[논문리뷰] ThinkJEPA: Empowering Latent World Models with Large Vision-Language Reasoning Model
링크: 논문 PDF로 바로 열기
The paper "ThinkJEPA: Empowering Latent World Models with Large Vision-Language Reasoning Model" has been browsed.
Now I will extract the required information and format it according to the user's instructions.
Part 1: Summary
- Authors: Mingfei Chen, Tushar Nagarajan, Shwai He, Yijiang Li, Haichao Zhang, Jianglin Lu, Ang Li, Yun Fu. (Will list the first few "et al.")
- Keywords: Need to identify 5-8 from the paper, focusing on standard academic terms.
- Key Terms & Definitions: JEPA, VLM, Dual-Temporal Perception Field, Hierarchical Pyramid Representation Extraction, FiLM.
- Motivation & Problem Statement: Current JEPA limitations (limited temporal perspective, weak semantic grounding). VLM benefits but also limitations (compute-driven sparsity, language-output bottleneck, data regime mismatch).
- Method & Key Results: ThinkJEPA's dual-temporal pathway, VLM thinker branch, JEPA branch, hierarchical pyramid representation extraction, layer-wise guidance injection via FiLM. Quantitative results from tables (ADE, FDE, Acc, FD, SL1, CD). Comparisons to baselines (Qwen3-VL Thinking (VLM-only), V-JEPA Predictor (JEPA-only), other trajectory baselines).
- Conclusion & Impact: Summarize main findings and implications.
- Figure Citations: Need to ensure Figure 1 and Figure 2 are cited after the relevant sentences. Table 1, 2, 3, 4, 5 are also available. I will target Figure 1 and Figure 2.
Part 2: Important Figure Information (JSON)
- Select up to 3 figures. Figure 1 (architecture) and Figure 2 (qualitative results) are good candidates.
- Find
image_urlfor each. - Create
caption_kr.
Let's gather the specific details for each section.
Authors: Mingfei Chen, Tushar Nagarajan, Shwai He, Yijiang Li, Haichao Zhang, et al.
Keywords: Latent World Models, Vision-Language Models, Predictive Representation Learning, Dual-Temporal Sampling, Semantic Guidance, Trajectory Prediction, Egocentric Video, JEPA
Figure URLs:
- Figure 1: Overall Architecture of ThinkJEPA.
src="2603.22281v1/x1.png"->https://arxiv.org/html/2603.22281v1/x1.png - Figure 2: Qualitative results.
src="2603.22281v1/x2.png"->https://arxiv.org/html/2603.22281v1/x2.png
Now I will structure the response. 저자: Mingfei Chen, Tushar Nagarajan, Shwai He, Yijiang Li, Haichao Zhang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Latent World Model (LWM) : 환경의 미래 상태를 예측하기 위해 학습된 추상적인 표현 공간에서 예측을 수행하는 모델로, 고해상도 픽셀이나 3D 기하학적 정보를 직접 생성하는 대신 Representation Space에서 다이내믹스를 모델링한다.
- Vision-Language Model (VLM) : 대규모 이미지-텍스트 데이터를 사용하여 시각 및 텍스트 모달리티를 정렬함으로써 멀티모달 Representation Learning에서 뛰어난 성능을 보이는 모델.
- JEPA (Joint-Embedding Predictive Architecture) : 예측 목적을 통해 Representation을 학습하여 모델이 Motion Patterns 및 Physical Interactions와 같은 고수준 구조를 Capture하도록 장려하는 접근 방식.
- Dual-Temporal Perception Field Sampling : ThinkJEPA에서 VLM thinker branch를 위한 Uniform Sampling과 JEPA branch를 위한 Dense Sampling을 통해 서로 다른 Temporal Context 요구사항을 충족시키는 디자인.
- Hierarchical Pyramid Representation Extraction : VLM의 Visual Encoder에서 얻은 Visual Tokens와 선택된 Language Model Layer의 Intermediate Hidden States를 결합하여 Multi-depth VLM 신호를 집계하는 모듈.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Latent World Models, 특히 V-JEPA2와 같은 JEPA-style 모델은 비디오 Observation으로부터 미래 World States를 예측하는 데 유망한 능력을 보여왔다. 그러나 기존 JEPA-style Latent World Models는 두 가지 주요 한계에 직면한다: 첫째, Prediction을 위한 Temporal Perspective가 제한적이다. 대부분의 접근 방식은 densely sampled frames의 짧은 Observation Window에 의존하여 미래 latents를 예측하는데, 이는 Long-horizon Semantics 및 Event-level Cues를 Capture하기 어렵게 만든다. 둘째, Semantic Grounding 및 General Knowledge Alignment가 약하다. Latent Space는 주로 Self-supervised Visual Representation Learning을 통해 학습되어 Motion-sensitive Features를 생성하지만, Open-vocabulary Concepts 및 Compositional Knowledge와의 Alignment가 제한적이다.
반면 Vision-Language Models (VLMs)는 Large-scale Pretraining 및 Multimodal Alignment를 통해 High-level Video Understanding 및 Reasoning에서 뛰어난 성능을 보인다. 하지만 VLMs를 Standalone Dense Predictors로 직접 사용하는 것은 Compute-driven Sparsity, Language-output Bottleneck, 그리고 Data Regime Mismatch 문제로 인해 비효율적이다. 즉, VLMs는 Long-horizon Context와 General Knowledge를 제공하지만, Dense Dynamics Prediction에는 적합하지 않으며, 기존 JEPA 모델은 Fine-grained Dynamics를 잘 포착하지만 Long-horizon Semantic Context가 부족하다. 따라서 저자들은 이러한 상호 보완적인 강점을 결합하여 Latent World Modeling을 개선할 필요성을 제기한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 ThinkJEPA를 제안하는데, 이는 VLM-guided JEPA-style Latent World Modeling Framework로, Dense-frame Dynamics Modeling과 Long-horizon Semantic Guidance를 Dual-temporal Pathway를 통해 통합한다. 이 프레임워크는 (i) Fine-grained Motion 및 Interaction Cues를 위한 Dense JEPA Branch와 (ii) Knowledge-rich Guidance를 위한 Large Temporal Stride를 가진 Uniformly Sampled VLM thinker Branch로 구성된다
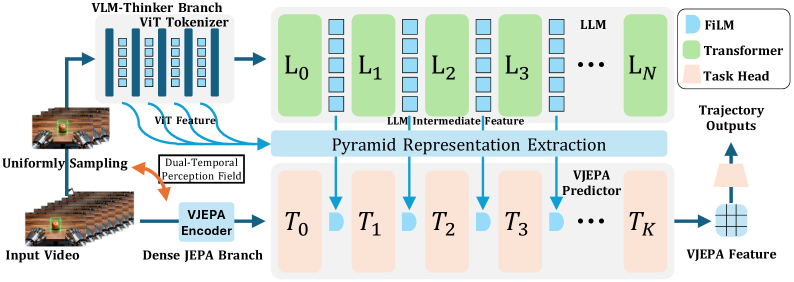
VLM thinker branch는 Qwen3-VL (Thinking)을 사용하며, Hierarchical Pyramid Representation Extraction Module을 통해 Multi-layer VLM Representation을 JEPA Predictor와 호환되는 Guidance Features로 집계하여 VLM의 Progressive Reasoning Signals을 효과적으로 전달한다. 추출된 Thinker Guidance는 Feature-wise Linear Modulation (FiLM)을 통해 JEPA Predictor에 Layer-wise로 주입된다.
ThinkJEPA는 EgoDex 및 EgoExo4D 데이터셋에서 손 조작 궤적 예측(Hand-manipulation Trajectory Prediction) 실험을 통해 그 우수성을 입증했다. Quantitative Comparison 결과, ThinkJEPA는 Trajectory Prediction에서 Baseline Model들을 일관되게 능가했다. 예를 들어, EgoDex에서 ThinkJEPA는 ADE(Average Displacement Error) 0.061 , FDE(Final Displacement Error) 0.056 , Accuracy 0.596 를 달성하여 V-JEPA Predictor (ADE 0.071 , FDE 0.066 , Accuracy 0.471 ) 및 Qwen3-VL Thinking (ADE 0.142 , FDE 0.144 , Accuracy 0.084 )보다 우수한 성능을 보였다 [Table 1]. EgoExo4D에서도 유사하게 V-JEPA Predictor 대비 ADE 0.622 (vs 0.659 ), FDE 0.597 (vs 0.636 ), Accuracy 0.171 (vs 0.074 )로 향상된 성능을 보여주었다 [Table 1].
또한, Ablation Study를 통해 Hierarchical Pyramid Extraction의 중요성이 확인되었다. Last-layer 또는 Mid-layer Guidance 단독으로는 ThinkJEPA의 전체 성능에 미치지 못했으며, Multi-depth VLM Layer를 모두 활용했을 때 최적의 결과를 얻었다 [Table 4]. Recursive Rollout 평가에서는 ThinkJEPA가 모든 Horizon에서 가장 뛰어난 성능을 보였으며, Long-horizon Prediction에서 Error Accumulation을 효과적으로 완화하고 예측 안정성을 높였다 [Table 5]. 특히, Rollout Horizon이 증가할수록 VLM-thinker Guidance의 이점이 더욱 두드러졌다. 정성적 결과(Qualitative Results)에서도 ThinkJEPA는 더 부드럽고 Temporal Consistency가 뛰어난 궤적을 예측했다

4. Conclusion & Impact (결론 및 시사점)
본 연구는 Long-horizon Semantic Reasoning을 제공하는 Vision-Language thinker와 Dense Latent Dynamics Forecasting을 통합한 VLM-guided JEPA-style Latent World Modeling Framework인 ThinkJEPA를 제안한다. ThinkJEPA의 Dual-temporal Perception Design과 Layer-wise Modulation을 통한 Pyramid-extracted Multi-depth VLM Representation 주입은 Latent Forecasting Interface를 유지하면서 Knowledge-aware Guidance를 통해 예측을 강화한다.
EgoDex 및 EgoExo4D 벤치마크에서의 광범위한 실험은 ThinkJEPA가 Representation-level Forecasting Quality와 Downstream Performance 모두에서 기존 Strong VLM Baseline (Qwen3-VL (Thinking)) 및 V-JEPA Predictor Baseline을 능가하며, Long-horizon Rollout Behavior에서 Robust함을 입증했다. 이 연구는 Latent World Models의 Semantic Grounding 및 Generalization 능력을 크게 향상시키며, 향후 Embodied Tasks 및 더욱 다양한 Interaction Scenarios에 대한 확장 가능성을 제시한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] SiamJEPA: On the Role of Siamese Student Encoders in JEPA
- [논문리뷰] Rank-Then-Act: Reward-Free Control from Frame-Order Progress
- [논문리뷰] Transition-Aware best-of-N sampling for Longitudinal Chest X-ray Reports
- [논문리뷰] DataComp-VLM: Improved Open Datasets for Vision-Language Models
- [논문리뷰] AGE: Adaptive-masking for Graph Embedding in Graph Retrieval-Augmented Generation
Review 의 다른글
- 이전글 [논문리뷰] SpecEyes: Accelerating Agentic Multimodal LLMs via Speculative Perception and Planning
- 현재글 : [논문리뷰] ThinkJEPA: Empowering Latent World Models with Large Vision-Language Reasoning Model
- 다음글 [논문리뷰] TrajLoom: Dense Future Trajectory Generation from Video
댓글