[논문리뷰] Sparse but Critical: A Token-Level Analysis of Distributional Shifts in RLVR Fine-Tuning of LLMs
링크: 논문 PDF로 바로 열기
The browsing was successful. Now I will process the content to extract the required information and generate the summary and figure JSON.
Part 1: Summary
Authors : Haoming Meng, Kexin Huang, Shaohang Wei, Chiyu Ma, Shuo Yang, Xue Wang, Guoyin Wang, Bolin Ding, Jingren Zhou et al.
Keywords : RLVR, LLMs, Token-Level Analysis, Distributional Shifts, Cross-Sampling, Sparse Refinement, Reasoning Trajectories
1. Key Terms & Definitions (핵심 용어 및 정의)
- RLVR (Reinforcement Learning with Verifiable Rewards) : LLM의 추론 능력을 향상시키기 위해 생성된 응답의 verifiable reward signal을 사용하여 최적화하는 Reinforcement Learning 패러다임입니다.
- Distributional Shifts : Base Model과 RL Fine-tuned Model 간의 next-token 예측 분포 차이를 의미하며, Jensen–Shannon (JS) divergence를 사용하여 정량화됩니다.
- Jensen–Shannon (JS) Divergence : 두 확률 분포 간의 유사성을 측정하는 대칭적인 지표로, KL Divergence와 달리 [0, log 2] 범위 내에 있으며, 분포 간의 절대 연속성이 없어도 잘 정의됩니다.
- Cross-Sampling : Base Model과 RL Model 간에 토큰 선택을 선택적으로 교환하여 token-level distributional shift가 sequence-level 추론 성능에 미치는 영향을 측정하는 실험 기법입니다. Forward Cross-Sampling과 Reverse Cross-Sampling 두 가지 방식이 있습니다.
- Advantage Signal : Reinforcement Learning에서 특정 행동이 기대치보다 얼마나 더 좋은지를 나타내는 값으로, 본 논문에서는 token-level advantages를 divergence magnitude에 따라 재조정하는 Divergence-Weighted Advantage를 탐색합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 RLVR(Reinforcement Learning with Verifiable Rewards)은 LLM의 추론 능력을 크게 향상시켰지만, 이러한 개선이 token-level에서 어떤 메커니즘으로 발생하는지에 대한 이해는 부족합니다. 기존 연구들은 주로 정확도, 보상, 응답 길이와 같은 response-level metrics에 초점을 맞춰 고수준의 개선 사항만 제공하며, 모델 동작이 어떻게 변화하는지에 대한 심층적인 통찰은 제한적이었습니다. 특히, RLVR이 base model의 token-level predictive distributions를 어떻게 재구성하고, 이러한 변화 중 어떤 부분이 실제 추론 성능 향상을 유도하는지에 대한 핵심적인 질문이 미해결 상태였습니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 RLVR이 base model 대비 next-token distributions를 어떻게 변화시키는지, 그리고 이러한 distributional shifts가 sequence-level 추론 성능에 직접적으로 어떻게 연결되는지에 대한 체계적인 empirical study를 수행했습니다.
주요 분석 방법론:
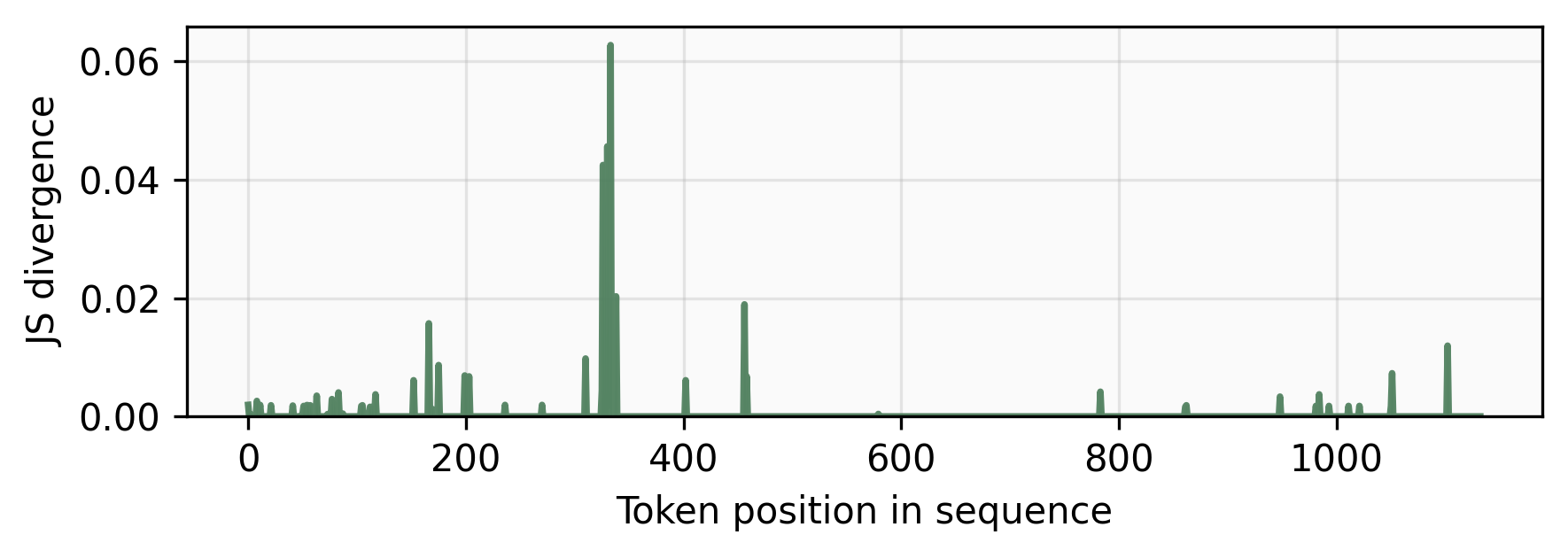
- Token-Level Distributional Shift 분석 : Jensen–Shannon (JS) divergence를 사용하여 base model과 RL model 간의 token-level 예측 분포 차이를 정량화했습니다. 이 분석은 동일한 sequence context에서 RL policy에 의해 생성된 sequence를 참조 경로로 삼아 두 모델의 조건부 분포를 비교합니다.
- Cross-Sampling Interventions : RL-sampled tokens를 base generation에 주입하는 Forward Cross-Sampling 과 base-sampled tokens를 RL generation에 주입하는 Reverse Cross-Sampling 을 통해 divergent token decisions의 기능적 중요성을 측정했습니다. 특정 JS divergence 임계값(ε)을 초과하는 위치에서만 토큰을 교환하며, 개입 예산(intervention budget)을 제한하여 초기 개입이 downstream 성능에 미치는 영향을 평가했습니다.
- Fine-Grained Distribution Mechanics : 높은 divergence를 보이는 위치에서 확률 mass가 어떻게 재할당되는지, 즉 새로운 후보 토큰을 도입하는지, 아니면 기존 토큰들 사이에서 우선순위를 재조정하는지를 Top-k Overlap 및 Rank Reordering , Low-Probability Token Behavior , Evolution Across Training 분석을 통해 탐구했습니다.
- Divergence-Weighted Advantage : Token-level learning signal을 divergence magnitude에 따라 조절하는 진단적 개입으로 Divergence-Weighted Advantage 를 탐색했습니다. 이는 advantages를 per-token divergence에 따라 재조정하는 방식입니다.
핵심 결과:
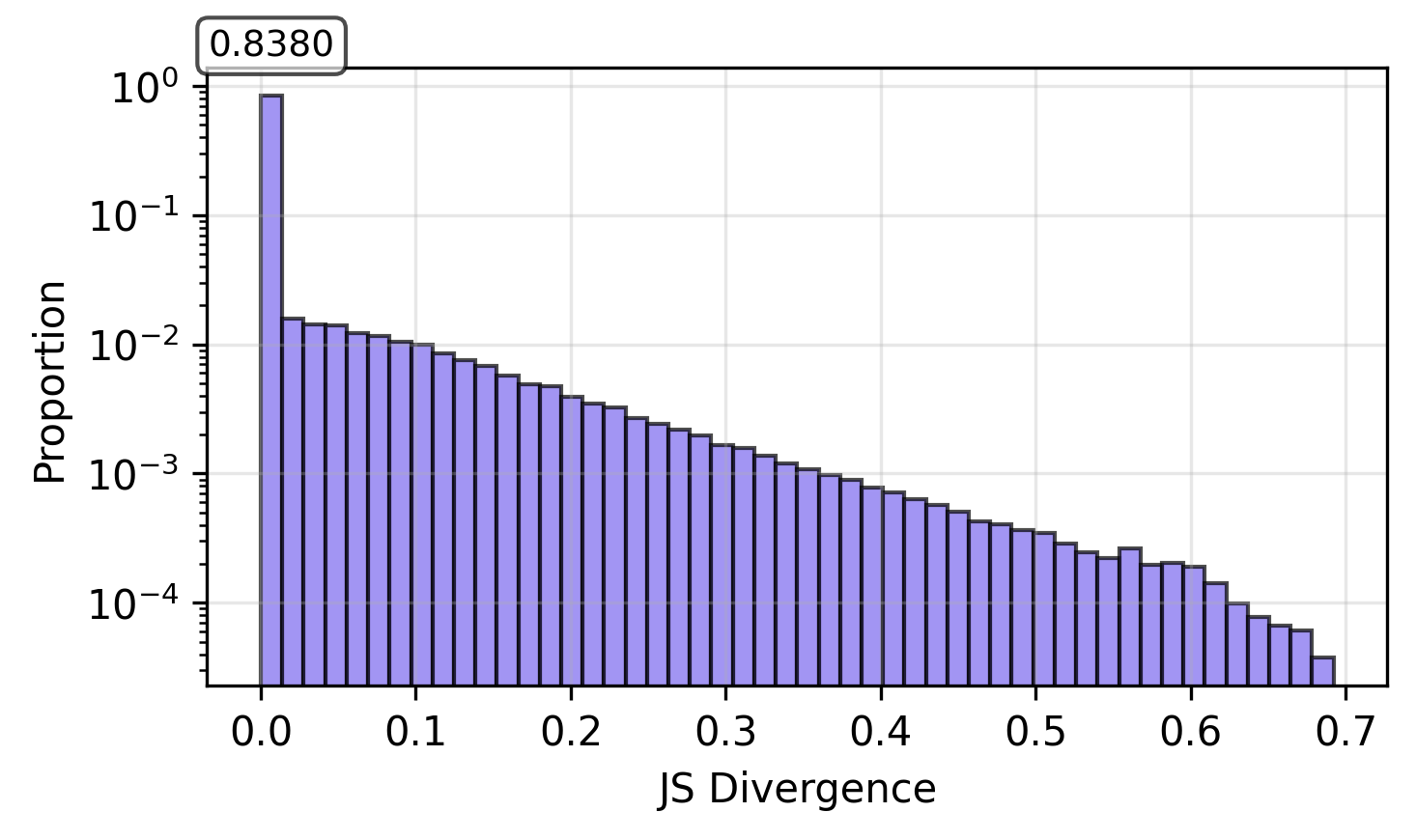
- 희소성(Sparsity) 및 표적화(Targeted Changes) : RL Fine-tuning은 매우 희소하고 표적화된(highly sparse and targeted) 변화를 유도하며, base policy와 RL policy 간의 토큰 분포에서 유의미한 divergence를 보이는 토큰은 전체 중 극히 일부(small fraction) 에 불과합니다. Qwen2.5 32B 모델의 경우, DAPO에서는 83% 이상, SimpleRL에서는 98% 이상의 토큰 위치에서 거의 zero divergence를 보였습니다.
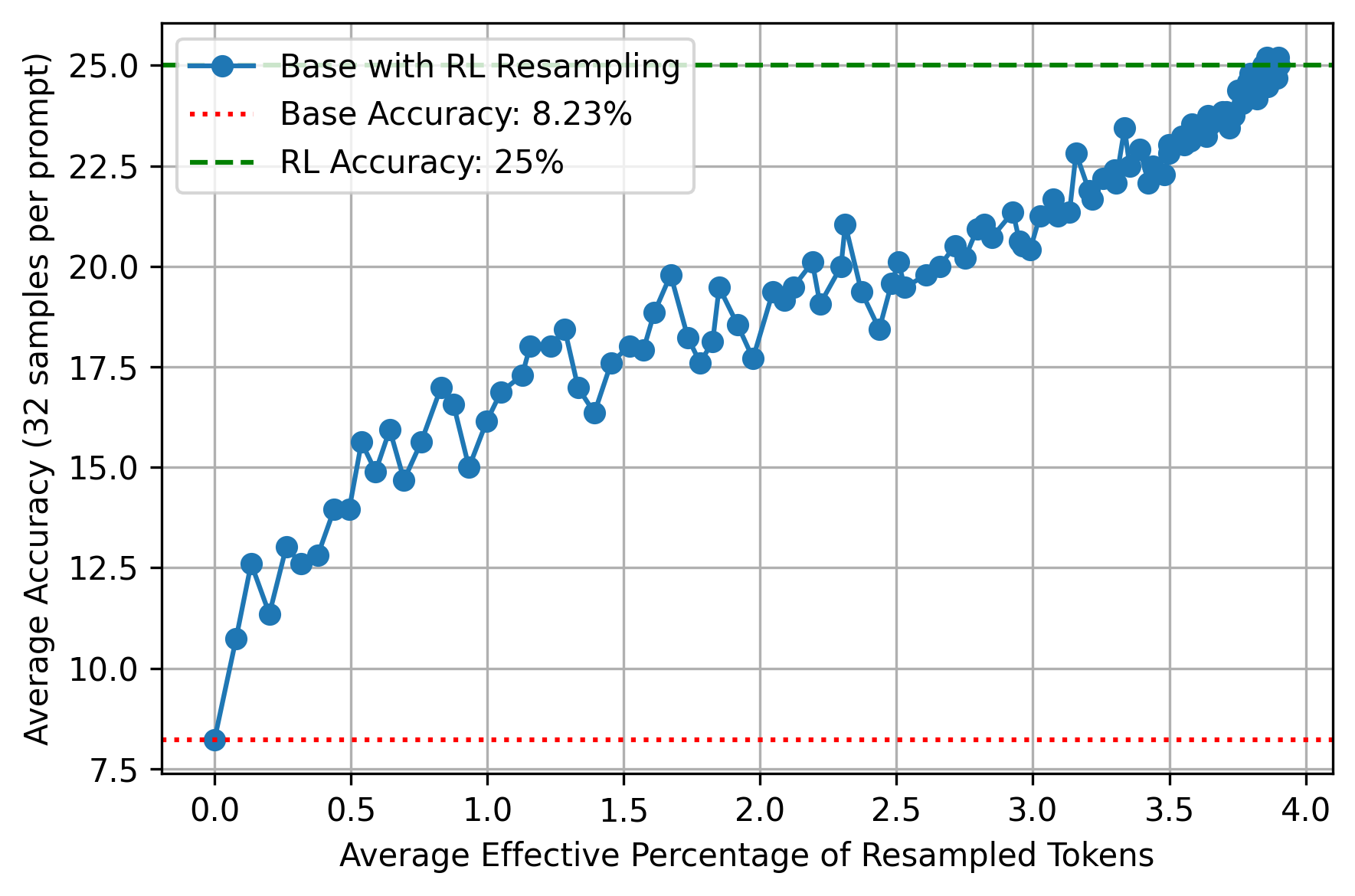
- 기능적 중요성(Functional Importance) : Cross-sampling 실험 결과, RL-sampled tokens의 적은 부분(small fraction) 만 base generation에 삽입해도 RL 성능 향상을 점진적으로 회복 시키는 반면, RL-generated sequence에 유사하게 적은 수의 base token choices를 주입하면 성능이 base model 수준으로 하락 하는 것으로 나타났습니다. 예를 들어, AIME 2024 데이터셋에서 SimpleRL의 경우 평균 4% 미만의 RL-sampled tokens 주입으로 약 8%에서 25%의 정확도 향상을 가져왔고, DAPO는 7.8%의 효과적인 토큰으로 약 8%에서 44% 이상으로 정확도를 높였습니다. [Figure 7], [Figure 8],
- 확률 재할당(Probability Reallocation) : Fine-grained 분석 결과, RLVR은 새로운 후보 토큰을 도입하기보다 기존 후보 집합 내에서 확률 mass를 재할당 하는 방식으로 작동합니다. 즉, base model에서도 이미 그럴듯한(plausible) 토큰들의 우선순위를 재조정하고 선택적으로 증폭시키며, low-probability tokens의 승격은 제한적입니다. Top-k Overlap 분석에서 k≥2일 때 base 및 RL 모델의 Top-k candidate set 간의 Overlap이 높게 유지되었습니다. [Figure 9]
- Divergence-Weighted Advantage의 효과 : Divergence-weighted advantages를 사용한 훈련은 baseline 대비 성능 향상 을 가져올 수 있음을 시사합니다. Low-KL boost와 High-KL boost 모두 Qwen2.5-Math-7B 모델에서 baseline DAPO(AIME24 33.61%, AIME25 18.75%, AMC 75.08%)보다 높은 성능을 보였습니다 (예: High-KL boost는 AIME24 36.74%, AIME25 20.00%, AMC 78.40%). [Table 2]
4. Conclusion & Impact (결론 및 시사점)
본 연구는 RLVR이 LLM을 광범위하게 변화시키는 것이 아니라, 희소하고 표적화된(sparse, targeted, and structured) 방식으로 토큰 분포를 재구성한다는 것을 밝혀냈습니다. 극히 일부의 토큰만이 유의미한 divergence를 겪으며, 이러한 divergence가 추론 성능 향상에 불균형적으로 중요한 기능적 역할(disproportionate functional importance) 을 한다는 것을 cross-sampling 개입을 통해 확인했습니다. Fine-grained 분석은 RLVR이 주로 기존 후보 집합 내에서 확률 mass를 재할당하여 동작을 세밀하게 조정하며, 새로운 토큰을 근본적으로 도입하는 경우는 드물다는 것을 시사합니다. 그러나 이러한 희귀한 re-ranking이나 low-probability tokens의 승격 사례 또한 추론 성능 개선에 중요할 수 있습니다. Divergence-weighted advantages에 대한 탐색은 토큰-레벨 학습 신호를 divergence에 따라 조절하는 것이 학습 역학에 긍정적인 영향을 미칠 수 있음을 보여줍니다.
이 연구는 RL Fine-tuning에 대한 token-level 이해를 증진시키고, RLVR 성공의 본질이 광범위한 분포 변화가 아닌 선택적 정제(selective refinements) 에 있음을 강조합니다. 이는 RLVR이 전역적인 정책 변화(global policy shift)가 아닌, 소수의 high-impact decision points에 대한 희소한 개입(sparse intervention) 으로서 생성 궤적을 조종한다는 관점을 제시합니다. 이러한 발견은 미래의 RL objective 및 진단 도구 설계에 distributional structure를 더욱 통합하여, 보다 효과적이고 해석 가능하며 제어 가능한 LLM post-training 방법을 개발하는 데 기여할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] SIMART: Decomposing Monolithic Meshes into Sim-ready Articulated Assets via MLLM
- 현재글 : [논문리뷰] Sparse but Critical: A Token-Level Analysis of Distributional Shifts in RLVR Fine-Tuning of LLMs
- 다음글 [논문리뷰] SpecEyes: Accelerating Agentic Multimodal LLMs via Speculative Perception and Planning
댓글