[논문리뷰] EvalVerse: Pipeline-Aware and Expert-Calibrated Benchmarking for Professional Cinematic Video Generation
링크: 논문 PDF로 바로 열기
저자: Songlin Yang, Haobin Zhong, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- EvalVerse: 전문 영화 비디오 생성을 위한
pipeline-aware하고expert-calibrated된 포괄적인 평가 프레임워크를 의미한다. - Pipeline-Aware Cinematic Taxonomy: EvalVerse에서 제안하는 평가 분류 체계로, 전문 영화 제작 워크플로우(
Pre-Production,Production,Post-Production)를 구조적인 진단 렌즈로 활용한다. - Expert-Calibrated Chain-of-Thought (CoT) Evaluator: 전문 영화 전문가들의 판단을
Vision-Language Models (VLMs)에 주입하여,VLM이 전문가 수준의 추론과 스코어링을 수행할 수 있도록 인간-기계 교정(human-machine calibration)을 통해 개발된 평가 모델이다. - "Rightness" vs. "Goodness": 기존 벤치마크들이 "프롬프트 팔로잉(
prompt-following)" 능력과 시각적 요소의 존재 여부("whether it is right")를 평가하는 반면, "Goodness"는 영화적 품질, 연기, 미학 등 미묘한 요소를 포괄하는 전문적인 수준의 평가 기준("whether it is good")을 의미한다. - Human-Machine Alignment: EvalVerse의 자동화된 평가 지표가 전문 인간 전문가들의 지각 및 판단과 얼마나 일관되게 일치하는지를 나타내는 정도이다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 generative video foundation models의 빠른 발전으로 professional-grade cinematic synthesis에 대한 수요가 증가함에 따라, Reinforcement Learning (RL) 및 agentic workflows로의 전환에 필요한 신뢰할 수 있는 평가의 bottleneck 문제를 해결하고자 한다. 기존 벤치마크들은 주로 basic prompt-following 능력인 "whether it is right"만을 평가하며, 영화적 품질, 연기, 미학 등 전문적인 cinematic quality인 "whether it is good"의 평가를 근본적으로 간과하는 "Right vs. Good Objective Gap에 직면해 있다. 또한, 현재 automated metrics는 domain-specific rigor가 부족하여 인간의 미학적 인지와 기계적 스코어링 간의 심각한 credibility gap을 야기하고 있다. 이러한 methodological하고 credibility gap은 전문가 human assessment는 expensive하고 unscalable하며, generic Vision-Language Models (VLMs)은 professional rigor가 부족하다는 평가 paradox`를 초래한다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
EvalVerse는 비디오 생성 평가를 주관적인 영화적 전문 지식의 체계적인 디지털화 문제로 접근하며, pipeline-aware cinematic taxonomy와 expert-calibrated Chain-of-Thought (CoT) evaluator를 통해 이러한 문제를 해결한다. 본 프레임워크는 전문 영화 제작 워크플로우를 구조적인 진단 렌즈로 활용하여 Pre-Production, Production, Post-Production의 3단계로 구분되는 포괄적인 평가 Taxonomy를 제안한다 [cite: 1, Figure 2]. 이 Taxonomy는 7가지 영화적 측면, 18가지 주요 Dimension, 45가지 Sub-dimension, 그리고 196가지 Granular Rationale을 포함하여 cinematic "goodness"를 구조적으로 정의한다 [cite: 1, Figure 1]. Real-to-Gen 데이터 엔진을 통해 대규모의 professional database에서 diversified, proportional sampling을 수행하여 multi-modal inputs를 위한 test pairs를 구성하며, Gemini 3.1 Pro 및 Nano Banana Pro를 활용하여 professional-grade test prompts와 high-fidelity reference images를 생성한다 [cite: 1, Figure 3]. 제안하는 Machine Evaluation Suite는 VLMs의 fine-grained temporal tracking 및 low-level perception 한계를 완화하기 위해 DINO, InsightFace, YOLO, SyncNet, Whisper와 같은 specialized operators를 통해 deterministic evidence (Perception Prior)를 추출한 후, Expert-Guided CoT Reasoning을 수행하는 Fine-tuned VLM으로 구성된다. VLM Fine-Tuning은 pairwise comparisons 기반의 Preference Alignment (Bradley-Terry ranking loss 최소화)와 pointwise dataset 기반의 Score Calibration (Cross-Entropy loss 최소화 및 CoT rationale 생성)의 Two-stage Paradigm을 통해 이루어진다. 실험 결과, EvalVerse는 Text-to-Video (T2V) 및 Reference-to-Video (R2V) 설정에서 Seedance 2.0, Kling-v3-Omni, Happy Horse 1.0 등 주요 video generation models의 overall performance를 cinematography, aesthetics, acting, sound-related dimensions 등 다양한 fine-grained criteria에 걸쳐 평가하여 명확한 hierarchical distribution을 보여준다 [cite: 1, Figure 4, Figure 5, Figure 6]. 특히, Seedance 2.0은 soundscape fidelity, identity preservation, visual quality, camera control 등에서 가장 뛰어난 comprehensive performance를 달성했으며, Kling-v3-Omni와 Happy Horse 1.0이 그 뒤를 이었다. EvalVerse의 automated metrics는 human expert evaluations와 strong correlation을 보였다. 예를 들어, Visual Concept Design의 Scene dimension에서 Spearman Rank Correlation Coefficient (SRCC) +0.8082 및 Pearson Linear Correlation Coefficient (PLCC) +0.8224를 기록했으며, Acting의 Expression dimension에서는 SRCC +0.8276 및 PLCC +0.7872를 달성하는 등 대부분의 sub-dimensions에서 consistently high alignment를 입증했다 [cite: 1, Table 4, Figure 7].
## 4. Conclusion & Impact (결론 및 시사점)
본 연구는 EvalVerse를 통해 비디오 생성 평가 패러다임을 basic prompt-following인 "whether it is right"에서 professional filmmaking의 rigorous audit인 "whether it is good"으로 근본적으로 재정의했다. Real-world pipeline을 구조적으로 반영하고 systematic human-machine calibration mechanism을 제안함으로써, 미묘한 인간 선호도를 algorithmic scoring에 주입하는 principled framework를 제공한다. 이는 주관적인 전문가 지식을 계산 가능한 metric으로 성공적으로 디지털화하여, human aesthetic perception과 machine evaluation 사이의 credibility gap을 해소한다. EvalVerse는 단순한 static leaderboard를 넘어 Reinforcement Learning을 위한 dense, expert-aligned reward vectors와 autonomous agentic workflows를 위한 explainable diagnostic feedback을 제공함으로써 post-SFT era의 foundational infrastructure를 구축한다. 궁극적으로 이 연구는 generative models이 passive clip generators에서 professional-grade virtual directors로 전환되는 데 기여하며, computable cinematography의 새로운 시대를 여는 중요한 촉매제가 될 것으로 기대된다.
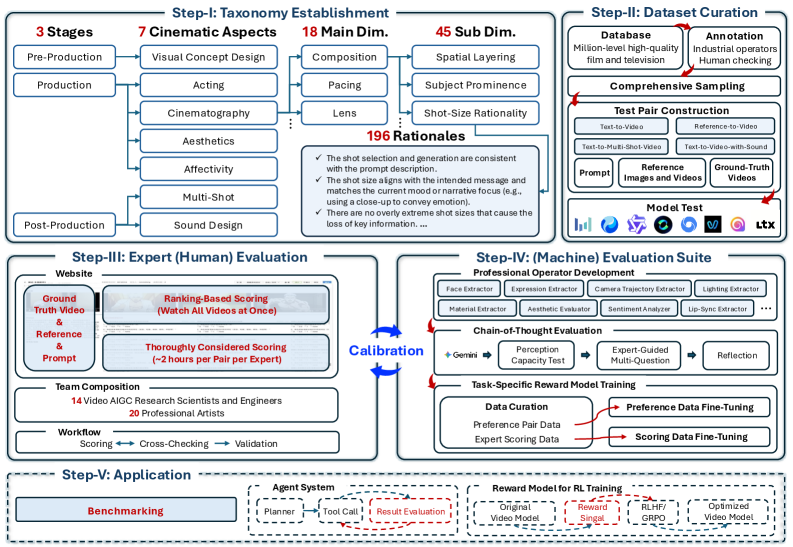
Figure 1 — EvalVerse의 전체 개요
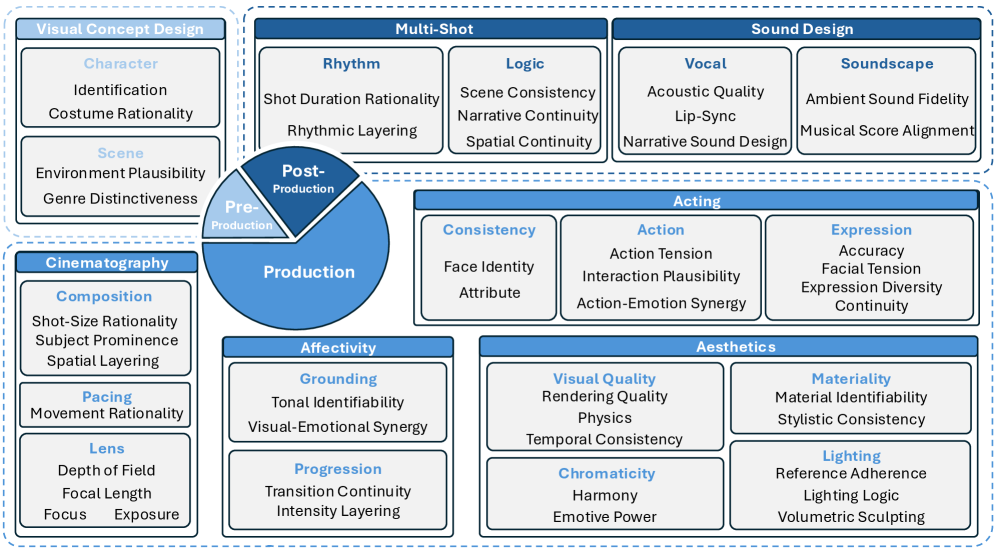
Figure 2 — 파이프라인 인지 평가 Taxonomy
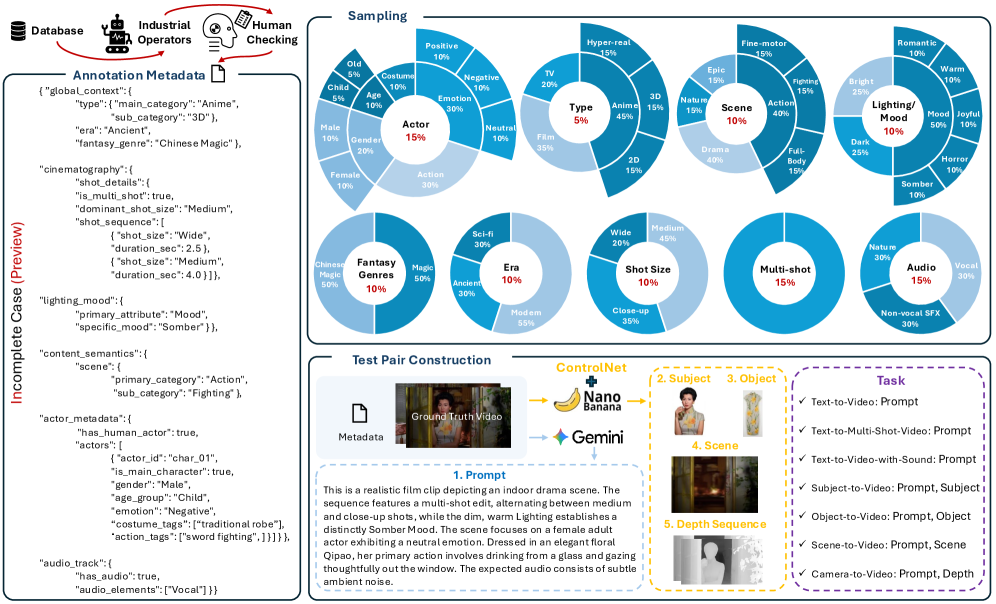
Figure 3 — 데이터셋 구축 파이프라인
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ThinkRL-Edit: Thinking in Reinforcement Learning for Reasoning-Centric Image Editing
- [논문리뷰] MentalThink: Shaping Thoughts in Mental SVG World
- [논문리뷰] Perceive-to-Reason: Decoupling Perception and Reasoning for Fine-Grained Visual Reasoning
- [논문리뷰] Xiaomi-GUI-0 Technical Report
- [논문리뷰] The Hitchhiker's Guide to Agentic AI: From Foundations to Systems
Review 의 다른글
- 이전글 [논문리뷰] D^2-Monitor: Dynamic Safety Monitoring for Diffusion LLMs via Hesitation-Aware Routing
- 현재글 : [논문리뷰] EvalVerse: Pipeline-Aware and Expert-Calibrated Benchmarking for Professional Cinematic Video Generation
- 다음글 [논문리뷰] Geometry-Aware Representation Denoising for Robust Multi-view 3D Reconstruction
댓글