[논문리뷰] SpecEyes: Accelerating Agentic Multimodal LLMs via Speculative Perception and Planning
링크: 논문 PDF로 바로 열기
This is the end of the article. 저자: Rongrong Ji, Xiawu Zheng, Zhongwei Wan, Jinfa Huang, Haoyu Huang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agentic Multimodal Large Language Models (MLLMs) : 시각적 도구 호출을 반복적으로 수행하여 복잡한 추론 작업을 처리하는 모델을 지칭합니다.
- Agentic Depth (D) : 단일 쿼리에 대해 순차적으로 발생하는 지각, 추론 및 도구 호출 단계의 수를 나타냅니다.
- Speculative Perception and Planning : 경량의 도구-없는(tool-free) MLLM을 사용하여 실행 궤적을 예측하고, 값비싼 도구 체인의 조기 종료를 가능하게 하는 개념입니다.
- Cognitive Gating : 모델의 자체 검증(self-verification) 신뢰도를 정량화하기 위해 Answer Separability를 기반으로 하는 메커니즘입니다.
- Answer Separability (S_sep) : Top-K logits 내에서 최상위 예측과 경쟁 후보들 사이의 결정 마진을 측정하는 Metric으로, Small MLLM의 신뢰도 스위칭에 사용됩니다.
- Heterogeneous Parallel Funnel : Small 모델의 무상태 동시성(stateless concurrency)을 활용하여 Large 모델의 상태 저장 직렬 실행(stateful serial execution)을 마스킹하고 시스템 Throughput을 최대화하는 아키텍처입니다.
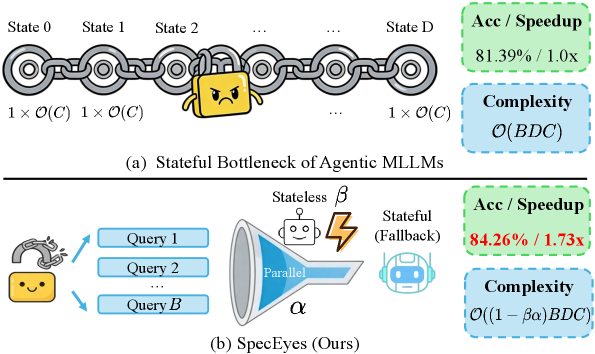
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 Agentic MLLMs는 반복적인 시각적 도구 호출을 통해 탁월한 추론 능력을 보여주지만, Perception, Reasoning, Tool-calling의 캐스케이드(cascaded) 루프가 심각한 순차적 오버헤드를 발생시킵니다 [cite: 1, Figure 1]. 이러한 오버헤드는 "Agentic Depth"로 명명되며, End-to-End Latency를 비례적으로 증가시키고, 각 쿼리의 Tool-use Chain이 상태(state)를 변경하기 때문에 GPU Batching을 무효화하여 시스템 수준의 Concurrency를 심각하게 제한하는 문제를 야기합니다. 결과적으로, Agentic MLLMs는 Non-agentic 모델보다 현저히 느려지며, 이는 실제 배포에 근본적인 장벽이 됩니다. 기존의 Token-level speculative decoding이나 Multimodal token pruning과 같은 효율성 개선 접근 방식들은 고정된 추론 궤적 내에서 작동하며, Agentic 루프 자체의 순차적 병목 현상을 해결하지 못합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
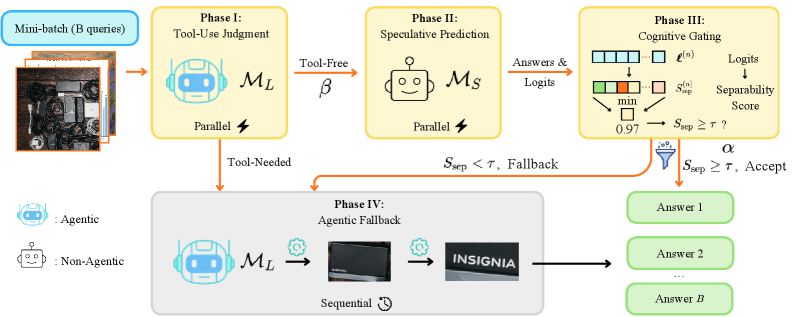
저자들은 Agentic MLLMs의 효율성 위기를 해결하기 위해 Speculative 패러다임을 Token 수준에서 Agentic 수준으로 끌어올린 SpecEyes 프레임워크를 제안합니다. SpecEyes는 쿼리가 실제로 심층적인 Tool-assisted reasoning을 필요로 하지 않는 경우, 경량의 Tool-free MLLM(M_S)을 활용하여 전체 Tool-use loop를 우회합니다. SpecEyes는 네 단계의 파이프라인으로 구성됩니다 [cite: 1, Figure 2]:
- Heuristic Tool-Use Judgment (Phase I) : Large Agentic MLLM(
M_L)이 쿼리(q)와 이미지(I)를 분석하여 Tool 호출의 필요성을 판단합니다. Tool이 필요 없다고 판단되면 Phase II로, 필요하다고 판단되면 Phase IV(Agentic Fallback)로 즉시 전달됩니다. - Speculative Prediction (Phase II) : Phase I을 통과한 Tool-free 쿼리들에 대해 Small Non-agentic MLLM(
M_S)이 직접 추측성 답변(hat{y}_S)과 Logit 분포를 생성합니다. 이 과정은 Stateless하며, Batch 내 모든 쿼리에 대해 동시에 수행될 수 있습니다. - Small MLLM Confidence Switching (Phase III) : Phase II에서 생성된 Logits는 새로운
answer separabilityScore인S_sep를 사용하여cognitive gating메커니즘을 통해 모델의 신뢰도를 평가합니다.S_sep가 임계값(τ) 이상이면 추측성 답변이 수락되고, 그렇지 않으면 Phase IV로 Fallback됩니다.minaggregation 전략은S_sep의 Discriminability를 최대화하여 최적의 Accuracy-Speed Trade-off를 제공합니다 [cite: 1, Figure 3]. - Agentic Fallback (Phase IV) : 신뢰도 스위칭에 실패하거나 Tool이 필요한 쿼리는 전체 Agentic MLLM(
M_L)으로 전달되어 완전한 상태 저장(stateful) Perception-Reasoning Loop를 실행합니다.
실험 결과, SpecEyes는 DeepEyes 백본에서 평균 1.73x 의 Speedup을 달성하면서 평균 Accuracy를 81.39%에서 84.26%로 향상 시켰습니다 [cite: 1, Table 1]. 특히 POPE 벤치마크에서는 2.13–2.19x 의 속도 향상과 함께 기준선보다 높은 Accuracy(예: Adversarial: 78.43% → 85.13% )를 보였으며, 이는 불필요한 Tool 궤적을 우회함으로써 환각(hallucination) 오류를 줄일 수 있음을 시사합니다. Thyme 백본에서도 SpecEyes는 평균 1.42x 의 Speedup과 함께 Accuracy를 82.29%에서 83.99%로 높여 일반화 성능을 입증했습니다 [cite: 1, Table 1]. 이는 SpecEyes가 Agentic 파이프라인의 전체 Accuracy를 유지하면서 Latency를 크게 줄이고 Throughput을 개선함을 보여줍니다.
4. Conclusion & Impact (결론 및 시사점)
이 논문에서 저자들은 Agentic MLLMs의 Stateful Bottleneck을 해결하기 위해 Agentic-level Speculative Acceleration Framework인 SpecEyes 를 제안했습니다. SpecEyes는 경량의 Tool-free 모델이 복잡한 Tool-use 없이도 답변할 수 있는 쿼리를 추측적으로 처리하고, answer separability 기반의 cognitive gating 메커니즘으로 신뢰도를 관리하며, heterogeneous parallel funnel을 통해 시스템 수준의 Throughput을 향상시킵니다 [cite: 1, Figure 2]. 다양한 Multimodal 벤치마크에서 SpecEyes는 최대 3.35x 의 Latency 감소와 함께 Agentic Baseline과 유사하거나 더 높은 Accuracy를 달성하며, 동시(concurrent) 서비스 환경에서 일관된 Throughput 개선을 제공합니다 [cite: 1, Table 1]. 이 연구는 Agentic MLLMs의 효율성 한계를 극복하여 실제 적용 가능성을 크게 높이는 데 기여하며, 향후 Multi-depth speculation과 같은 확장 연구를 통해 Tool Assistance가 필요한 쿼리에 대한 효율성을 더욱 개선할 수 있는 가능성을 제시합니다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] JetSpec: Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree Drafting
- [논문리뷰] Evaluating Temporal Semantic Caching and Workflow Optimization in Agentic Plan-Execute Pipelines
- [논문리뷰] Accelerating Diffusion via Hybrid Data-Pipeline Parallelism Based on Conditional Guidance Scheduling
- [논문리뷰] SeaCache: Spectral-Evolution-Aware Cache for Accelerating Diffusion Models
- [논문리뷰] DLLM-Searcher: Adapting Diffusion Large Language Model for Search Agents
Review 의 다른글
- 이전글 [논문리뷰] Sparse but Critical: A Token-Level Analysis of Distributional Shifts in RLVR Fine-Tuning of LLMs
- 현재글 : [논문리뷰] SpecEyes: Accelerating Agentic Multimodal LLMs via Speculative Perception and Planning
- 다음글 [논문리뷰] ThinkJEPA: Empowering Latent World Models with Large Vision-Language Reasoning Model
댓글