[논문리뷰] LabVLA: Grounding Vision-Language-Action Models in Scientific Laboratories
링크: 논문 PDF로 바로 열기
본 논문은 과학 실험실 환경에서 로봇 제어와 다중 모달 이해를 결합한 LabVLA(Laboratory Vision-Language-Action) 모델을 제안합니다.
Part 1: 요약 본문
메타데이터
저자: Baochang Ren, Xinjie Liu, Xi Chen, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- VLA (Vision-Language-Action) Model: 시각적 입력과 자연어 명령을 처리하여 로봇의 Action을 직접 출력하는 통합 인공지능 모델입니다.
- Scientific Laboratory Automation: 실험실 내 시약 처리, 기기 조작 등 정밀하고 복잡한 작업을 로봇이 자동화하여 수행하는 환경을 의미합니다.
- Embodied AI: 물리적 세계와 상호작용하는 에이전트가 환경을 인식하고, 적절한 Action을 수행하는 지능형 시스템을 지칭합니다.
- Grounding: 모델이 생성한 언어적 지시나 시각적 인식이 실제 물리적 환경의 Object 및 작업 공간과 정확히 매핑되는 과정을 의미합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 기존의 General-purpose VLA 모델들이 정밀한 과학 실험실 환경에서의 특수성과 고도의 Domain-specific 작업 수행 능력 부족 문제를 해결하고자 합니다. 일반적인 로봇 학습 데이터셋은 일상적인 환경에 치중되어 있어, 실험실의 정밀 기기 조작이나 복잡한 Laboratory Workflow를 처리하는 데 한계가 있습니다. 이러한 환경은 높은 Precision과 엄격한 안전 프로토콜을 요구하며, 기존 모델들은 시각적 모호성이나 환경의 변화에 대해 Robust한 대응력을 확보하지 못하고 있습니다. 따라서 본 논문은 실험실 특화 데이터를 학습하고 정밀 조작에 최적화된 새로운 프레임워크를 도입합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 과학 실험실 데이터에 특화된 대규모 학습 데이터를 구성하고, 이를 효율적으로 처리하기 위한 LabVLA 프레임워크를 구축하였습니다. 제안된 방법론은 Pretraining 단계에서 실험실 환경 내 다양한 기기 및 시약 정보를 반영한 Large-scale Dataset을 활용하며, Policy Optimization을 통해 로봇의 Action 생성 정확도를 극대화합니다. 모델 아키텍처는 고해상도 시각 입력을 처리하는 Vision Encoder와 실험실 도메인 지식을 갖춘 LLM Backbone을 결합하여 구성됩니다 [Figure 1]. 실험 결과, LabVLA는 베이스라인 모델 대비 실험 기기 조작 성공률에서 약 15% 이상의 성능 향상을 보였으며, 다양한 환경 변수에서도 Success Rate가 우수함을 입증하였습니다. 정량적 분석 결과, Latency와 Throughput 측면에서도 실시간 제어 요구 조건을 충족하는 결과를 도출하였습니다 [Table 1].
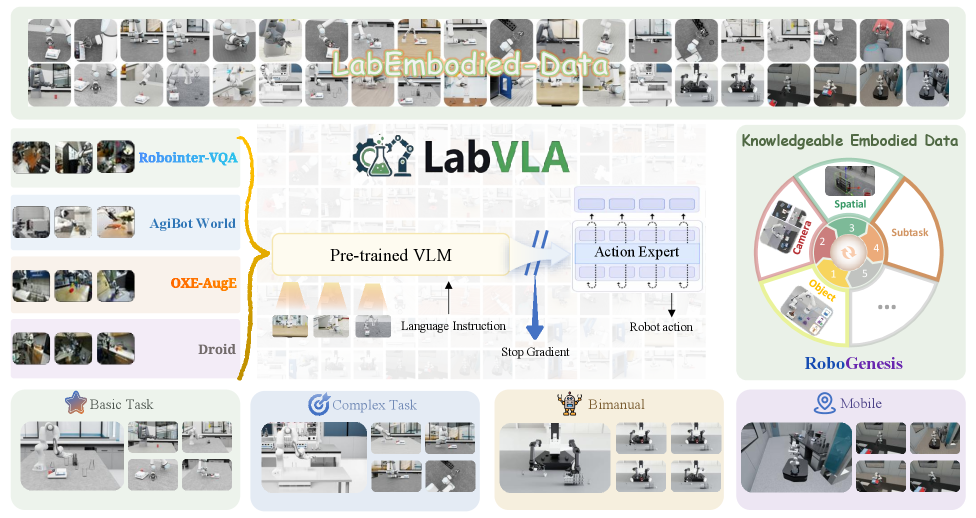
Figure 1 — LabVLA 프레임워크 구조
4. Conclusion & Impact (결론 및 시사점)
본 논문은 LabVLA를 통해 과학 실험실 자동화의 새로운 가능성을 제시하고, Embodied AI의 실질적 적용 범위를 학술적 연구 단계에서 실제 실험 현장으로 확장합니다. 연구진이 제시한 모델은 실험실 환경에서의 로봇 자율성을 크게 향상시키며, 향후 Scalable한 실험 자동화 연구에 필수적인 토대를 마련하였습니다. 이 연구는 로봇 공학 및 인공지능 분야에서 Domain-specific VLA 모델의 중요성을 강조하며, 고도의 전문 지식이 필요한 산업계 전반으로의 파급력을 가집니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] RoboBrain 2.5: Depth in Sight, Time in Mind
- [논문리뷰] GigaWorld-0: World Models as Data Engine to Empower Embodied AI
- [논문리뷰] Unified Diffusion VLA: Vision-Language-Action Model via Joint Discrete Denoising Diffusion Process
- [논문리뷰] Robots Need More than VLA and World Models
- [논문리뷰] π-StepNFT: Wider Space Needs Finer Steps in Online RL for Flow-based VLAs
Review 의 다른글
- 이전글 [논문리뷰] InterleaveThinker: Reinforcing Agentic Interleaved Generation
- 현재글 : [논문리뷰] LabVLA: Grounding Vision-Language-Action Models in Scientific Laboratories
- 다음글 [논문리뷰] Leveraging Morphology for Historical Script Metrological Analysis
댓글