[논문리뷰] PRISM: Prior Rectification and Uncertainty-Aware Structure Modeling for Diffusion-Based Text Image Super-Resolution
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zihang Xu, Xiaoyang Liu, Zheng Chen, Yulun Zhang, Xiaokang Yang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- FMPR (Flow-Matching Prior Rectification): 저자들이 제안한 방법론으로, 학습 시 paired LQ/HQ 데이터를 사용하여 Privileged Prior를 구축하고, 이를 통해 열악한 입력에서도 신뢰할 수 있는 텍스트 토큰을 복원하는 기법입니다.
- SURE (Structure-guided Uncertainty-aware Residual Encoder): 저자들이 제안한 모듈로, 텍스트 이미지의 local 구조를 정교하게 조정하기 위해 구조적 잔차(residual control)를 생성하며, 특히 uncertainty-aware 학습을 통해 불확실한 텍스트 경계 정보를 선별적으로 반영합니다.
- BTL (Bilingual Text-line Corpus): 논문에서 학습을 위해 구축한 100K 규모의 bilingual 텍스트 라인 데이터셋으로, 기존의 리얼 텍스트 데이터와 합성 데이터를 조합하여 구성되었습니다.
- Privileged Conditional Prior: 학습 단계에서 paired LQ/HQ 데이터를 기반으로 정의되는 이상적인 텍스트-인식 조건으로, 모델이 Restoration을 위해 무엇을 참조해야 하는지 명확한 가이드라인을 제공합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 심각하게 훼손된 텍스트 이미지에서 기존의 Text-SR 방법론들이 보이는 한계점을 지적하며 연구를 시작합니다. 기존 연구들은 강력한 생성적 Prior를 사용하려 시도하지만, 심각하게 열악한 입력 환경에서는 이 Prior가 신뢰할 수 없는 노이즈가 되어 인식 오류를 발생시킵니다. 또한, 고수준의 의미론적 조건(condition)을 확보하더라도 fine-grained한 텍스트의 구조와 경계선을 정확히 복원하는 데 어려움을 겪습니다. 저자들은 이러한 문제의 원인이 restoration 과정과 조건 추정 과정이 얽혀 있는 구조적 결함에 있다고 보며, 이를 해결하기 위해 Prior를 명시적으로 복원하고 불확실성을 고려한 구조적 정제 과정을 분리하는 새로운 프레임워크인 PRISM을 제안합니다 [Figure 1].

Figure 1 — 구조적 오류 예시
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 PRISM을 제안하며, restoration을 FMPR을 통한 글로벌 Prior rectification과 SURE를 통한 로컬 구조 정제 단계로 명확히 분리합니다. FMPR은 Flow Matching 기법을 사용하여 열악한 임베딩 분포를 restoration 중심의 Privileged Prior 공간으로 운송(transport)함으로써, 단일 단계의 확산 모델 추론에서도 안정적인 텍스트 가이드를 제공합니다 [Figure 2], [Figure 3]. SURE는 로컬 구조 정제 단계에서 예측되는 경계선에 대해 uncertainty-aware 기법을 적용하여, 신뢰도가 낮은 구역은 모델이 무리하게 강제하지 않도록 설계되었습니다 [Figure 4].
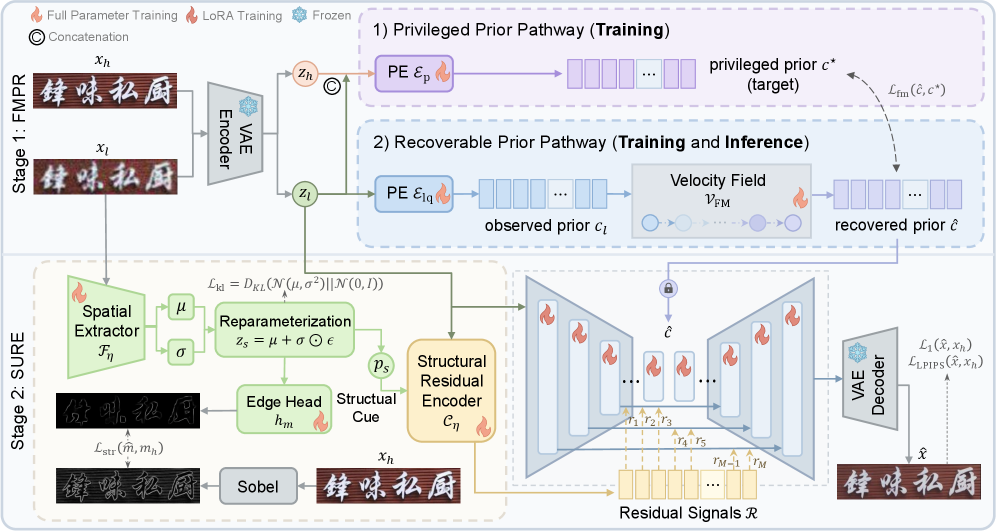
Figure 2 — PRISM 전체 구조
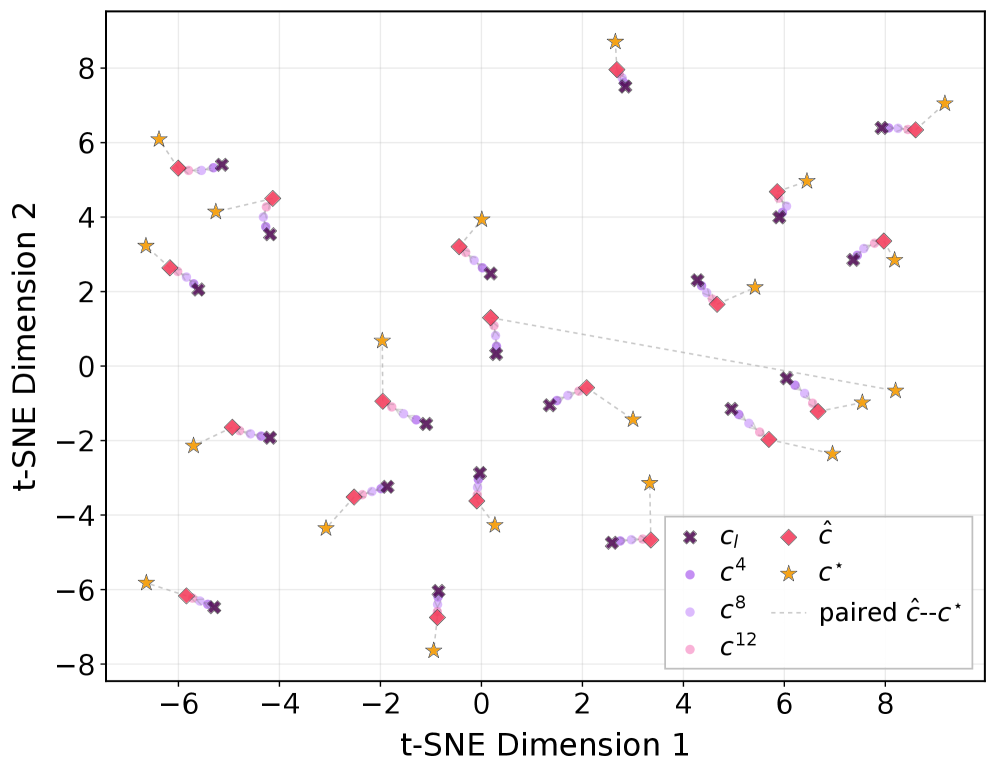
Figure 3 — FMPR 복원 궤적
정량적 평가 결과, 제안 모델은 BTL-test와 RealCE-val 데이터셋에서 기존의 최첨단 Text-SR 방법론들을 압도하는 성능을 보입니다. 특히, RealCE-val의 ×4 초해상도 설정에서 모델은 ACC(정확도)를 60.62%에서 65.19%로 개선하고, FID 지표를 74.52에서 47.83으로 크게 낮추어 훨씬 더 높은 distributional realism과 텍스트 충실도를 달성하였습니다 [Table 1]. 또한, 추론 과정에서 PRISM은 단일 단계 확산 추론을 사용하여 기존의 복잡한 iterative 방식 모델 대비 극적으로 빠른 millisecond-level inference 성능을 보입니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 PRISM을 통해 Text-SR 분야에서 텍스트 가이드의 신뢰성 문제와 로컬 구조의 모호성 문제를 성공적으로 해결하였습니다. Flow-based Prior Rectification과 구조적 Uncertainty-Awareness의 결합은 고품질의 텍스트 복원을 가능하게 하면서도 단일 단계 추론을 통한 높은 효율성을 보장합니다. 이 연구는 향후 OCR 전처리, 문서 복원 및 고도화된 실시간 텍스트 인식 응용 분야에서 핵심적인 기술적 기반을 제공할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] RynnWorld-4D: 4D Embodied World Models for Robotic Manipulation
- [논문리뷰] Perceptual Flow Matching for Few-Step Generative Modeling
- [논문리뷰] InternVLA-A1.5: Unifying Understanding, Latent Foresight, and Action for Compositional Generalization
- [논문리뷰] WorldDirector: Building Controllable World Simulators with Persistent Dynamic Memory
- [논문리뷰] Optimizing Visual Generative Models via Distribution-wise Rewards
Review 의 다른글
- 이전글 [논문리뷰] PREPING: Building Agent Memory without Tasks
- 현재글 : [논문리뷰] PRISM: Prior Rectification and Uncertainty-Aware Structure Modeling for Diffusion-Based Text Image Super-Resolution
- 다음글 [논문리뷰] PanoWorld: Towards Spatial Supersensing in 360^circ Panorama World
댓글