[논문리뷰] MotionVLA: Vision-Language-Action Model for Humanoid Motion
링크: 논문 PDF로 바로 열기
메타데이터
저자: Nonghai Zhang, Siyu Zhai, Yanjun Li, Zeyu Zhang, Zhihan Yin, Yandong Guo, Boxin Shi, Hao Tang
1. Key Terms & Definitions (핵심 용어 및 정의)
- DSFT (Dual-Stream Frequency-Domain Tokenizer): 인간의 움직임을 저주파 중심의 Base stream(포즈 의미론)과 고주파 중심의 Phys stream(물리적 역학)으로 분리하여 독립적으로 압축 및 토큰화하는 기법입니다.
- Base/Phys Streams: Motion 데이터를 DCT(Discrete Cosine Transform) 분석을 통해 주파수 성분에 따라 나눈 두 가지 스트림입니다. Base는 관절 위치와 같이 느리게 변하는 포즈 정보를, Phys는 속도와 같이 빠르게 변하는 물리적 역학 정보를 포함합니다.
- MBench: ViMoGen-228K 데이터셋과 연계된 벤치마크로, 미세한 신체 움직임 품질과 물리적 일관성을 평가하기 위해 설계되었습니다.
- Phase-Aware Generation: Base 토큰 생성 완료 후 Phys 토큰을 생성하도록 강제하는 인퍼런스 제약 조건으로, 의미론적 구조를 먼저 확립한 뒤 물리적 역학을 생성하게 합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 단일 코드북 기반 모션 토큰화가 저주파 포즈 정보에 편향되어 고주파 물리적 역학을 제대로 표현하지 못하는 문제를 해결하고자 합니다. 대다수 연구들은 움직임을 하나의 시퀀스로 통합하여 이산화하는데, 이는 관절 위치(저주파)와 속도(고주파)의 상이한 통계적 특성을 무시하게 만듭니다. 저자들은 관절 위치의 에너지 93%가 5개의 DCT 계수에 집중되는 반면, 관절 속도는 훨씬 높은 주파수 대역에 분산되어 있음을 입증했습니다. 결과적으로, 기존 모델은 시간이 지날수록 발 미끄러짐(Foot sliding)이나 접촉 왜곡(Contact distortion)과 같은 temporal drift 현상을 초래합니다 [Figure 1].

Figure 1 — 단일 스트림 대비 개선된 MotionVLA
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 움직임을 의미론과 물리적 역학으로 명확히 구분하는 MotionVLA 프레임워크를 제안합니다. 제안된 DSFT는 움직임 데이터를 주파수 영역에서 두 스트림으로 분리하고, 각각에 최적화된 DCT 절단 길이($K_b=5, K_p=25$)를 적용하여 독립적으로 BPE 토큰화합니다 [Figure 2]. 이후 Qwen3.5 기반의 오토리그레시브 백본이 Base 토큰을 먼저 생성한 뒤 이를 문맥으로 삼아 Phys 토큰을 생성하도록 설계하였습니다 [Figure 3]. MBench 평가 결과, MotionVLA는 기존의 ViMoGen-light 대비 Motion-Condition Consistency를 0.53에서 0.55로 향상시켰으며, Foot Sliding 지표를 0.0051에서 0.0049로 개선하는 데 성공했습니다 [Table 2]. 또한 HumanML3D 벤치마크에서 Diversity 지표를 실제 데이터 분포에 가장 가깝게 구현하며, 2B 규모의 경량 백본으로도 강력한 일반화 성능을 입증하였습니다 [Table 3]. 이러한 성능 향상은 두 스트림 간의 에너지 보존 특성을 반영한 효율적인 토큰 설계 덕분입니다 [Figure 4].
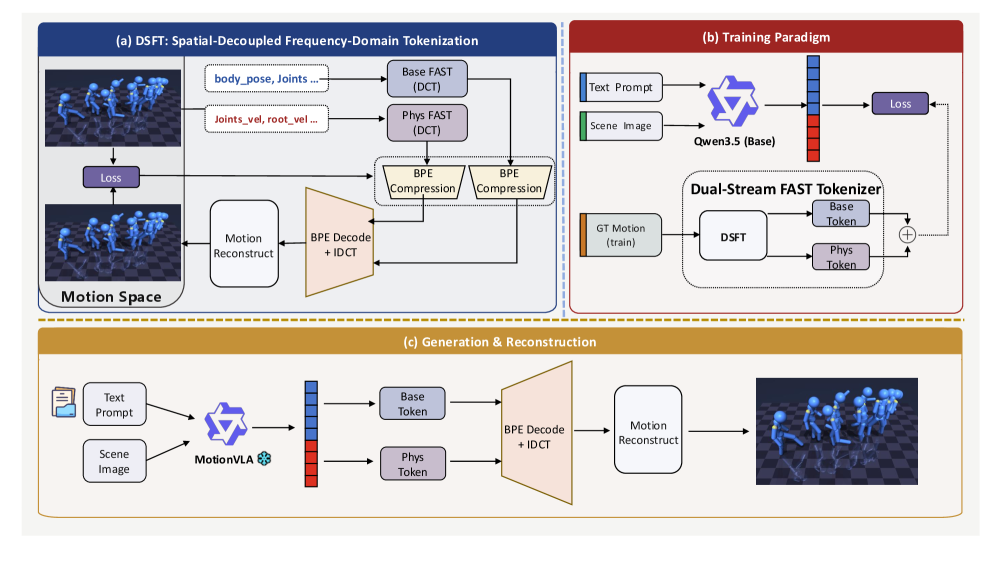
Figure 2 — MotionVLA 아키텍처
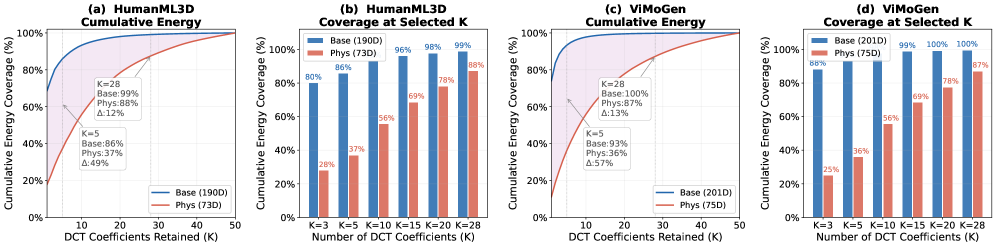
Figure 4 — 스트림별 주파수 에너지 보존율
4. Conclusion & Impact (결론 및 시사점)
본 논문은 휴머노이드 모션 생성이 단순한 압축 문제가 아니라, 모션 신호의 조직화된 표현이 핵심임을 시사합니다. DSFT와 MotionVLA를 통해 의미론적 포즈 구조와 물리적 역학을 분리함으로써, 기존 오토리그레시브 모델의 구조적 한계였던 temporal drift 문제를 효과적으로 극복했습니다. 본 연구는 향후 Embodied AI 분야에서 고품질 모션 합성뿐만 아니라, 로봇 실물 제어 및 다양한 환경에서의 물리적 일관성을 유지하는 핵심 기법으로 활용될 것으로 기대됩니다. 향후에는 더 큰 모델 스케일과 적응형 토큰화 기법을 통한 범용적 모션 생성 프레임워크로의 확장이 예상됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Adaptive Volumetric Mechanical Property Fields Invariant to Resolution
- [논문리뷰] Memento: Reconstruct to Remember for Consistent Long Video Generation
- [논문리뷰] BadWorld: Adversarial Attacks on World Models
- [논문리뷰] APT: Action Expert Pretraining Improves Instruction Generalization of Vision-Language-Action Policies
- [논문리뷰] LabVLA: Grounding Vision-Language-Action Models in Scientific Laboratories
Review 의 다른글
- 이전글 [논문리뷰] Looped World Models
- 현재글 : [논문리뷰] MotionVLA: Vision-Language-Action Model for Humanoid Motion
- 다음글 [논문리뷰] OPD-Evolver: Cultivating Holistic Agent Evolver via On-Policy Distillation
댓글