[논문리뷰] TrajLoom: Dense Future Trajectory Generation from Video
링크: 논문 PDF로 바로 열기
The paper is "TrajLoom: Dense Future Trajectory Generation from Video" by Hang Chu, Ming Liang, Kaiwen Liu, Jia Jun Cheng Xian, Zewei Zhang et al.
Here's a plan for the summary:
Part 1: Summary
- Authors: Extract from the paper.
- Keywords: Based on abstract and main sections:
Dense Trajectory Generation,Future Motion Prediction,Video Understanding,Flow Matching,Variational Autoencoder,Spatiotemporal Consistency,On-policy Fine-tuning,Grid-Anchor Offset Encoding. - 1. Key Terms & Definitions:
- Dense Trajectory Generation : Predicting the future paths of numerous points across a video.
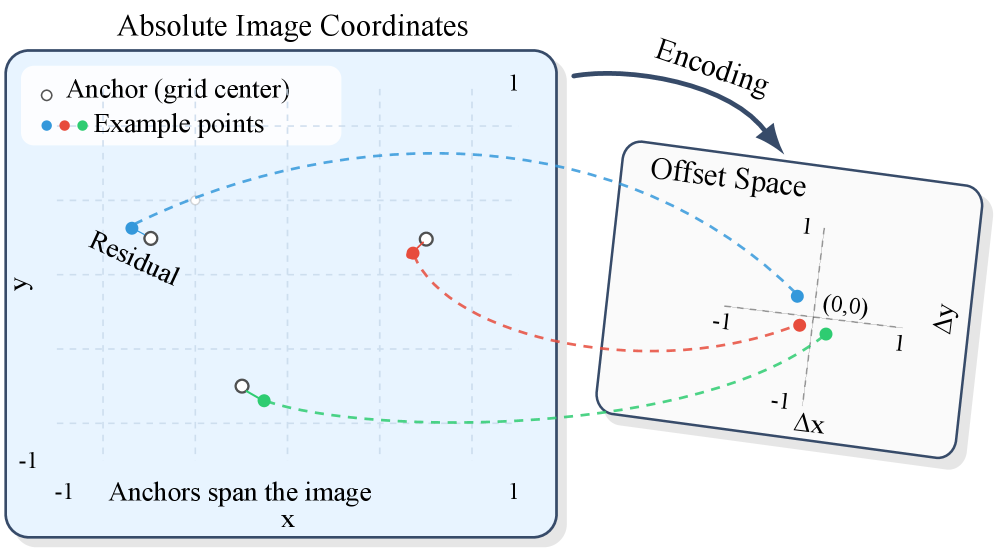
- Grid-Anchor Offset Encoding : Representing a point's location as an offset from its pixel-center anchor.
- TrajLoom-VAE : A Variational Autoencoder designed to learn a compact spatiotemporal latent space for dense trajectories.
- TrajLoom-Flow : A rectified-flow model for generating future trajectories in the latent space.
- Spatiotemporal Consistency Regularizer : A regularization term used in TrajLoom-VAE to enforce temporal smoothness and local spatial coherence in reconstructed trajectories.
- On-policy K-step Fine-tuning : A fine-tuning mechanism for TrajLoom-Flow to reduce train-test mismatch during ODE integration.
- 2. Motivation & Problem Statement:
- Future motion prediction is critical for video understanding and controllable video generation.
- Dense point trajectories are expressive but challenging to model for future evolution from observed video.
- Existing methods like WHN primarily rely on appearance cues, overlooking explicit motion history and its constraints.
- Representing dense trajectories using absolute image coordinates couples motion with global position, leading to location-dependent biases and instability.
- Challenges include maintaining temporal stability and local coherence over long forecast windows in diverse real-world videos.
- 3. Method & Key Results:
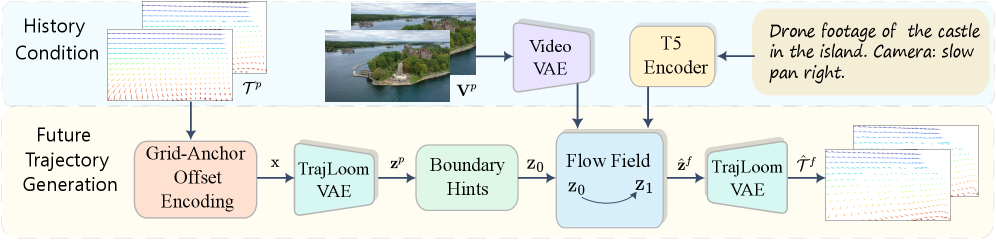
- Methodology: The proposed TrajLoom framework has three components.
- Grid-Anchor Offset Encoding : Each point is represented as an offset from its pixel-center anchor, reducing location-dependent bias. This encoding transforms absolute coordinates into a more uniform representation focused on local displacement.
- TrajLoom-VAE : A VAE learns a compact spatiotemporal latent space for trajectory segments. It employs masked reconstruction and a spatiotemporal consistency regularizer to ensure temporal smoothness and local coherence, which is crucial as pointwise reconstruction alone is insufficient. The regularizer includes both a temporal velocity term and a multiscale spatial neighbor term.
- TrajLoom-Flow : A rectified-flow model generates future trajectories in the latent space, conditioned on observed trajectories and video. It incorporates boundary hints for continuity with observed history (boundary-anchored initialization of z₀ and token-aligned history fusion). To mitigate train-test mismatch during ODE integration, on-policy K-step fine-tuning is applied.
- Key Results:
- TrajLoom significantly outperforms the state-of-the-art WHN (L) method on various datasets ( Kinetics , RoboTAP , Kubric , MagicData (E) ).
- FVMD is reduced by 2.5 to 3.6x (e.g., from 4872 to 1338 on Kubric), indicating improved motion realism.
- FlowTV and DivCurlE metrics are also substantially lower, signifying fewer spatial discontinuities and more stable motion. For instance, on Kubric, FlowTV decreases from 12.56 to 6.03 and DivCurlE from 9.89 to 2.09 .
- TrajLoom-VAE achieves low VEPE (Visibility-masked Endpoint Error) for reconstruction (e.g., 0.75 on Kubric for 81 frames), outperforming WHN (L)-VAE by a large margin (e.g., 16.27 on Kubric for 81 frames) and maintaining stability over long temporal windows (81 frames).
- Ablation studies confirm the effectiveness of Grid-Anchor Offset Encoding and the spatiotemporal consistency regularizer in improving performance and stability.
- Methodology: The proposed TrajLoom framework has three components.
- 4. Conclusion & Impact:
- The TrajLoom framework successfully addresses challenges in dense future-trajectory generation by integrating novel encoding, VAE-based latent space learning with consistency regularization, and a flow-matching generator with fine-tuning.
- It achieves superior performance over existing methods in motion realism, temporal consistency, and stability, extending prediction horizons from 24 to 81 frames.
- This research provides a strong foundation for downstream applications such as motion-controlled video generation and editing , enabling more precise and coherent temporal dynamics in synthetic videos.
- Future work aims to enhance trajectory controllability and further integrate the model with motion-guided generation tools.
Part 2: Figure Information
I will look for:
- Figure 2: Overview of the pipeline (architecture/framework).
- Figure 3: Grid-Anchor Offset Encoding explanation.
- Figure 5 or Figure 8 (Qualitative Results / Comparisons): Key results showing performance.
Let's find the src attribute for the image URLs.
Figure 1: 2603.22606v1/x1.png
Figure 2: 2603.22606v1/x2.png
Figure 3: 2603.22606v1/x3.png, 2603.22606v1/x4.png (Figure 3 is composed of (a) and (b), I'll pick (a) as the primary image for the encoding). Let's use the first part of Figure 3 which is the diagram.
Figure 5: 2603.22606v1/x6.png
Figure 6: 2603.22606v1/x7.png
I will choose Figure 2 (pipeline), Figure 3a (Grid-Anchor Offset Encoding), and Figure 5 (Qualitative results). 저자: Hang Chu, Ming Liang, Kaiwen Liu, Jia Jun Cheng Xian, Zewei Zhang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Dense Trajectory Generation : 비디오 내 다수의 포인트에 대한 미래 경로를 예측하는 기술.
- Grid-Anchor Offset Encoding : 각 포인트의 위치를 해당 픽셀-중심 앵커로부터의 오프셋으로 표현하여, 절대 좌표의 위치 종속적 편향을 줄이는 인코딩 방식.
- TrajLoom-VAE : dense trajectory를 위한 compact spatiotemporal latent space를 학습하는 Variational Autoencoder.
- TrajLoom-Flow : TrajLoom-VAE가 학습한 latent space에서 future trajectory를 생성하는 rectified-flow 모델.
- Spatiotemporal Consistency Regularizer : TrajLoom-VAE에서 재구성된 trajectory의 temporal smoothness와 local spatial coherence를 강화하기 위한 정규화 항.
- On-policy K-step Fine-tuning : ODE integration 과정에서 발생하는 train-test mismatch를 줄이기 위해 TrajLoom-Flow에 적용되는 fine-tuning 메커니즘.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Future motion prediction은 video understanding과 controllable video generation에 있어 매우 중요합니다. Dense point trajectory는 압축적이고 표현력이 풍부한 motion representation이지만, 관찰된 비디오로부터 이들의 미래 변화를 모델링하는 것은 여전히 challenging한 문제입니다. 기존 연구인 What Happens Next? (WHN) 와 같은 방법론은 주로 appearance cues에 의존하며, explicit motion history가 제공하는 강력한 제약 조건을 간과하는 한계가 있습니다. 또한, dense trajectory를 absolute image coordinates로 표현하는 대부분의 방식은 motion을 global position과 결합시켜 location-dependent한 통계를 유발하고 불안정성을 초래합니다. Diverse real-world video에서 장기적인 예측 window에 걸쳐 temporal stability와 local coherence를 유지하는 것이 주요 도전 과제입니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 비디오의 관찰된 history로부터 dense future trajectory를 생성하기 위한 프레임워크인 TrajLoom 을 제안합니다. 이 방법론은 세 가지 핵심 구성 요소로 이루어져 있습니다: 첫째, Grid-Anchor Offset Encoding 은 각 포인트를 픽셀-중심 앵커로부터의 오프셋으로 표현하여 location-dependent bias를 줄입니다. 이는 절대 좌표를 사용하는 방식에서 발생하는 위치 기반 분산을 크게 감소시켜, local displacement에 초점을 맞춘 보다 균일한 representation을 제공합니다. [Figure 3(a)] 둘째, TrajLoom-VAE 는 dense trajectory segment를 compact spatiotemporal latent space로 압축하고 재구성하는 Variational Autoencoder입니다. 이 VAE는 masked reconstruction과 더불어 spatiotemporal consistency regularizer 를 적용하여 temporal smoothness와 local coherence를 강화합니다. 이는 pointwise reconstruction loss만으로는 temporal jitter나 local spatial inconsistency를 충분히 제어할 수 없다는 문제점을 해결합니다. 셋째, TrajLoom-Flow 는 TrajLoom-VAE가 학습한 latent space에서 미래 trajectory를 생성하는 rectified-flow 모델입니다. 이는 observed trajectory와 video context에 conditioned되며, future prediction이 과거 관찰과 일관되도록 boundary hints (boundary-anchored initialization of z₀ 및 token-aligned history fusion)를 활용합니다. 또한, 학습 시 사용되는 interpolated states와 ODE integration을 통한 추론 시 발생하는 train-test mismatch를 줄이기 위해 on-policy K-step fine-tuning 을 적용합니다.
TrajLoom 은 TrajLoomBench 벤치마크 (Kinetics, RoboTAP, Kubric, MagicData (E) 포함)에서 state-of-the-art 방법인 WHN (L) 대비 뛰어난 성능을 보였습니다. 정량적 결과에 따르면, TrajLoom 은 FVMD (Fréchet Video Motion Distance)를 2.5 에서 3.6배 까지 감소시켜 motion realism을 크게 향상시켰습니다. 예를 들어, Kubric 데이터셋에서 FVMD 는 4872 에서 1338 로 줄어들었습니다. 또한, FlowSmoothTV (FlowTV) 와 DivCurlEnergy (DivCurlE) 지표도 현저히 낮아져, spatial tearing 감소 및 motion stability 향상을 입증했습니다. Kubric에서 FlowTV 는 12.56 에서 6.03 으로, DivCurlE 는 9.89 에서 2.09 로 개선되었습니다. TrajLoom-VAE 는 24프레임 및 81프레임 trajectory segment 재구성에서 WHN (L)-VAE 대비 월등히 낮은 VEPE (Visibility-masked Endpoint Error)를 달성했으며 (예: Kubric 81프레임에서 WHN (L)-VAE 는 16.27 , TrajLoom-VAE 는 0.75 ), 긴 temporal window에서도 안정적인 성능을 유지했습니다. [Table 1], [Table 2]
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Grid-Anchor Offset Encoding , consistency-regularized TrajLoom-VAE , 그리고 explicit boundary cues와 on-policy fine-tuning이 적용된 rectified-flow generator인 TrajLoom-Flow 를 결합한 dense future-trajectory generation 프레임워크를 제안합니다. 이러한 구성 요소들의 통합을 통해 TrajLoom 은 장기적인 예측 window에서 안정적이고 일관된 motion을 생성하며, TrajLoomBench에서 state-of-the-art 방법을 정량적 및 정성적으로 능가하는 성능을 보였습니다.

이 연구는 trajectory prediction horizon을 기존 24프레임에서 81프레임으로 확장하고 motion realism과 stability를 개선함으로써, motion-controlled video generation 및 editing 과 같은 downstream applications에 강력한 기반을 제공합니다. 향후 연구에서는 trajectory controllability를 개선하고, motion-guided generation 및 editing 방법론과의 통합을 더욱 강화하여 versatility와 accuracy를 높일 계획입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] The Principles of Diffusion Models
- [논문리뷰] RynnWorld-4D: 4D Embodied World Models for Robotic Manipulation
- [논문리뷰] Perceptual Flow Matching for Few-Step Generative Modeling
- [논문리뷰] InternVLA-A1.5: Unifying Understanding, Latent Foresight, and Action for Compositional Generalization
- [논문리뷰] WorldDirector: Building Controllable World Simulators with Persistent Dynamic Memory
Review 의 다른글
- 이전글 [논문리뷰] ThinkJEPA: Empowering Latent World Models with Large Vision-Language Reasoning Model
- 현재글 : [논문리뷰] TrajLoom: Dense Future Trajectory Generation from Video
- 다음글 [논문리뷰] Uncertainty-guided Compositional Alignment with Part-to-Whole Semantic Representativeness in Hyperbolic Vision-Language Models
댓글