[논문리뷰] Why Larger Models Learn More: Effects of Capacity, Interference, and Rare-Task Retention
링크: 논문 PDF로 바로 열기
저자: Jing Huang, Daniel Wurgaft, Rachit Bansal, Laura Ruis, Naomi Saphra, David Alvarez-Melis, Andrew Kyle Lampinen, Christopher Potts, Ekdeep Singh Lubana
1. Key Terms & Definitions (핵심 용어 및 정의)
- Learnable via model scaling: 특정 데이터나 훈련 시간 증가로 해결할 수 없으며, 오직 모델 파라미터 수(Capacity) 확장을 통해서만 학습 가능한 데이터 분포 영역을 의미합니다.
- Gradient Interference: 다중 작업 학습(Multi-task Learning) 시, 서로 다른 작업의 그래디언트가 충돌하여 모델 파라미터를 업데이트하는 과정에서 이전에 학습된 작업의 중요 특징(Feature)을 지우거나 덮어쓰는 현상입니다.
- Residual Signal ($\delta_{\mathsf{F}}$): 현재 모델이 설명하지 못하고 남겨둔 잔여 데이터 분포 신호를 의미하며, 이것이 낮을수록 모델이 특정 작업을 학습할 수 있는 여유 자원이 확보됨을 뜻합니다.
- Rare-Task Retention: 드물게 등장하는 작업(Rare Task)의 학습 데이터를 모델이 기억하고, 이후 해당 작업이 재등장했을 때 이전의 학습 경험을 바탕으로 학습을 계속해 나가는 능력을 의미합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 더 큰 모델(Larger Models)이 더 작은 모델이 학습하지 못하는 작업들을 어떻게 학습하는지에 대한 근본적인 메커니즘을 규명하고자 합니다. 기존 연구들은 단순한 모델 표현력(Expressivity)이나 데이터 효율성 측면에서 이를 설명하려 했으나, 본 논문은 학습 역학(Learning Dynamics)의 관점에서 데이터-모델 간 상호작용을 분석합니다. [Figure 1]에 나타난 것처럼, 모델 크기의 확장이 특정 데이터 영역을 학습 가능하게 만드는 것은 단순히 샘플 효율성의 문제가 아니라, 모델이 데이터 분포를 처리하는 방식의 근본적인 차이에서 기인합니다.
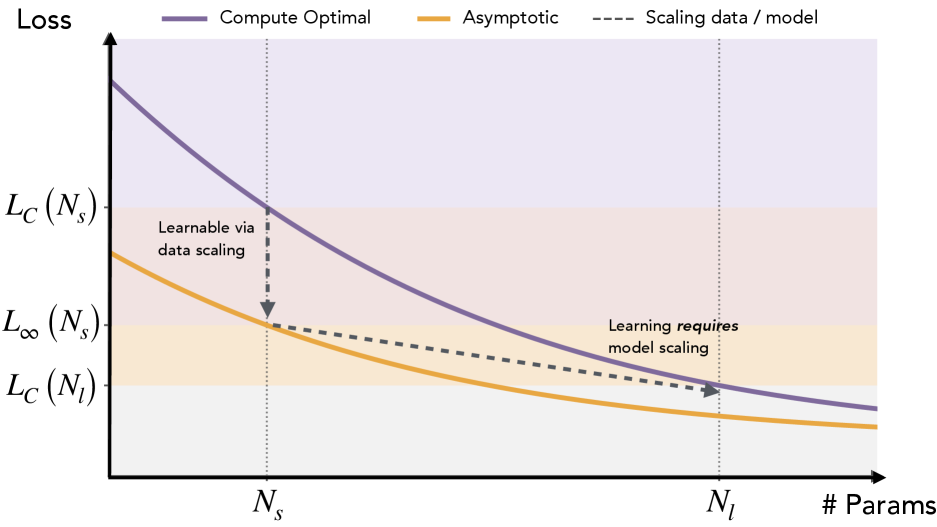
Figure 1 — 모델 크기 확장과 학습 영역 관계
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 모델의 크기가 커짐에 따라 작업 간 자원(neurons) 점유 경쟁이 줄어들며, 이로 인해 희소한 작업(Rare Tasks)의 특징을 더 잘 유지(Retention)한다는 사실을 입증합니다. 이를 위해 다중 작업 선형 회귀(Multi-task Linear Regression) 환경에서 이론적 증명을 제시하고, 실제 OLMo 프리트레이닝 파이프라인을 통해 검증하였습니다. [Figure 2]는 모델 너비(Width)가 증가할수록 희소하거나 복잡한 작업의 손실(Loss)이 감소함을 보여주며, 이는 모델이 유틸리티가 낮은(Low-utility) 특징까지 학습할 수 있는 용량을 확보함을 의미합니다. 또한, 희소 작업의 간헐적 배치(Batch) 주입 실험을 통해, 큰 모델이 작은 모델 대비 그래디언트 간섭을 덜 받아 희소 작업의 특징을 잊지 않고 축적(Accumulate)함을 확인하였습니다 [Figure 4]. 정량적으로, 큰 모델은 희소 작업 학습 시 일반 언어 모델링 그래디언트와의 간섭이 거의 없으나, 작은 모델은 희소 작업 신호가 언어 모델링 그래디언트에 의해 지속적으로 덮어쓰이는 현상을 보였습니다 [Figure 9].
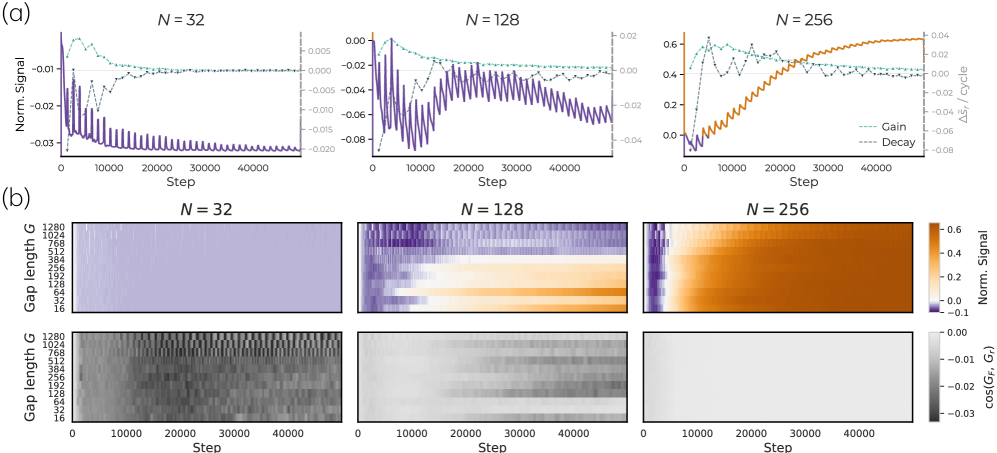
Figure 4 — 희소 작업 신호 보존 비교
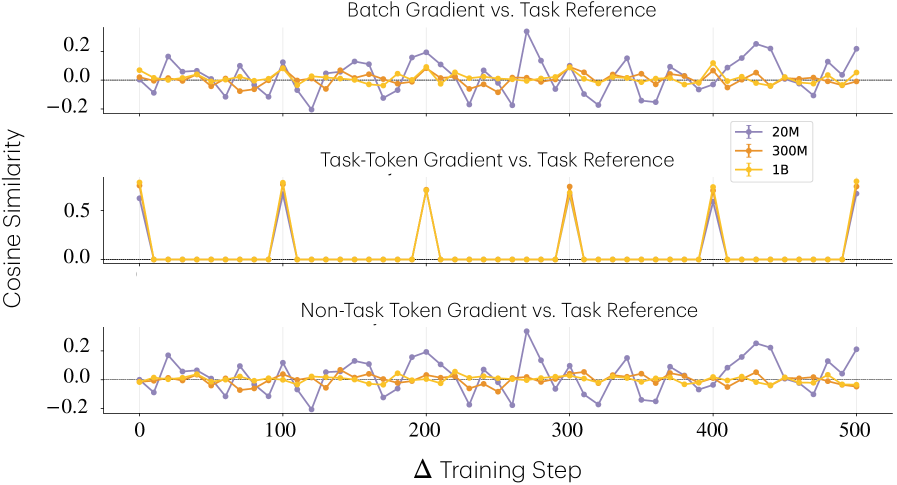
Figure 9 — 모델 크기별 그래디언트 간섭 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 더 큰 모델이 희소한 작업을 학습하는 이유가 단순히 파라미터의 양 때문이 아니라, 희소한 신호를 보존하고 이를 기반으로 추상적 일반화로 나아가는 학습 동역학적 이점 때문임을 밝혔습니다. 이 결과는 데이터 혼합물(Data Mixtures) 구성 시 작업의 빈도와 복잡성을 고려한 설계가 모델 크기만큼이나 중요할 수 있음을 시사합니다. 향후 학계와 산업계에서는 모델 크기 확장뿐만 아니라, 희소한 작업의 특징을 효율적으로 보존할 수 있는 데이터 최적화 기법 및 학습 스케줄링 전략이 필수적인 고려 사항이 될 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OneRank: Unified Transformer-Native Ranking Architecture for Multi-Task Recommendation
- [논문리뷰] Xiaomi-Robotics-1: Scaling Vision-Language-Action Models with over 100K Hours of Real-World Trajectories
- [논문리뷰] SUFLECA: Scaling Up Feature Learning for CAD-to-image Alignment
- [논문리뷰] AffectFlow-DINO: Uncertainty-Aware Multi-Task Affect Estimation via Conditional Rectified Flow
- [논문리뷰] Principled Analysis of Deep Reinforcement Learning Evaluation and Design Paradigms
Review 의 다른글
- 이전글 [논문리뷰] When Should Models Change Their Minds? Contextual Belief Management in Large Language Models
- 현재글 : [논문리뷰] Why Larger Models Learn More: Effects of Capacity, Interference, and Rare-Task Retention
- 다음글 [논문리뷰] WorldMemArena: Evaluating Multimodal Agent Memory Through Action-World Interaction
댓글