[논문리뷰] APT: Action Expert Pretraining Improves Instruction Generalization of Vision-Language-Action Policies
링크: 논문 PDF로 바로 열기
메타데이터
저자: Kechun Xu, Zhenjie Zhu, Anzhe Chen, Rong Xiong, Yue Wang
1. Key Terms & Definitions (핵심 용어 및 정의)
- VLA (Vision-Language-Action) Models: pretrained VLM을 기반으로 시각적 관측과 언어 명령을 입력받아 로봇의 제어 동작을 생성하는 모델입니다.
- Visual Shortcuts: VLA 모델이 학습 데이터 내의 시각적 패턴에만 의존하고 언어 명령의 의미를 무시하여, OOD(Out-of-Distribution) 명령에 대해 성능이 저하되는 현상을 의미합니다.
- VA (Vision-Action) Prior: 언어 입력 없이 시각적 관측에서 직접 동작을 생성하도록 학습된 모델의 부분으로, 언어 불균형 문제로부터 자유로운 visuomotor 제어를 담당합니다.
- Gated Fusion: VLM의 계층적 특징(feature)을 action expert에 통합할 때, 학습 가능한 gate를 사용하여 VLM 정보의 반영 정도를 동적으로 조절하는 기법입니다.
- Knowledge Insulation (KI): VLA 학습 과정에서 action expert의 gradient가 VLM backbone으로 전파되는 것을 차단하여, 언어 표현 능력이 왜곡되는 것을 방지하는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 continuous-action 기반 VLA 모델이 겪는 OOD 언어 일반화 성능 저하 문제를 해결하기 위해 APT (Action Expert Pretraining)를 제안합니다. 기존의 continuous-action 모델은 action expert가 랜덤 초기화 상태에서 언어와 시각 정보 간의 구조적 불균형이 심한 데이터를 학습해야 하므로, 언어적 의미를 제대로 파악하지 못하고 visual shortcuts에 빠지기 쉽습니다. 이러한 잘못된 학습은 noisy한 gradient를 생성하여 VLM의 언어 표현력을 저해하는 심각한 부작용을 초래합니다. 기존의 Knowledge Insulation 기법만으로는 이러한 일반화 한계를 돌파하기 어려우며, 저자들은 이 문제를 action expert의 초기화 관점에서 근본적으로 해결하고자 합니다 [Figure 1].
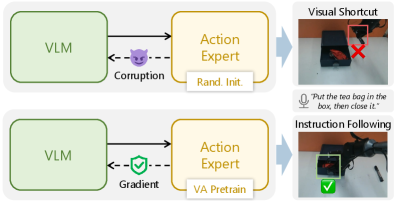
Figure 1 — APT 모델의 언어 일반화 구조
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Bayesian factorization을 통해 VLA 정책을 언어 독립적인 VA prior와 언어 조건부 VLA likelihood로 분리하고, 이를 학습하기 위한 2단계 APT 기법을 제안합니다 [Figure 2]. Stage 1에서는 frozen VLM 상태에서 시각-행동 쌍만을 사용하여 action expert를 VA prior로 사전 학습시키고, Stage 2에서는 사전 학습된 가중치를 보존하면서 gated fusion mechanism을 통해 언어 토큰을 주입하여 VLA likelihood로 정교화합니다 [Figure 3]. 실험 결과, APT는 LIBERO-PRO 벤치마크에서 기존 방법론인 OpenVLA 및 π0 대비 OOD 명령 및 구성적 태스크(compositional task)에서 압도적인 성능 향상을 보였습니다. 특히, APT (Ft VLM) 모델은 KI 기법 없이도 기존 baseline들보다 우수한 성공률(예: 특정 환경에서 62% 달성)을 기록하여, 양질의 action prior가 언어 일반화에 핵심적인 역할을 함을 입증했습니다 [Table 1], [Table 2]. 또한, 이 기법은 다양한 아키텍처에 적용 가능하여 범용적인 성능 향상을 이끌어냅니다 [Figure 4].
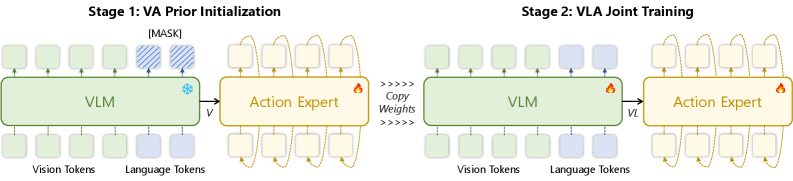
Figure 2 — APT 2단계 학습 과정
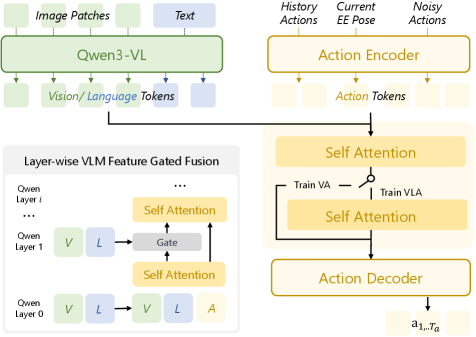
Figure 3 — Action Expert 설계 및 Gated Fusion
4. Conclusion & Impact (결론 및 시사점)
본 논문은 action expert의 사전 학습이 VLA 모델의 언어 일반화 능력을 크게 개선할 수 있음을 이론적(Bayesian 관점) 및 실험적으로 증명하였습니다. 제안된 2단계 학습 방식은 데이터 불균형 문제를 해결하고, 시각적 정보와 언어 정보의 정교한 결합을 통해 로봇이 처음 접하는 복잡한 언어 명령을 효과적으로 수행하도록 돕습니다. 본 연구는 차세대 범용 로봇 정책 개발에 있어, action generation 모듈의 설계와 학습 전략이 VLM 기반의 언어 이해 능력만큼이나 중요하다는 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MotionVLA: Vision-Language-Action Model for Humanoid Motion
- [논문리뷰] LabVLA: Grounding Vision-Language-Action Models in Scientific Laboratories
- [논문리뷰] NVIDIA OmniDreams: Real-Time Generative World Model for Closed-Loop Autonomous Vehicle Simulation
- [논문리뷰] OpenWorldLib: A Unified Codebase and Definition of Advanced World Models
- [논문리뷰] Green-VLA: Staged Vision-Language-Action Model for Generalist Robots
Review 의 다른글
- 이전글 [논문리뷰] APPO: Agentic Procedural Policy Optimization
- 현재글 : [논문리뷰] APT: Action Expert Pretraining Improves Instruction Generalization of Vision-Language-Action Policies
- 다음글 [논문리뷰] ActiveMimic: Egocentric Video Pretraining with Active Perception
댓글