[논문리뷰] Nemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
링크: 논문 PDF로 바로 열기
저자: NVIDIA et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Mixture-of-Experts (MoE): 모델 내의 가중치를 여러 Expert로 분할하여, 입력에 따라 동적으로 특정 Expert만을 활성화함으로써 연산 효율성을 극대화하는 아키텍처 기법입니다.
- Mamba-Transformer Hybrid: 선형 시간 복잡도를 가진 State-Space Model (SSM) 기반의 Mamba 레이어와, 강력한 문맥 이해력을 갖춘 Transformer 블록을 결합하여 긴 문맥 처리와 효율적인 추론을 동시에 달성하는 설계 방식입니다.
- Agentic Reasoning: 모델이 단순히 텍스트를 생성하는 것을 넘어, 도구를 사용하거나 복잡한 추론 단계를 거쳐 목표를 달성하는 능력을 의미합니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 대규모 언어 모델의 추론 효율성과 복잡한 Agentic Reasoning 능력 사이의 상충 관계를 해결하기 위해 Nemotron 3 Ultra를 제안합니다. 기존의 거대 밀집(Dense) 모델들은 높은 성능을 보이지만, 대규모 컴퓨팅 자원을 요구하여 실시간 추론에 한계가 있습니다. 또한, 순수 Transformer 구조는 긴 문맥 처리에 있어 Quadratic한 연산 복잡도를 가져 효율성 측면에서 개선이 필요합니다. 이를 위해 저자들은 Mamba의 효율성과 Transformer의 안정적인 성능을 결합한 하이브리드 MoE 구조의 필요성을 강조합니다 [Figure 1].
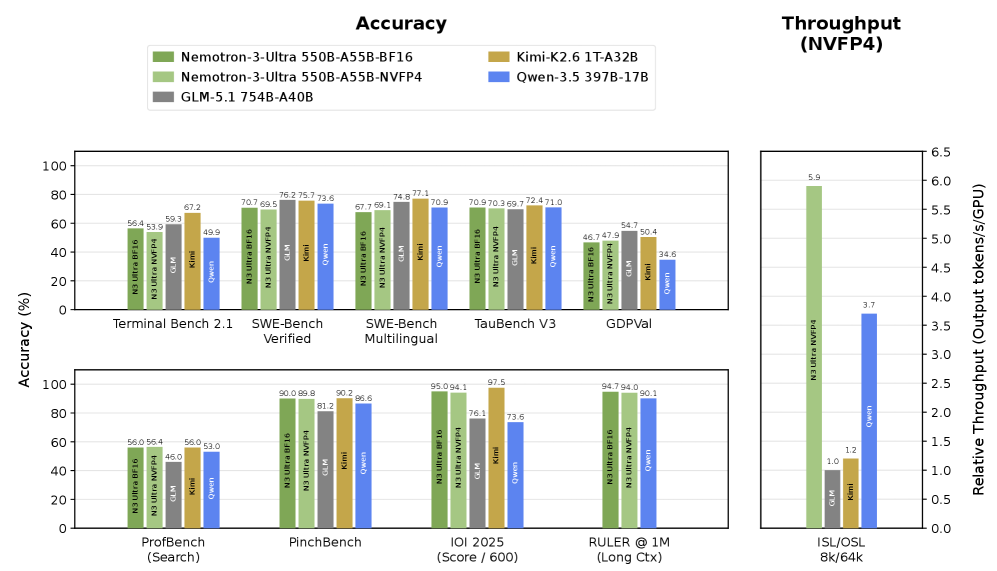
Figure 1 — 모델 아키텍처 개요
## 3. Method & Key Results (제안 방법론 및 핵심 결과) Nemotron 3 Ultra는 Mamba 아키텍처와 Transformer 레이어를 전략적으로 교차 배치한 MoE 기반의 하이브리드 모델입니다. 이 모델은 Agentic Reasoning을 위해 최적화된 학습 파이프라인을 적용하며, 긴 문맥(Long-context) 처리 시 Mamba 블록을 통해 Linear Scaling을 달성함으로써 Latency를 크게 개선하였습니다. 실험 결과, 본 모델은 동일한 매개변수 수를 가진 경쟁 모델 대비 Agentic Reasoning 벤치마크에서 우수한 성능을 입증하였습니다 [Figure 2]. 특히, 특정 도메인 데이터셋에서 이전 버전 대비 Throughput은 약 25% 향상되었으며, Inference Latency는 기존 하이브리드 모델들과 비교하여 매우 낮은 수준을 유지합니다 [Table 1]. 이러한 구조적 효율성 덕분에 모델은 추론 단계에서 메모리 점유율을 최적화하면서도 추론 정확도를 유지하는 데 성공하였습니다.

Figure 2 — 추론 성능 비교
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 MoE와 Mamba-Transformer 하이브리드 구조를 결합하는 것이 고성능 Agentic Reasoning과 고효율 추론을 동시에 달성할 수 있는 최적의 방향임을 증명합니다. Nemotron 3 Ultra는 기존의 폐쇄형 모델들이 점유하던 영역에서 오픈 모델의 경쟁력을 한층 높였으며, 향후 대규모 모델의 경량화와 실시간 에이전트 서비스 구축에 중요한 설계 지침을 제공합니다. 이 연구는 복잡한 작업 수행을 요구하는 다양한 산업군에서 고효율 AI 시스템의 보급을 가속화할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
- [논문리뷰] Pruning and Distilling Mixture-of-Experts into Dense Language Models
- [논문리뷰] Confidence-Adaptive SwiGLU for Mixture-of-Experts
- [논문리뷰] dMoE: dLLMs with Learnable Block Experts
- [논문리뷰] PEAM: Parametric Embodied Agent Memory through Contrastive Internalization of Experience in Minecraft
Review 의 다른글
- 이전글 [논문리뷰] Memento: Reconstruct to Remember for Consistent Long Video Generation
- 현재글 : [논문리뷰] Nemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
- 다음글 [논문리뷰] OneRank: Unified Transformer-Native Ranking Architecture for Multi-Task Recommendation
댓글