[논문리뷰] Geometry-Aware Representation Denoising for Robust Multi-view 3D Reconstruction
링크: 논문 PDF로 바로 열기
**저자:** Jin Hyeon Kim, Jaeeun Lee, Claire Kim, Kyoungjin Oh, Paul Hyunbin Cho, Jaewon Min, Yeji Choi, Jihye Park, Hyunhee Park, Minkyu Park, Seungryong Kim
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- **Multi-view 3D Reconstruction**: 여러 2D 이미지에서 3D 장면의 구조를 재구성하는 컴퓨터 비전의 핵심 문제로, 특히 피드포워드 모델을 통해 End-to-End로 Scene Geometry를 추론하는 접근 방식이 주목받고 있다.
- **Geometry-Aware Representation**: 3D 재구성 모델의 트랜스포머 기반 어텐션 메커니즘을 통해 학습되어 Cross-View 정보를 인코딩하고 Scene Geometry 추정에 최적화된 고차원 Feature Representation을 의미한다.
- **Representation Denoising**: 기존의 Pixel-Space 또는 VAE-based Latent Space에서 이미지 Restoration을 수행하는 대신, 3D 재구성 모델의 Geometry-Aware Feature Space에서 직접 Denoising을 수행하여 Geometric Fidelity를 보존하는 방법론이다.
- **Interpolated Flow Matching Loss**: Degraded Latent Representation 자체를 Source Distribution으로 활용하여 Gaussian Noise와 Degraded Input Distribution의 혼합에서 Denoising 프로세스를 초기화하는 Loss Function이다.
- **Attention Alignment Loss**: GARD Denoiser 내의 Global Attention Map을 Geometrically Consistent Correspondence Map에 명시적으로 정렬하여 Cross-View Correspondence 학습을 촉진하고 Reconstruction Accuracy를 향상시키는 Loss Function이다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의)
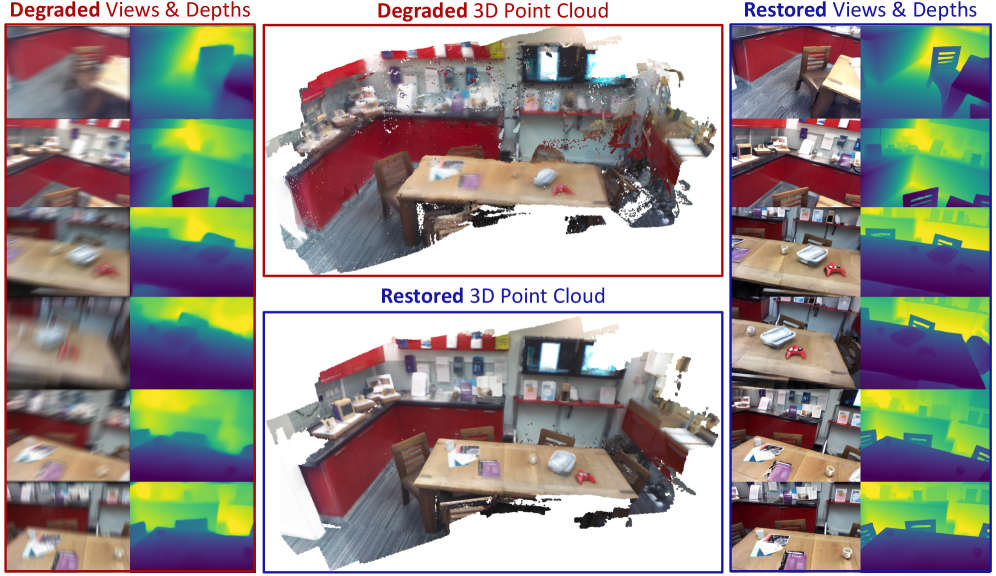
본 논문은 Degraded Input Condition 하에서 Multi-view 3D Reconstruction의 Robustness를 향상시키기 위해 Geometry-Aware Representation Denoising (GARD) 프레임워크를 제안한다. 기존 Feed-forward 3D Reconstruction 모델들은 이상적인 Degradation-free 환경에서 훈련되어 실제 환경의 Motion Blur와 같은 Degradation에 취약하며, 이는 Feature Extraction 및 Cross-View Matching의 신뢰성을 저해하여 Geometry Consistency를 붕괴시킨다. Restore-then-reconstruct 방식은 Single-view Restoration 모델이 Multi-view 정보를 활용하지 못하고 Cross-view Geometry Consistency를 강제할 수 없다는 한계가 있으며, VAE-based Latent Space는 Information Bottleneck으로 인해 Fine-grained Detail과 Geometric Fidelity를 보존하기 어렵다. 이러한 문제점들은 Degraded Multi-view Input에서 정확하고 일관된 3D Reconstruction 성능을 달성하는 데 주요한 도전 과제로 작용한다 [cite: 1, Figure 2].
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
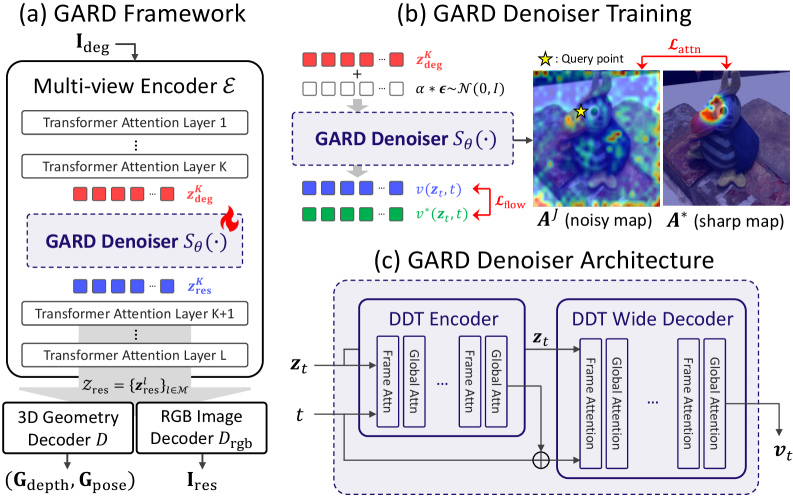
저자들은 Feed-forward 3D Reconstruction 모델의 Geometry-Aware Feature Space에서 직접 Denoising을 수행하는 Geometry-Aware Representation Denoising (GARD) 프레임워크를 제안한다 [cite: 1, Figure 1]. GARD는 Frozen Multi-view Encoder의 중간 Feature Representation에 Diffusion-based Multi-view Restoration Denoiser를 삽입하여 Degraded Feature를 Refine한다 [cite: 1, Figure 3]. 이 Denoiser는 DiT^DH^ 디자인을 기반으로 Frame-level Attention과 Global Cross-View Attention을 Interleave하여 Local Spatial Structure와 Cross-View Correspondence를 모두 학습한다. 훈련 시에는 Degraded Latent 자체를 Source Distribution으로 사용하는 **Interpolated Flow Matching Loss**와 Global Attention Map을 Geometrically Consistent Correspondence Map에 정렬하는 **Attention Alignment Loss**를 공동으로 최적화한다 [cite: 1, Figure 3].
실험 결과, GARD는 **Depth Anything 3 (DA3)** 벤치마크에서 기존 Single-view 및 VAE-based Multi-view Restoration Baseline들을 일관되게 능가하는 성능을 보였다. 특히, Camera Pose Estimation에서 LQ Input 대비 **AUC5**는 **HiRoom**에서 <strong>4.10%</strong>에서 <strong>12.00%</strong>로, **ETH3D**에서 <strong>16.72%</strong>에서 <strong>35.75%</strong>로, **ScanNet++**에서 <strong>34.55%</strong>에서 <strong>56.44%</strong>로 크게 향상되었다 [cite: 1, Table 1, Figure 5]. 3D Reconstruction에서는 **Overall** 지표 (낮을수록 좋음)에서 **HiRoom**의 **1.634**에서 **0.293**으로, **ETH3D**에서 **1.564**에서 **1.136**으로 개선되었으며, **F-score** 지표 (높을수록 좋음)는 **HiRoom**에서 <strong>11.74%</strong>에서 <strong>18.25%</strong>로, **ETH3D**에서 <strong>37.50%</strong>에서 <strong>45.79%</strong>로 향상되었다 [cite: 1, Table 2, Figure 6]. 이미지 Restoration 품질 측면에서도 **PSNR** (높을수록 좋음)은 **HiRoom**에서 **21.89**, **LPIPS** (낮을수록 좋음)는 **HiRoom**에서 **0.362**를 기록하며 Baseline 대비 우수한 결과를 달성했다 [cite: 1, Table 3, Figure 7]. 이는 Geometry-Aware Feature Space에서의 Restoration이 Visual Fidelity와 Structural Consistency를 효과적으로 보존함을 입증한다.
## 4. Conclusion & Impact (결론 및 시사점)
본 논문은 Degraded Multi-view Input으로부터 Robust한 3D Reconstruction 및 고품질 이미지 Restoration을 위한 Geometry-Aware Representation Denoising (GARD) 프레임워크를 성공적으로 제안하였다. GARD는 Feed-forward 3D Reconstruction 모델의 Geometry-Aware Feature Representation을 활용하여 Degraded Feature를 효과적으로 Refine하며, 이를 통해 정확한 3D Scene Geometry와 고품질 Multi-view RGB 이미지를 동시에 복구할 수 있다. 이 Representation-level Denoising 전략은 기존 Pixel-space 또는 VAE-based Latent-space Restoration 방식의 한계를 극복하고, Cross-view Consistency와 Fine-grained Structural Detail 보존에 탁월한 성능을 보인다. 이 연구는 Degraded Imaging Condition에서의 Multi-view 3D Reconstruction 분야에 새로운 접근 방식을 제시하며, 자율 주행, 로봇 공학, AR/VR 등 다양한 실제 응용 분야에서 신뢰성 있는 성능을 제공하는 데 크게 기여할 것으로 기대된다. 다만, Diffusion-based 방법론의 특성상 Iterative Denoising Step이 필요하므로 Latency-sensitive 환경에서의 효율성 개선이 향후 연구 방향으로 제시된다.
*Figure 1 — GARD 프레임워크 개요*

*Figure 2 — Denoising Space 비교*
*Figure 3 — GARD 프레임워크 상세*
> ⚠️ **알림:** 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] RealRestorer: Towards Generalizable Real-World Image Restoration with Large-Scale Image Editing Models
- [논문리뷰] DA-Flow: Degradation-Aware Optical Flow Estimation with Diffusion Models
- [논문리뷰] LightsOut: Diffusion-based Outpainting for Enhanced Lens Flare Removal
- [논문리뷰] MetaView: Monocular Novel View Synthesis with Scale-Aware Implicit Geometry Priors
- [논문리뷰] Hallo4D: Multi-Modal Hallucination Mitigation for Consistent Spatio-Temporal Generation
Review 의 다른글
- 이전글 [논문리뷰] EvalVerse: Pipeline-Aware and Expert-Calibrated Benchmarking for Professional Cinematic Video Generation
- 현재글 : [논문리뷰] Geometry-Aware Representation Denoising for Robust Multi-view 3D Reconstruction
- 다음글 [논문리뷰] LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding
댓글