[논문리뷰] ActiveMimic: Egocentric Video Pretraining with Active Perception
링크: 논문 PDF로 바로 열기
메타데이터
저자: Xingyao Lin, Guojin Zhong, Tianyi Lu, Ziyi Ye, Yichen Zhu, Zuxuan Wu, Yu-Gang Jiang
1. Key Terms & Definitions (핵심 용어 및 정의)
- Active Perception: 에이전트가 과업 수행 중 시각적 불확실성을 줄이기 위해 자신의 시점(Viewpoint)을 능동적으로 제어하는 능력입니다.
- Unified Action Representation: 카메라의 시점 이동(Viewpoint Action)과 양손의 손목 이동(Bimanual Wrist Motion)을 동일한 참조 프레임 내에서 결합한 27-dimensional 행동 표현입니다.
- Conditional Flow Matching: 복잡한 분포를 학습하기 위한 생성 모델링 기법으로, 논문에서는 행동 chunk를 예측하는 학습 목표(Objective)로 활용됩니다.
- Egocentric Video: 사용자의 시점에서 촬영된 영상 데이터로, 로봇 학습을 위한 대규모 데이터셋으로 활용 가능하지만 표준 파이프라인에서 카메라 움직임이 노이즈로 처리되는 한계가 있습니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 대규모 Egocentric Human Video를 로봇 학습에 활용할 때 발생하는 성능 저하의 핵심 원인이 '능동적 인식(Active Perception) 정보의 부재'에 있음을 규명합니다 [Figure 1]. 기존 연구들은 카메라의 움직임을 단순 노이즈로 간주하여 무시하거나, 추가적인 하드웨어 센서를 사용하여 이 문제를 해결하고자 했습니다. 그러나 이러한 방식은 웹 스케일의 일반적인 Egocentric Video로 확장하기 어렵다는 제약이 있습니다. 저자들은 인간이 조작 중 끊임없이 시점을 이동시키는 행위를 중요한 학습 신호로 해석하고, 특수 장비 없이 단일 RGB 카메라 영상에서 능동적 인식 정보를 추출하는 프레임워크를 제안합니다.
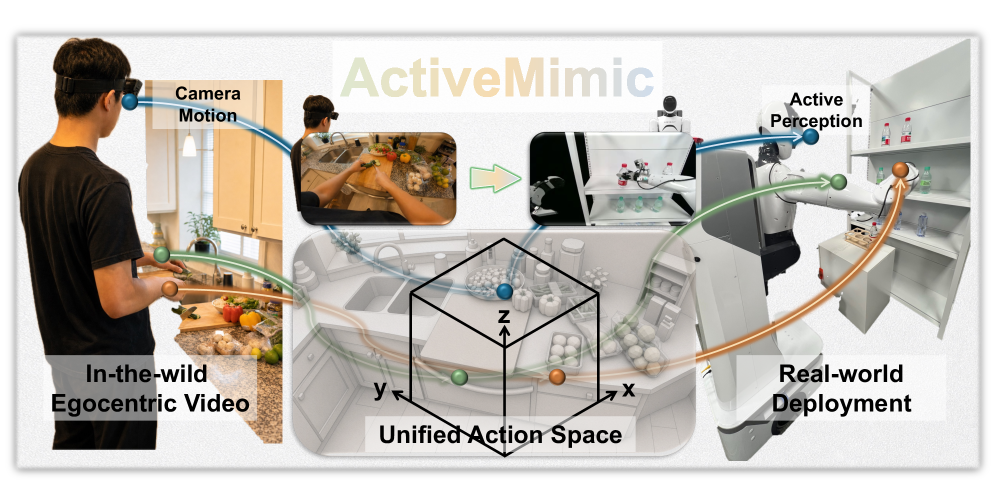
Figure 1 — ActiveMimic 개념도
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문이 제안하는 ActiveMimic은 단일 RGB 영상에서 동기화된 카메라 및 손목 궤적을 추출하고, 이를 27D의 Unified Action Representation으로 인코딩하여 학습합니다 [Figure 2]. 저자들은 Ego4D 데이터셋을 활용하여 카메라와 손목 간의 결합(Coupling)을 해결하고, 시점 이동과 조작 행위를 동시에 학습하는 2단계 훈련 전략을 수립했습니다 [Figure 2]. 실험 결과, ActiveMimic은 모든 평가 과제에서 기존 베이스라인을 압도하는 성과를 보였습니다. 구체적으로 Restocking 과제에서 90.1%, Reaching에서 88.9%, Finding에서 91.7%, Pouring에서 93.3%의 Success Rate를 기록했습니다 [Figure 4]. 특히 능동적 인식 요구도가 높은 과제에서 기존 최신 모델인 **$\pi_0$**보다 우수한 성능을 입증하며, 사전 학습 단계에서 얻은 능동적 인식 능력이 로봇으로 효과적으로 전이됨을 정량적으로 증명했습니다 [Figure 4, Figure 6].
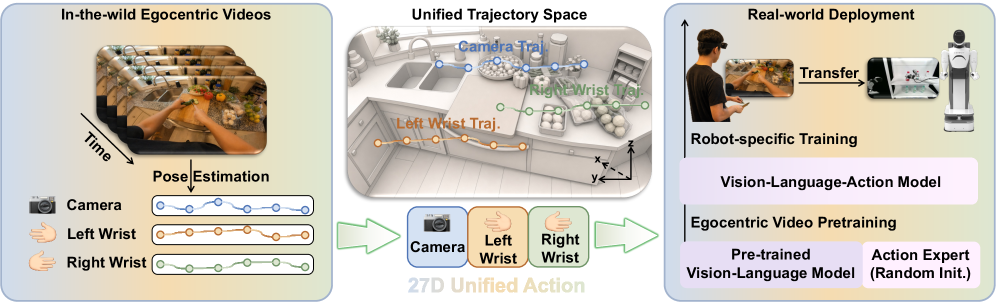
Figure 2 — ActiveMimic 프레임워크
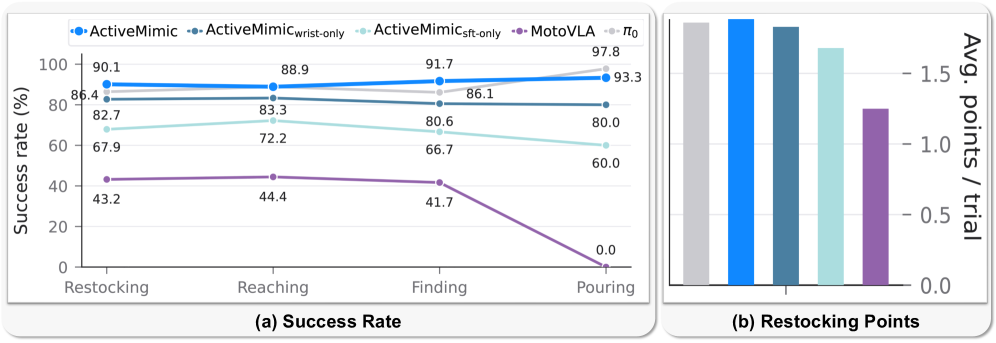
Figure 4 — 실제 로봇 실험 결과
4. Conclusion & Impact (결론 및 시사점)
본 논문은 능동적 인식을 로봇 사전 학습의 핵심 요소로 격상시킴으로써 Egocentric Human Video 활용의 새로운 돌파구를 마련했습니다. ActiveMimic은 값비싼 로봇 데이터 없이도 인간 영상 데이터를 통해 정교한 조작 및 인식 능력을 습득할 수 있음을 입증했습니다. 이 연구는 로봇 파운데이션 모델의 데이터 확장성 문제를 해결하는 데 크게 기여하며, 특히 Active Perception이 단순히 부가적인 기능이 아니라 로봇의 범용적 제어를 위한 필수 기제임을 학계와 산업계에 시사합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Playful Agentic Robot Learning
- [논문리뷰] ImageWAM: Do World Action Models Really Need Video Generation, or Just Image Editing?
- [논문리뷰] Native Active Perception as Reasoning for Omni-Modal Understanding
- [논문리뷰] ACE-Ego-0: Unifying Egocentric Human and Robotic Data for VLA Pretraining
- [논문리뷰] LaWAM: Latent World Action Models for Efficient Dynamics-Aware Robot Policies
Review 의 다른글
- 이전글 [논문리뷰] APT: Action Expert Pretraining Improves Instruction Generalization of Vision-Language-Action Policies
- 현재글 : [논문리뷰] ActiveMimic: Egocentric Video Pretraining with Active Perception
- 다음글 [논문리뷰] AdaSR: Adaptive Streaming Reasoning with Hierarchical Relative Policy Optimization
댓글