[논문리뷰] Do not copy and paste! Rewriting strategies for code retrieval
링크: 논문 PDF로 바로 열기
메타데이터
저자: Andrea Gurioli, Federico Pennino, Maurizio Gabbrielli, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Code Information Retrieval (CIR): 코드, 자연어(NL) 질의, 혹은 이들의 하이브리드 형태를 입력으로 받아 소프트웨어 아티팩트를 검색하는 시스템 전반을 지칭합니다.
- Rewriting Strategy: LLM을 사용하여 질의(Query)나 코퍼스(Corpus)의 표현 방식을 정규화하거나 추상화 수준을 변경하여, 코드 인코더가 학습한 정보와 데이터 간의 정렬(Alignment)을 개선하는 기법입니다.
- QC (Query-Corpus) Augmentation: 검색 시 질의와 코퍼스 모두를 LLM으로 rewrite하는 온라인 방식의 증강 기법입니다.
- ΔH (Token Entropy Diagnostic): rewrite 전후의 입력 토큰 엔트로피 변화량으로, 인코더가 인식하는 문맥의 lexical diversity를 측정하여 검색 성능 향상 가능성을 예측하는 지표입니다.
- C (Corpus-only) Augmentation: 코퍼스만 오프라인에서 미리 rewrite하는 방식으로, 온라인 추론 비용을 절감하고자 하는 접근입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 코드 검색을 위한 기존의 임베딩 기반 기법들이 코드의 표면적인 문법적 특징에 과도하게 의존(Overfit)하여, 실제 의미론적 행동(Program behavior)을 파악하는 데 한계가 있다는 문제에서 출발합니다. 기존 연구들은 LLM을 활용한 코드 재구성을 통해 성능 향상을 꾀했으나, 어느 수준의 추상화(Abstraction level)가 가장 효과적인지, 그리고 온라인 LLM 호출이 매번 필요한지에 대한 정량적 분석이 부족합니다. 특히 재구성이 Retrieval 성능에 미치는 영향을 결정하는 핵심 요인이 명확하지 않아, 비용 효율적인 최적의 전략을 선택하는 데 어려움이 있습니다. 본 연구는 다양한 수준의 재구성(Stylistic rephrasing, NL-enriched PseudoCode, Full NL)을 체계적으로 비교 분석합니다 [Figure 1].
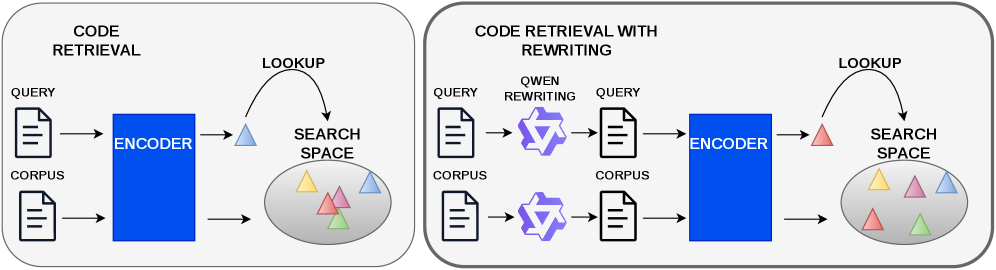
Figure 1 — 재구성 기반 검색 파이프라인
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 저자들은 세 가지 계층적 재구성 전략(Stylistic Rephrasing, NL-enriched PseudoCode, Full Natural-Language transcription)을 제안하며, 이들을 통해 인코더에 전달되는 표현의 추상화 수준을 변화시킵니다 [Figure 2]. 주요 실험 결과, NL+QC 방식이 코드 집약적 검색 환경(예: CT-Contest)에서 가장 강력한 성능을 발휘하였으며, MoSE-18 모델 기준 NDCG@10 수치를 기존 0.23에서 0.74로 +0.51만큼 비약적으로 향상시켰습니다 [Figure 3]. 반면, C(Corpus-only) 증강 방식은 질의와 코퍼스 간의 모달리티 불일치(Modality mismatch)로 인해 전체 설정의 약 62%에서 오히려 성능 저하를 보였습니다. 또한, 새로 제안된 진단 지표 ΔH는 QC 설정 하에서 Retrieval 성능 향상과 유의미한 양의 상관관계(pooled Spearman ρ=+0.436, p<0.001)를 보이며, 모델 패밀리에 상관없이 재구성의 효과를 예측하는 강력한 도구임을 입증하였습니다 [Table 4].
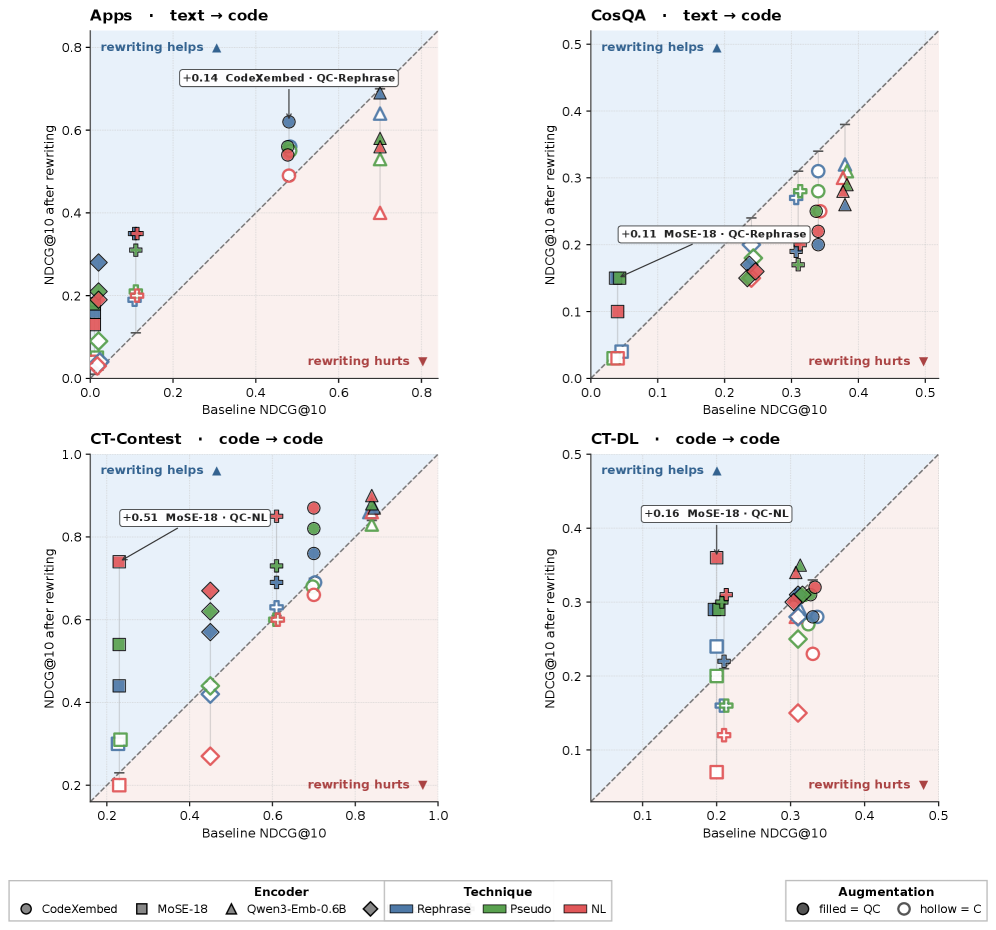
Figure 2 — 재구성 계층 구조 예시
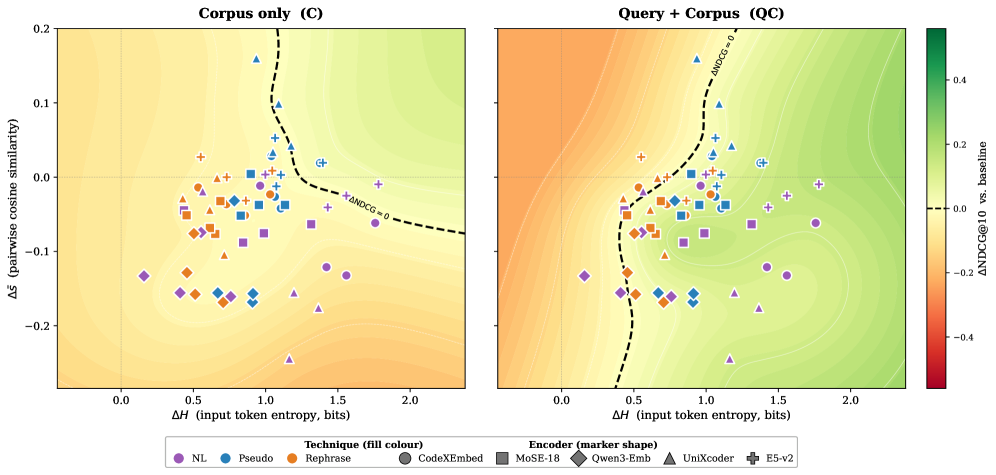
Figure 3 — 벤치마크별 검색 성능 비교
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 LLM 기반의 재구성 전략이 단순한 성능 향상 도구를 넘어, 경량화된 인코더의 검색 성능을 보완하는 remediating layer로서 매우 효과적임을 입증했습니다. 특히 검색 성능을 사전에 예측할 수 있는 ΔH 지표를 도입함으로써, 실무자들이 비용 대비 효율적인 재구성 전략을 사전에 선택할 수 있는 가이드라인을 제시했습니다. 본 연구의 결과는 향후 코드 검색 시스템 구축 시 컴퓨팅 자원과 검색 성능 사이의 트레이드오프를 최적화하는 데 중요한 학계 및 산업적 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] PluraMath: Extending Mathematical Reasoning Evaluation Beyond High-Resource Languages
- [논문리뷰] Hierarchical Sparse Attention Done Right: Toward Infinite Context Modeling
- [논문리뷰] PraMem: Practice-derived Experiential Memory for Long-horizon Behavior Prediction
- [논문리뷰] KVpop -- Key-Value Cache Compression with Predictive Online Pruning
Review 의 다른글
- 이전글 [논문리뷰] Continual Harness: Online Adaptation for Self-Improving Foundation Agents
- 현재글 : [논문리뷰] Do not copy and paste! Rewriting strategies for code retrieval
- 다음글 [논문리뷰] From Web to Pixels: Bringing Agentic Search into Visual Perception
댓글