[논문리뷰] IDEAL: In-DEpth ALignment Makes A Discrete Representation AutoEncoder
링크: 논문 PDF로 바로 열기
Part 1: 요약 본문
저자: Yitong Chen, Zijie Diao, Junke Wang, Lingyu Kong, Yixuan Ren, Bo He, Yu-Gang Jiang, Zuxuan Wu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- RAE (Representation Autoencoder): Pretrained VFM의 잠재 표현(Latent Representation)을 활용하여 이미지 생성의 효율성과 품질을 높이는 모델입니다.
- VFM (Vision Foundation Models): 강력한 의미적 표현력을 가진 사전 학습된 시각 모델(예: SigLIPv2)로, 이미지의 높은 수준의 의미론적 정보를 인코딩하는 데 사용됩니다.
- Vector Quantization (VQ): 연속적인 특징 벡터를 유한한 코드북 내의 개별 인덱스로 매핑하여 이산적인(Discrete) 시각 토큰을 생성하는 과정입니다.
- Semantic-Spatial Complementarity: VFM의 얕은 계층(Shallow layer)은 재구성(Reconstruction)에 유리한 공간적 디테일을 보유하고, 깊은 계층(Deep layer)은 높은 수준의 의미 정보를 보유한다는 상호보완적 특성입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 VFM 기반의 RAE가 재구성 품질과 의미 보존 사이에서 겪는 근본적인 병목 현상을 해결하고자 합니다. 기존 연구들은 주로 깊은 계층의 의미론적 정보에만 의존하는데, 이는 디테일한 시각적 속성(색상, 텍스트, 로컬 구조 등)을 소실시키는 결과를 초래합니다. 특히 이러한 잠재 공간이 Vector Quantization을 거쳐 이산화될 때, 누락된 저수준 정보는 복구하기 더욱 어렵습니다. 저자들은 이러한 깊이별 trade-off를 Figure 1을 통해 체계적으로 분석하였으며, 재구성 성능과 의미론적 풍부함을 동시에 만족시키는 새로운 표현 학습 프레임워크가 필요함을 강조합니다 [Figure 1].
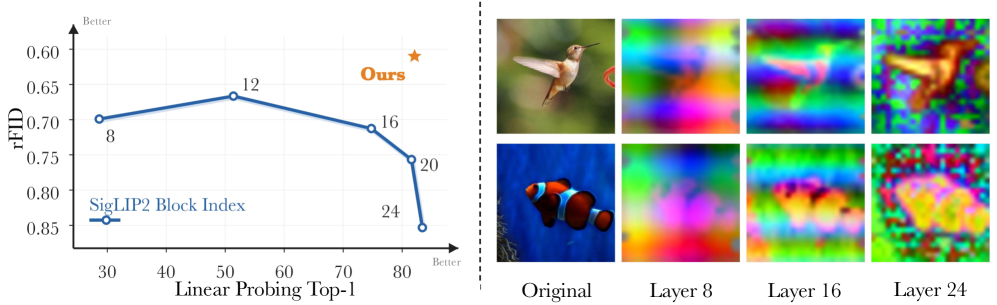
Figure 1 — VFM 계층별 성능 trade-off
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 VFM의 깊은 의미 정보와 얕은 공간 디테일을 효과적으로 결합하는 Ideal 프레임워크를 제안합니다. Ideal은 AttnFuse 모듈을 통해 얕은 특징과 깊은 특징을 융합하여 의미론적 풍부함과 높은 시각적 충실도를 모두 갖춘 통합 표현을 생성합니다. 이후 Vector Quantization을 통해 이산 토큰을 생성하고, 디코더에서는 이중 특징 헤드를 활용하여 얕은 공간 정보와 깊은 의미 정보를 명시적으로 재구성하도록 학습됩니다 [Figure 2]. 주요 실험 결과, Ideal은 ImageNet 벤치마크에서 0.61의 rFID를 달성하여 기존 방식 대비 괄목할 만한 재구성 성능 향상을 보였으며, 의미 보존 측면에서도 80.89%의 Zero-shot 분류 정확도를 기록하였습니다. 나아가 자동회귀 생성 실험에서는 3B 파라미터 모델 기준 1.89의 gFID를 달성하며 최신 SOTA 성능을 기록하였습니다 [Table 2, Table 5].
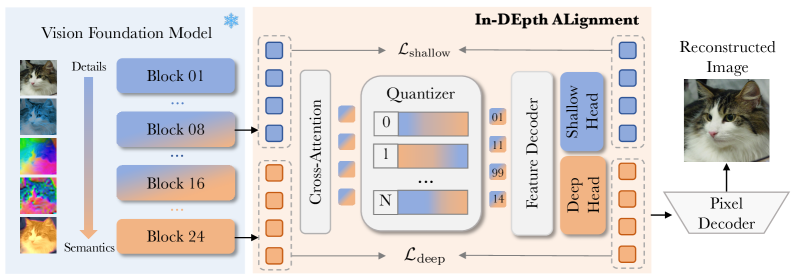
Figure 2 — Ideal 프레임워크 구조
4. Conclusion & Impact (결론 및 시사점)
본 연구는 VFM 기반의 이산 표현 자동 인코딩에서 의미론적 풍부함과 재구성 충실도를 동시에 달성하는 효율적인 솔루션을 제시하였습니다. Ideal은 단순히 특정 계층을 선택하는 기존 방식에서 벗어나, 계층 간의 상호보완적 특성을 전략적으로 결합함으로써 잠재 공간의 표현력을 극대화하였습니다. 이러한 결과는 고품질 이미지 생성을 위한 효율적이고 확장 가능한 토크나이저 설계에 새로운 방향성을 제공하며, 향후 더 다양한 도메인과 복합적인 시각 태스크로의 확장이 가능할 것으로 기대됩니다.

Figure 3 — 재구성 결과 시각화
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Next Forcing: Causal World Modeling with Multi-Chunk Prediction
- [논문리뷰] FadeMem: Distance-Aware Memory Consolidation for Autoregressive Video Diffusion
- [논문리뷰] VideoMLA: Low-Rank Latent KV Cache for Minute-Scale Autoregressive Video Diffusion
- [논문리뷰] SOCO: Benchmarking Semantic Object Correspondence in Vision Foundation Models
- [논문리뷰] Representation Forcing for Bottleneck-Free Unified Multimodal Models
Review 의 다른글
- 이전글 [논문리뷰] High-Fidelity Two-Step Image Generation via Teacher-Aligned End-to-End Distillation
- 현재글 : [논문리뷰] IDEAL: In-DEpth ALignment Makes A Discrete Representation AutoEncoder
- 다음글 [논문리뷰] InterleaveThinker: Reinforcing Agentic Interleaved Generation
댓글