[논문리뷰] APPO: Agentic Procedural Policy Optimization
링크: 논문 PDF로 바로 열기
Part 1: 요약 본문
저자: Xucong Wang, Ziyu Ma, Yong Wang, Yuxiang Ji, Shidong Yang, Guanhua Chen, Pengkun Wang, Xiangxiang Chu
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agentic RL: LLM 기반 에이전트가 외부 환경(Tools)과 상호작용하며 학습하는 강화학습 패러다임입니다.
- Procedural Decision Points: 단순히 tool-call 경계를 넘어, 모델의 이후 추론 경로(reasoning path)를 근본적으로 변화시키는 핵심적인 latent decision point를 지칭합니다.
- Branching Score (BS): 토큰의 정보 엔트로피와 해당 토큰이 이후 연속된 생성 결과에 미치는 정책적 영향력(policy-induced likelihood gain)을 결합하여, 가장 중요한 decision point를 식별하는 지표입니다.
- Procedure-level Advantage Scaling: 전체 rollout 단위가 아닌, 중요 decision point(procedure)별로 advantage를 가중치화하여 보상을 정교하게 할당하는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 Agentic RL의 조잡한(coarse) 보상 할당(credit assignment) 문제를 해결하고자 합니다. 대부분의 기존 연구는 tool-call boundaries나 고정된 workflow 단위로만 보상을 분배하여, 추론 과정 중 어느 중간 단계가 최종 결과에 결정적인 영향을 미쳤는지 식별하지 못한다는 한계가 있습니다 [Figure 1]. 또한, 단순히 토큰의 엔트로피만으로는 중요한 결정 지점을 정확히 포착하기 어려우며, Lexical rarity와 같은 노이즈가 발생할 수 있습니다. 결과적으로 이러한 Coarse-grained credit assignment는 비효율적인 학습과 불안정한 정책 개선을 초래합니다.
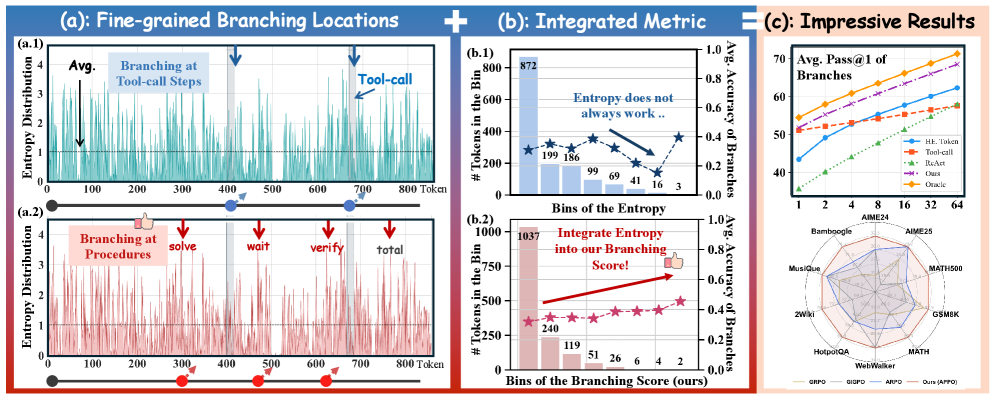
Figure 1 — 기존 지표와 APPO의 비교 및 성능
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 decision points를 기반으로 rollout을 분기하고 보상을 할당하는 APPO (Agentic Procedural Policy Optimization)를 제안합니다 [Figure 2]. APPO는 Branching Score (BS)를 도입하여 단순 엔트로피의 한계를 극복하고, 모델의 정책적 영향력(future value, $\Omega$)을 고려하여 결정 지점을 식별합니다. 또한, 식별된 decision point에서 분기된 결과들에 대해 Procedure-level advantage scaling을 적용하여 핵심적인 추론 과정에 더 정교한 보상을 부여합니다.
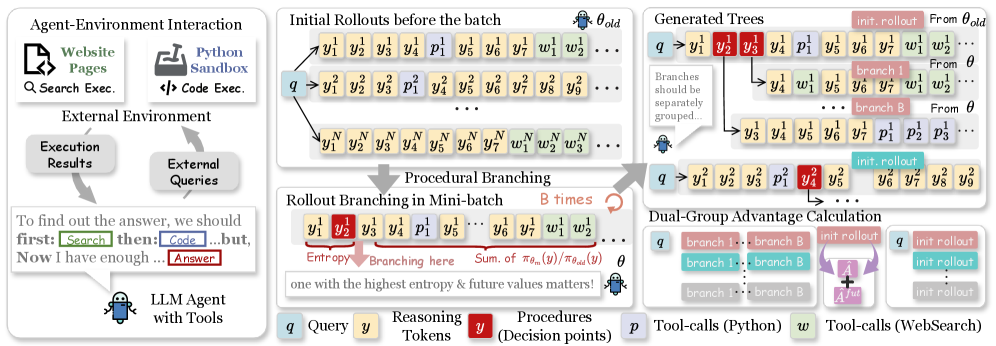
Figure 2 — APPO 전체 프레임워크
실험 결과, APPO는 13개 벤치마크에서 기존 SOTA 베이스라인 대비 약 4 포인트의 성능 향상을 기록했습니다 [Table 1]. 특히 Deep Search와 같은 복잡한 long-horizon 과제에서 Qwen3-8B 및 Qwen3-14B 백본을 사용했을 때 일관되게 우수한 결과를 보였습니다 [Table 2]. 또한, Pass@K 지표에서 볼 수 있듯, APPO는 단순히 단일 정답률뿐만 아니라 탐색 공간 내의 유효한 추론 경로의 다양성을 크게 확장시킵니다 [Figure 3].

Figure 3 — Pass@K 성능 분석
4. Conclusion & Impact (결론 및 시사점)
APPO는 agentic RL의 학습 단위를 coarse-grained workflow에서 fine-grained procedural decision points로 전환함으로써 더욱 효율적인 학습을 가능하게 합니다. 본 연구는 결정 지점의 구조적 중요성을 이론적으로 정립하고 실증적으로 증명하였으며, 이는 에이전트가 복잡한 추론 문제를 해결하는 방식을 근본적으로 개선할 수 있음을 보여줍니다. 이러한 접근 방식은 향후 에이전트의 효율적인 탐색과 정교한 정책 최적화 연구에 중요한 방법론적 토대를 제공할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] AEM: Adaptive Entropy Modulation for Multi-Turn Agentic Reinforcement Learning
- [논문리뷰] Reinforcement Learning from Rich Feedback with Distributional DAgger
- [논문리뷰] CEPO: RLVR Self-Distillation using Contrastive Evidence Policy Optimization
- [논문리뷰] FIPO: Eliciting Deep Reasoning with Future-KL Influenced Policy Optimization
- [논문리뷰] Hindsight Credit Assignment for Long-Horizon LLM Agents
Review 의 다른글
- 이전글 [논문리뷰] Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
- 현재글 : [논문리뷰] APPO: Agentic Procedural Policy Optimization
- 다음글 [논문리뷰] APT: Action Expert Pretraining Improves Instruction Generalization of Vision-Language-Action Policies
댓글