[논문리뷰] Steering Visual Generation in Unified Multimodal Models with Understanding Supervision
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zeyu Liu, Zanlin Ni, Yang Yue, Cheng Da, Huan Yang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- UMM (Unified Multimodal Model): 시각적 이해(Understanding)와 생성(Generation)을 단일 프레임워크 내에서 수행하도록 설계된 통합 멀티모달 모델을 지칭합니다.
- UNO (Understanding-Oriented Post-Training): 이해 중심의 지도(Supervision)를 통해 생성적 표현(Generative Representations)을 강화하는 저비용 사후 학습 프레임워크입니다.
- MetaQuery: 모델의 이해 전문가(Understanding expert) 내부에 삽입되는 학습 가능한 토큰으로, 생성 과정의 중간 잠재 표현을 통해 정밀한 시각적 특징을 회귀(Regression)하는 데 사용됩니다.
- Flow Matching: 최근 생성 모델에서 저수준(Low-level) 시각적 목표를 최적화하기 위해 널리 사용되는 생성 학습 목적 함수(Objective function)입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 최신 UMM이 이해와 생성 기능을 한 모델 내에 통합했음에도 불구하고, 실제로는 두 구성 요소가 상호작용 없이 분리된(Decoupled) 구조로 설계되어 성능 극대화에 한계가 있다는 문제를 지적합니다. 기존 모델들은 각 태스크의 독립적 성능을 유지하기 위해 표현 공간을 분리하는데, 이는 이해 전문가가 학습한 풍부한 의미론적 정보가 생성 전문가에게 효과적으로 전달되지 못하게 만듭니다 [Figure 3]. 결과적으로, 생성 전문가가 복잡한 지시 사항이나 세부적인 시각적 구조를 따르는 데 어려움을 겪는 현상이 발생합니다. 따라서 저자들은 이해 전문가가 생성 중인 시각적 표현에 직접 개입하여 생성 과정을 감독함으로써, 두 기능 간의 진정한 시너지(Capability synergy)를 회복하고자 합니다.
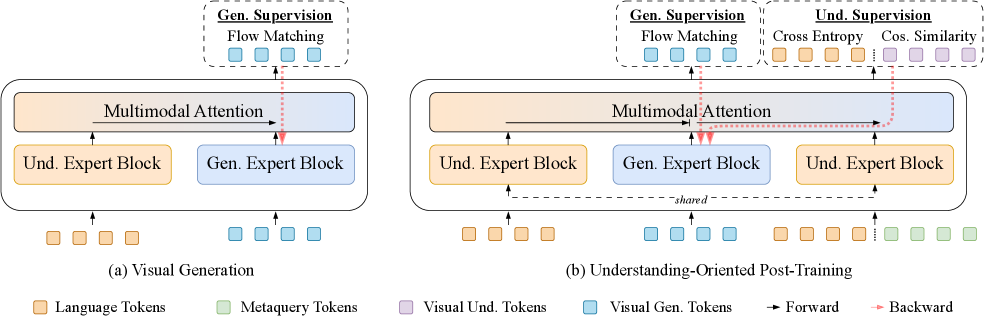
Figure 3 — UNO 학습 개념 및 흐름도
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 이해 전문가를 고정한 상태에서 생성 중인 노이즈가 포함된(Noised) 잠재 표현을 이해 전문가에게 주입하여 역방향 그래디언트 흐름(Backward gradient flow)을 생성 경로로 전달하는 UNO 프레임워크를 제안합니다 [Figure 3]. 구체적으로, 이해 전문가는 (i) 캡셔닝을 통한 언어 지도와 (ii) MetaQuery 토큰을 이용한 시각적 회귀 지도를 병행하여 생성 중인 표현을 다각도로 감독합니다. 이 과정에서 정보 누수를 방지하기 위해 프롬프트 토큰을 마스킹하고, 캡션 모델을 활용한 의미론적 증강(Semantic augmentation)을 수행합니다 [Figure 4].
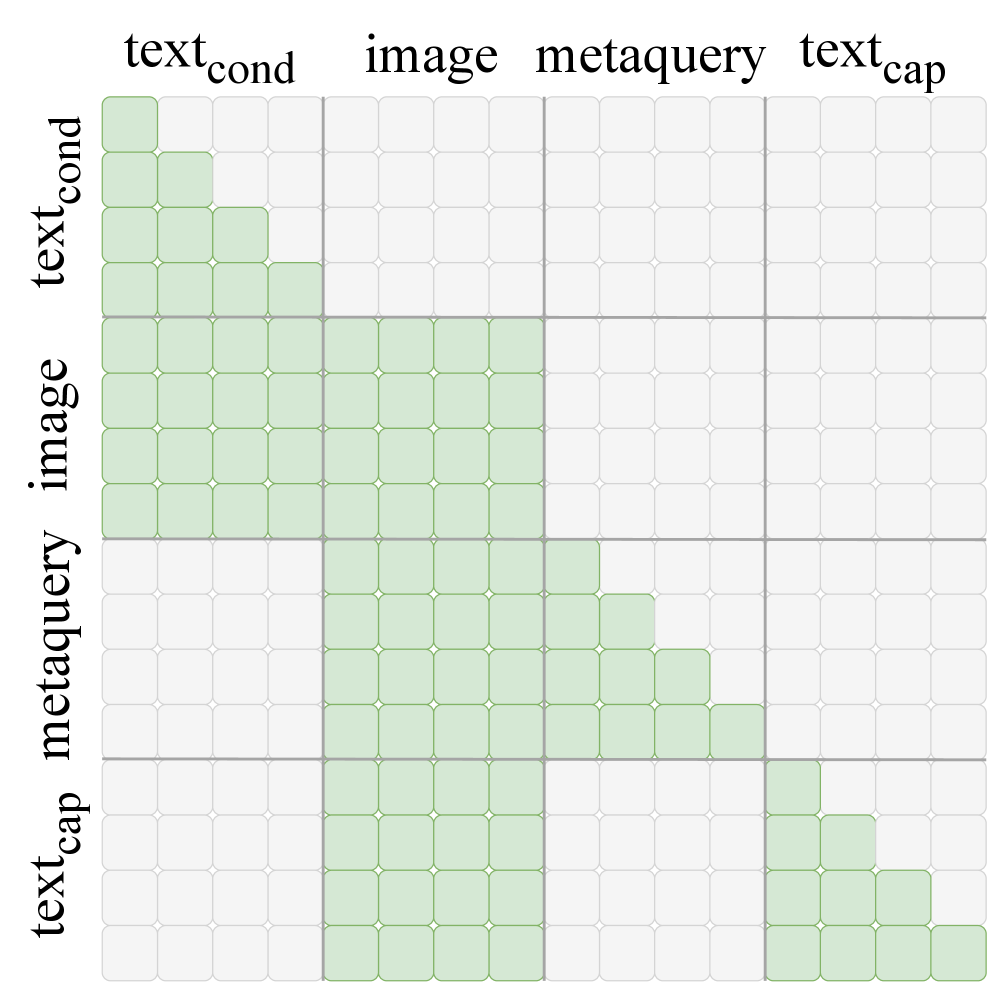
Figure 4 — 학습 시퀀스 및 어텐션 마스크
실험 결과, UNO는 BAGEL 베이스라인 대비 이미지 생성 및 편집 성능에서 일관된 우위를 점했습니다. 주요 지표인 GenEval2에서 71.7에서 75.1로, DPG-Bench에서 84.03에서 86.12로 성능이 향상되었습니다 [Table 2]. 특히 이미지 편집 태스크인 GEdit-Bench-EN에서도 전반적인 성능이 6.52에서 7.17로 상승하는 성과를 거두었습니다 [Table 3]. 정성적 분석을 통해 UNO로 학습된 모델이 노이즈가 많은 단계에서도 더 구조화되고 세밀한 시각적 표현을 생성함을 확인했습니다 [Figure 7].

Figure 7 — 잠재 피처 구조 시각화 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 UMM 내에서 이해 중심의 지도를 통해 생성적 표현을 체계적으로 강화하는 UNO를 성공적으로 도입했습니다. 이 프레임워크는 아키텍처의 복잡성을 가중하지 않으면서도 이해와 생성 간의 정보 흐름을 최적화하여 시너지를 창출할 수 있음을 입증했습니다. 이는 향후 UMM 설계 시 단순한 통합을 넘어 기능 간의 상호작용을 적극적으로 활용하는 더 깊게 통합된(Deeply integrated) 멀티모달 시스템 개발의 중요한 기술적 이정표가 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] TUNA: Taming Unified Visual Representations for Native Unified Multimodal Models
- [논문리뷰] RynnWorld-4D: 4D Embodied World Models for Robotic Manipulation
- [논문리뷰] Perceptual Flow Matching for Few-Step Generative Modeling
- [논문리뷰] InternVLA-A1.5: Unifying Understanding, Latent Foresight, and Action for Compositional Generalization
- [논문리뷰] WorldDirector: Building Controllable World Simulators with Persistent Dynamic Memory
Review 의 다른글
- 이전글 [논문리뷰] SpecBlock: Block-Iterative Speculative Decoding with Dynamic Tree Drafting
- 현재글 : [논문리뷰] Steering Visual Generation in Unified Multimodal Models with Understanding Supervision
- 다음글 [논문리뷰] UniPrefill: Universal Long-Context Prefill Acceleration via Block-wise Dynamic Sparsification
댓글