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 RGB 기반 메모리(외관용)와 Depth 기반 메모리(구조용)를 분리한 Disentangled Multi-modal Context Memory를 제안하여 편집 시 외관만 갱신하고 기하학적 구조는 유지할 수 있도록 합니다 [Figure 2]. Global Edit 시에는 모든 RGB 메모리를 무효화하고 Depth 메모리를 보존하며, Local Edit 시에는 영향받는 영역의 메모리만 선택적으로 업데이트합니다. 생성 과정에서는 검색된 레퍼런스 정보를 DiT 모델에 주입하여 일관성을 확보합니다. 실험 결과, 제안 모델은 Global Edit 및 Local Edit 상황에서 기존 SOTA 모델들보다 월등한 성능을 기록했습니다. 구체적으로 Global Edits 조건에서 PSNR 및 CLIP-Vid 지표가 Baseline 대비 크게 향상되었으며, Local Edits에서도 VBench-Avg를 포함한 정량적 지표에서 일관성 및 시각적 품질 우위를 입증했습니다 [Table 1]. 특히, 복잡한 카메라 궤적과 재방문이 포함된 환경에서 기존 기법들이 시각적 아티팩트나 스타일 불일치를 보이는 것과 달리, 제안된 모델은 높은 공간적·시간적 일관성을 유지합니다 [Figure 3], [Figure 4].
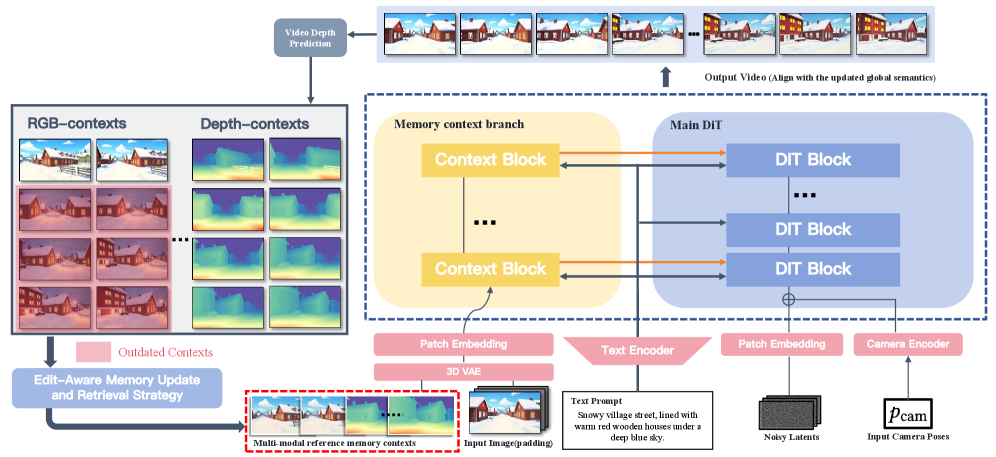
Figure 2 — PermaVid 전체 아키텍처
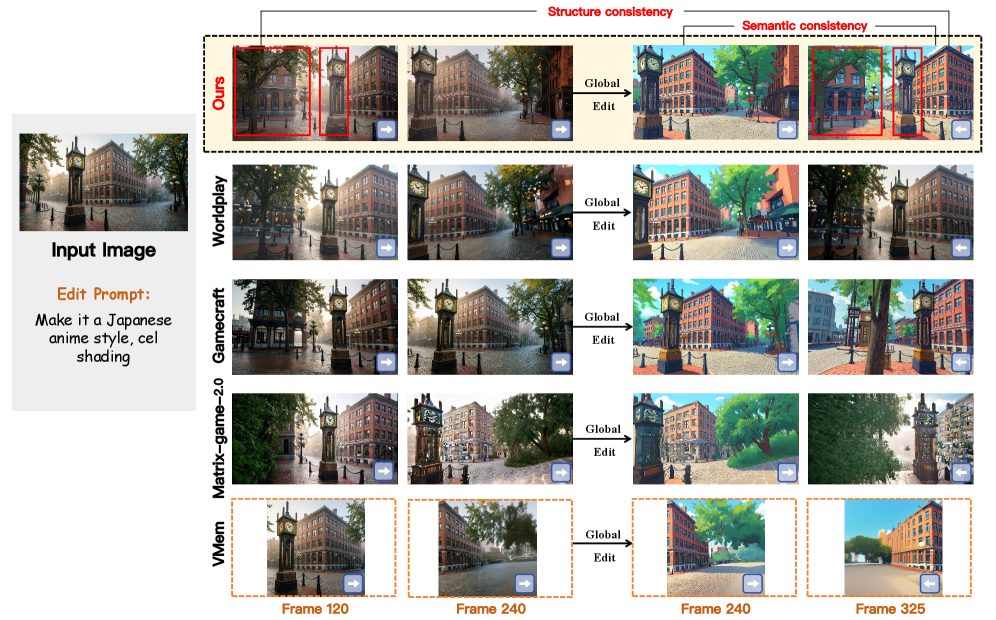
Figure 3 — Global Edit 결과 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 공간 컨텍스트를 외관과 기하 구조로 명시적으로 분리하는 PermaVid 프레임워크를 통해 장기 비디오 생성의 일관성 문제를 성공적으로 완화합니다. 이 연구는 복잡한 상호작용 및 편집이 요구되는 interactive video world model 분야에서 중요한 진전을 이루었으며, 메모리 기반 생성 기법의 유연성과 효율성을 동시에 확보했습니다. 향후 이 방법론은 보다 정교한 장면 수정과 확장된 시간적 지평을 가진 몰입형 콘텐츠 생성 기술 발전에 크게 기여할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Latent Spatial Memory for Video World Models
- [논문리뷰] Spatia: Video Generation with Updatable Spatial Memory
- [논문리뷰] LooseControlVideo: Directorial Video Control using Spatial Blocking
- [논문리뷰] Current World Models Lack a Persistent State Core
- [논문리뷰] EgoCS-400K: An Egocentric Gameplay Dataset for World Models
Review 의 다른글
- 이전글 [논문리뷰] OneRank: Unified Transformer-Native Ranking Architecture for Multi-Task Recommendation
- 현재글 : [논문리뷰] PermaVid: Consistent Video Generation Across Edits via Disentangled Context Memory
- 다음글 [논문리뷰] PhoneHarness: Harnessing Phone-Use Agents through Mixed GUI, CLI, and Tool Actions
댓글