[논문리뷰] When Should Models Change Their Minds? Contextual Belief Management in Large Language Models
링크: 논문 PDF로 바로 열기
저자: Haoming Xu, Weihong Xu, Zongrui Li, Mengru Wang, Yunzhi Yao, Chiyu Wu, Jin Shang, Yu Gong, Shumin Deng
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- CBM (Contextual Belief Management): 다중 턴 상호작용 과정에서 모델이 Formal Evidence에 근거하여 Belief State를 적절히 업데이트, 유지 또는 노이즈로부터 격리하는 능력을 의미합니다.
- BeliefTrack: CBM 성능을 정량적으로 측정하기 위해 도입된 폐쇄형(Closed-world) 벤치마크로, Rule Discovery 및 Circuit Diagnosis 환경을 포함하며 기호적 검증기(Symbolic Verifier)를 통한 턴 단위 평가를 지원합니다.
- Oracle Belief State: 누적된 Formal Evidence를 바탕으로 논리적으로 도출되는 정답 Belief State입니다.
- Diagnostic Failures: CBM 성능을 평가하는 세 가지 핵심 실패 유형으로, Failed Stay(안정적 상태 유지 실패), Failed Update(수정 시 업데이트 실패), Failed Isolation(비공식 노이즈 격리 실패)을 지칭합니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 LLM이 장기적인 상호작용 속에서 누적되는 정보들 중 무엇을 믿고, 무엇을 수정하며, 무엇을 무시해야 하는지에 대한 문제(CBM)를 해결하고자 합니다. 기존의 LLM은 문맥 내에서 제공되는 형식적 증거를 따르기보다 사전 학습된 파라메트릭 지식이나 문맥상의 노이즈에 과도하게 의존하는 경향이 있습니다 [Figure 1]. 특히, 기존의 평가는 정량적 정밀도가 낮고 실패의 원인을 진단하기 어렵다는 한계가 있습니다. 이를 해결하기 위해 저자들은 기호적 검증이 가능한 BeliefTrack 프레임워크를 제안하여 모델의 추론 오류를 구체적인 유형별로 분리하고 측정합니다 [Figure 3].
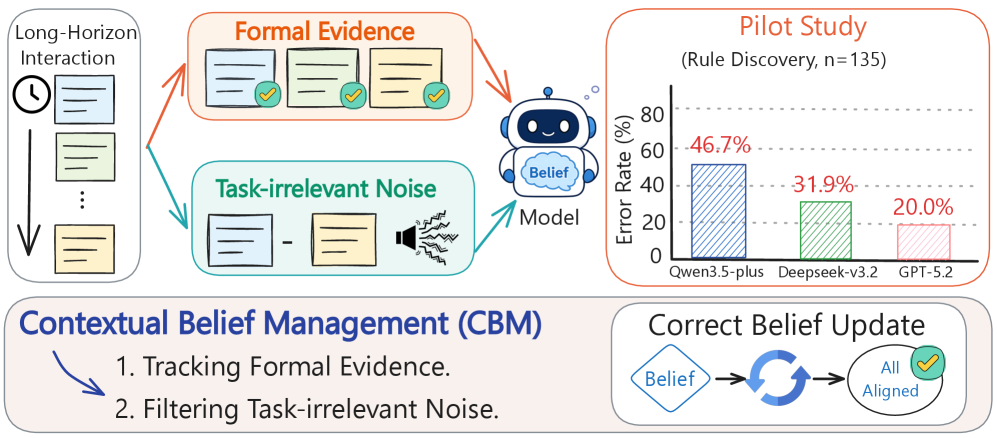
Figure 1 — CBM 개요
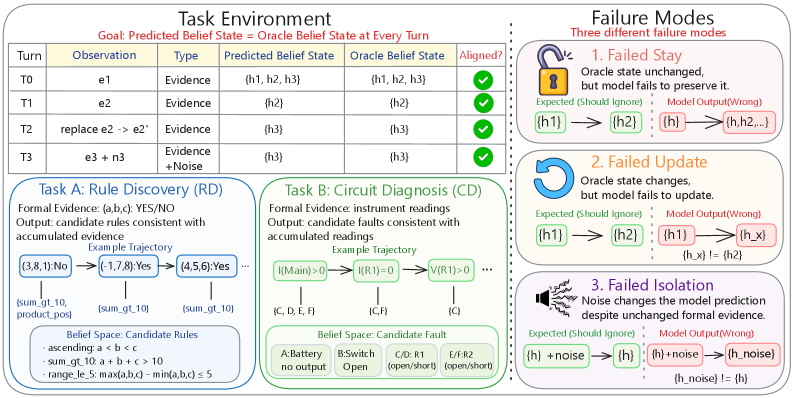
Figure 3 — BeliefTrack 프레임워크
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 저자들은 BT-Prompt(테스트 시점의 프롬프트 강화)와 RL with Belief-State Rewards(검증기 기반 강화학습) 두 가지 방법론을 통해 CBM 성능 향상을 시도합니다. 실험 결과, Vanilla 모델은 모든 실패 유형에서 매우 높은 오류율(약 97~99%)을 보였으며, 프롬프트 기반의 접근은 성능 개선이 미미하거나 오히려 성능 저하를 일으키기도 했습니다 [Table 1]. 반면, GRPO를 활용한 강화학습은 Jaccard 유사도 기반의 보상을 통해 실패율을 평균 70.9% 감소시키는 괄목할 만한 성능 향상을 보였습니다 [Table 1]. 특히 강화학습 모델은 훈련에 사용되지 않은 노이즈 환경에서도 강한 일반화 능력을 보였으며, 표현 수준의 스티어링(Representation-level steering) 기법을 통해 매개변수 업데이트 없이도 Failed Stay, Failed Update, Failed Isolation 실패율을 효과적으로 낮출 수 있음을 입증했습니다 [Figure 5].
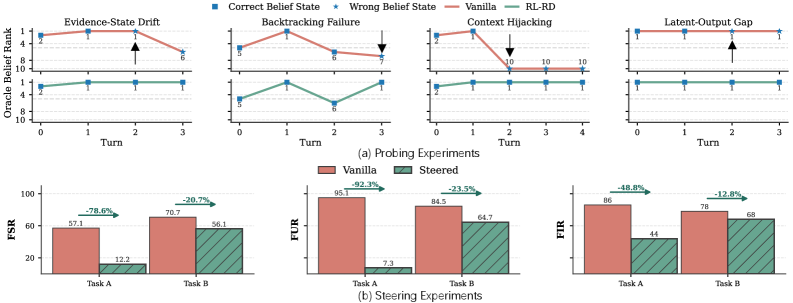
Figure 5 — 오류 진단 및 스티어링
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 LLM의 Belief Management 능력을 측정하기 위한 체계적인 지표와 환경을 마련하였으며, 강화학습을 통한 모델 정렬이 근본적인 추론 오류 해결에 효과적임을 증명했습니다. LLM이 복잡한 다중 턴 환경에서 신뢰성 있게 작동하기 위해서는 단순히 정보를 흡수하는 것을 넘어, 증거 기반으로 상태를 관리하는 능력이 필수적입니다. 본 논문의 결과는 학계 및 산업계에서 보다 신뢰할 수 있는 장기 기억 기반 AI 에이전트를 개발하는 데 중요한 기틀이 될 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Agon: Competitive Cross-Model RL with Implicit Rival Grading of Reasoning
- [논문리뷰] Spectral Rewiring for Exploration, Purification, and Model Merging
- [논문리뷰] Weak-to-Strong Generalization via Direct On-Policy Distillation
- [논문리뷰] UP: Unbounded Positive Asymmetric Optimization for Breaking the Exploration-Stability Dilemma
- [논문리뷰] When LLMs Read Tables Carelessly: Measuring and Reducing Data Referencing Errors
Review 의 다른글
- 이전글 [논문리뷰] When Cloud Agents Meet Device Agents: Lessons from Hybrid Multi-Agent Systems
- 현재글 : [논문리뷰] When Should Models Change Their Minds? Contextual Belief Management in Large Language Models
- 다음글 [논문리뷰] Why Larger Models Learn More: Effects of Capacity, Interference, and Rare-Task Retention
댓글