[논문리뷰] InterleaveThinker: Reinforcing Agentic Interleaved Generation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Dian Zheng, Harry Lee, Manyuan Zhang, Kaituo Feng, Zoey Guo, Ray Zhang, Hongsheng Li
1. Key Terms & Definitions (핵심 용어 및 정의)
- Interleaved Generation: 텍스트와 이미지가 혼합된 시퀀스를 순차적으로 생성하는 작업으로, 비디오 내러티브나 로봇 조작 등 복합적인 과업을 수행하는 능력을 의미합니다.
- Visual Over-reliance: VLM이 이전 단계의 결과물에 과도하게 의존하여, 최종 목표를 잊고 단기적인 시각적 결과물에만 매몰되는 현상을 뜻합니다.
- GRPO (Group Relative Policy Optimization): 본 논문에서 Critic 에이전트의 보상을 최적화하기 위해 사용한 강화학습 알고리즘으로, 여러 샘플 간의 상대적 우위를 통해 효율적인 학습을 가능하게 합니다.
- Step-wise Error Accumulation: 다단계 생성 과정에서 초기의 작은 오류가 누적되어 전체적인 생성 품질이 저하되는 문제를 지칭합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 Unified Multimodal Models(UMMs)가 장기 시퀀스 생성 과정에서 겪는 Visual Over-reliance와 Step-wise Error Accumulation 문제를 해결하기 위해 고안되었습니다. 기존 모델들은 단일 단계 생성에는 강점을 보이나, interleaved generation과 같은 복합적인 과업에서는 중간 시각 상태에 매몰되어 전역적인 목표를 상실하는 한계를 가집니다. 저자들은 이러한 근본적인 원인이 계획(Planning)과 평가(Criticism)가 단일 모델 내에서 뒤섞여 있기 때문이라고 분석하였습니다. 이를 위해 저자들은 계획과 실행을 분리하여 기존의 고정된(frozen) 이미지 생성기를 활용하면서도 강력한 순차 생성 능력을 부여하는 새로운 프레임워크를 제안합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Planner, Generator, Critic으로 구성된 다중 에이전트 파이프라인 InterleaveThinker를 제안합니다. Planner 에이전트는 전체 시퀀스에 대한 실행 계획을 사전에 수립하여 비전 모델의 근시안적인 판단을 방지하며, Critic 에이전트는 생성된 결과물을 평가하고 피드백을 통해 프롬프트를 정교화하는 반복적인 보정 루프를 수행합니다. 특히, 25회 이상의 생성 호출이 필요한 긴 시퀀스를 효율적으로 최적화하기 위해, Accuracy Reward와 Step-wise Reward를 결합한 Dual-Reward Strategy를 도입하여 GRPO 기반의 단일 단계 강화학습을 수행합니다. 실험 결과, InterleaveThinker는 4단계 FLUX.2-klein 환경에서 WISE 지표를 0.47에서 0.73으로, RISE 지표를 13.3에서 28.9로 크게 향상시키며 기존 UMM 모델 대비 압도적인 성능 우위를 입증하였습니다. 또한, UEval 벤치마크에서도 상용 모델인 Nano Banana와 대등한 수준의 성능을 달성하며 모델-불가지론적(model-agnostic) 범용성을 확인하였습니다. [Figure 3], [Figure 4]

Figure 3 — InterleaveThinker 아키텍처
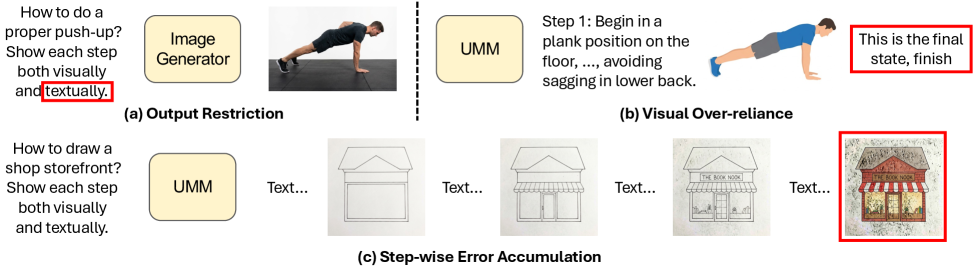
Figure 4 — 작동 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 다중 에이전트 협업과 효율적인 강화학습 설계를 통해 기존 이미지 생성 모델의 한계를 돌파하는 새로운 패러다임을 제시하였습니다. InterleaveThinker는 단순히 순차 생성 능력을 부여하는 것에 그치지 않고, 복합적인 추론(Reasoning) 능력까지 크게 향상시킴으로써 embodied manipulation이나 고도화된 비전 내러티브 분야에 중요한 기술적 토대를 마련하였습니다. 향후 이 연구는 고정된 사전 학습 모델을 대규모 엔드-투-엔드 학습 없이도 전문적인 에이전트로 확장할 수 있는 표준적인 방법론으로 자리 잡을 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
- [논문리뷰] MemTrain: Self-Supervised Context Memory Training
- [논문리뷰] Verifiable Rewards Beyond Math and Code: Lightweight Corpus-Grounded Process Supervision for Factual Question Answering
- [논문리뷰] Agent Explorative Policy Optimization for Multimodal Agentic Reasoning
- [논문리뷰] Spreadsheet-RL: Advancing Large Language Model Agents on Realistic Spreadsheet Tasks via Reinforcement Learning
Review 의 다른글
- 이전글 [논문리뷰] IDEAL: In-DEpth ALignment Makes A Discrete Representation AutoEncoder
- 현재글 : [논문리뷰] InterleaveThinker: Reinforcing Agentic Interleaved Generation
- 다음글 [논문리뷰] LabVLA: Grounding Vision-Language-Action Models in Scientific Laboratories
댓글