[논문리뷰] OPD-Evolver: Cultivating Holistic Agent Evolver via On-Policy Distillation
링크: 논문 PDF로 바로 열기
저자: Guibin Zhang, Xun Xu, Yanwei Yue, Zikun Su, Wangchunshu Zhou, Xiaobin Hu, Shuicheng Yan
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- OPD-Evolver: 경험의 선택, 실행, 기록, 관리라는 4단계 라이프사이클을 통해 스스로 진화하는 holistic agent evolver를 구현하는 slow-fast co-evolution 프레임워크입니다.
- On-Policy Distillation (OPD): 학생 모델(student policy)이 자신의 궤적을 따라 탐색하고, 교사 모델(teacher model)의 특권적 정보(privileged hindsight)를 통해 dense supervision을 받아 정교화되는 학습 기법입니다.
- Four-level Memory Hierarchy: Agent가 경험을 재사용하기 위해 사용하는
traj(trajectories),tip(heuristics),skill(procedures),tool(command/code templates)의 4단계 메모리 구조입니다. - Outcome-calibrated Attribution: 성공/실패라는 환경적 피드백(Rt)을 사용하여 특정 메모리가 결과에 얼마나 기여했는지를 추정하고, 이를 통해 메모리의 가치(V(m))를 산출하는 정량적 평가 기법입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 기존 메모리 증강 에이전트들이 단기적인 경험 저장이나 활용에는 능숙하지만, 상호작용 기록과 피드백을 지속적인 행동 개선으로 전환하는 '진정한 의미의 자가 진화(self-evolution)' 역량이 부족하다는 문제의식에서 출발합니다. 기존의 많은 방법론은 경험의 retrieval이나 단순히 맥락에 주입하는 것에 그치며, 에이전트의 선택, 실행, 기록, 관리가 통합적으로 이루어지지 않는 단편적인 최적화에 머물러 있습니다. 특히 보상 피드백이 실행에는 직접적이지만 메모리 관리와 같은 장기적 행동에는 sparse한 supervision을 제공한다는 점이 큰 병목입니다. 따라서 에이전트가 경험의 전체 생애 주기를 체계적으로 학습하여 스스로 진화할 수 있는 holistic한 능력을 갖추는 것이 필수적입니다. [Figure 1]은 제안하는 fast loop와 slow loop의 상호작용 구조를 잘 보여줍니다.
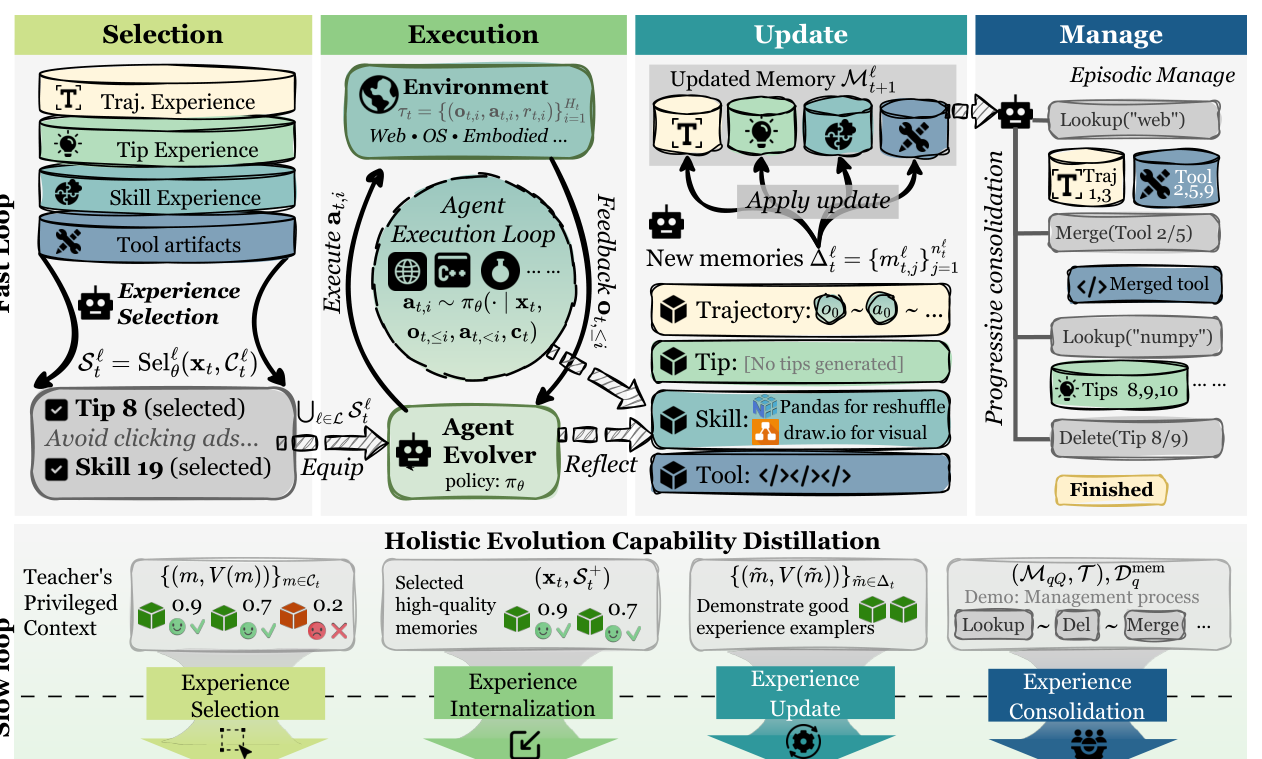
Figure 1 — 전체 프레임워크인 Fast Loop와 Slow Loop의 구조를 시각화한 핵심 다이어그램
## 3. Method & Key Results (제안 방법론 및 핵심 결과) OPD-Evolver는 에이전트가 실시간으로 경험을 활용하는 Fast Evolution Loop와, 수집된 궤적과 특권적 지식(privileged hindsight)을 기반으로 정책을 최적화하는 Slow Evolution Loop로 구성된 이중 루프 구조를 채택합니다. Fast loop에서는 4단계 메모리 계층을 활용하여 task-relevant context를 선택하고 실행하며, 이후 Outcome-calibrated memory attribution을 통해 각 메모리의 가치를 평가합니다. Slow loop에서는 이 정보를 바탕으로 에이전트의 내부 정책을 On-Policy Distillation하여 경험 라이프사이클 전반의 능력을 distillation합니다. [Table 1]에 명시된 실험 결과에 따르면, OPD-Evolver-9B 모델은 LifelongAgentBench, MemoryArena, AMA-Bench 등 4개 벤치마크에서 기존 최고 수준의 메모리 시스템인 ReasoningBank 및 EvolveR를 최대 11.5%까지 능가하는 우수한 성과를 거두었습니다. 또한, QWEN3.5-397B와 같은 거대 모델들과 대등하거나 일부 항목에서 우월한 성능을 보이며 Compact 모델의 효율성을 입증했습니다. [Table 2]에서는 SFT 및 GRPO와 같은 최신 학습 기반 방법론들보다도 MiniHack 및 InterCode 태스크에서 일관되게 높은 성공률을 기록하여 본 기법의 전이 가능성을 확인하였습니다.
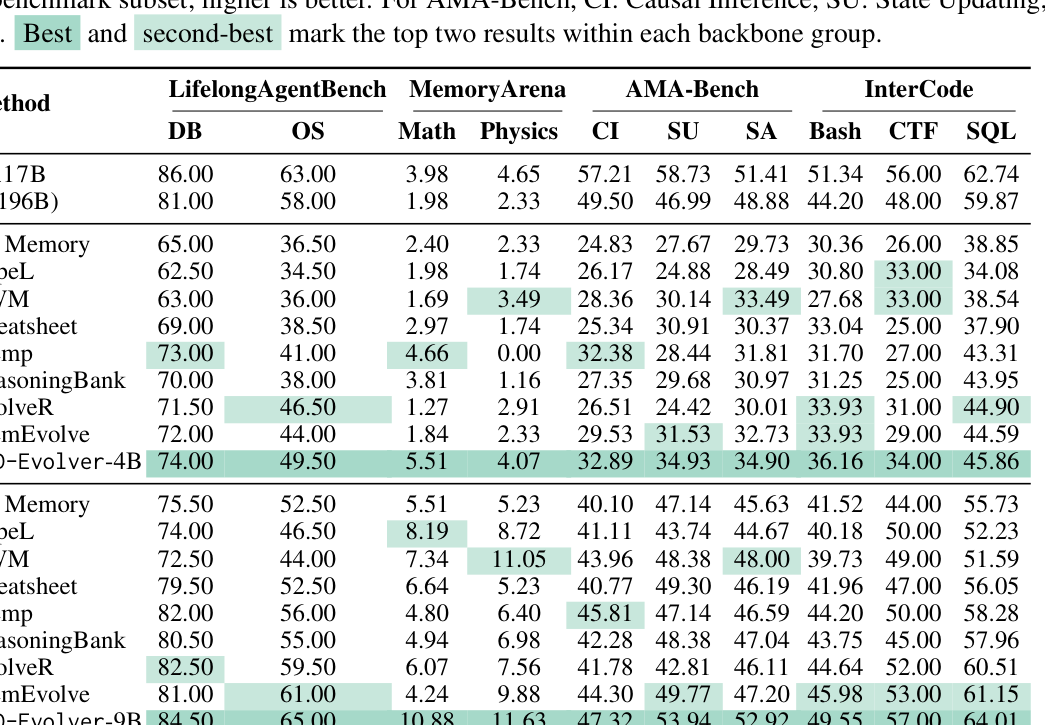
Table 1 — 제안 모델과 기존 baseline들 간의 벤치마크 성능을 비교한 핵심 결과 테이블

Table 2 — 학습 기반의 최신 방법론들과의 성능 비교 결과
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 경험의 단순 저장과 활용을 넘어, 에이전트가 스스로 경험을 가치 있게 관리하고 자신의 행동 정책을 체계적으로 개선하는 자가 진화 메커니즘을 성공적으로 구현하였습니다. OPD-Evolver는 제안된 slow-fast co-evolution 프레임워크를 통해 이질적인 에이전트 환경에서도 일반화 가능한 진화 역량을 확보할 수 있음을 입증했습니다. 이는 향후 거대 언어 모델 기반 에이전트가 데이터 정제나 대규모 추가 학습 없이도 환경과의 상호작용만으로 지속적인 성능 향상을 도모할 수 있는 새로운 패러다임을 제시하며, 학계와 산업계의 agentic AI 구축 방식에 중요한 기술적 이정표가 될 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OPRD: On-Policy Representation Distillation
- [논문리뷰] Filter, Then Reweight: Rethinking Optimization Granularity in On-Policy Distillation
- [논문리뷰] Trust Region On-Policy Distillation
- [논문리뷰] CollectionLoRA: Collecting 50 Effects in 1 LoRA via Multi-Teacher On-Policy Distillation
- [논문리뷰] GenEvolve: Self-Evolving Image Generation Agents via Tool-Orchestrated Visual Experience Distillation
Review 의 다른글
- 이전글 [논문리뷰] MotionVLA: Vision-Language-Action Model for Humanoid Motion
- 현재글 : [논문리뷰] OPD-Evolver: Cultivating Holistic Agent Evolver via On-Policy Distillation
- 다음글 [논문리뷰] ProCUA-SFT Technical Report
댓글