[논문리뷰] SpecBlock: Block-Iterative Speculative Decoding with Dynamic Tree Drafting
링크: 논문 PDF로 바로 열기
메타데이터
저자: Weijie Shi, Qiang Xu, Fan Deng, Yaguang Wu, Jiarun Liu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Speculative Decoding: 소형 모델(Drafter)로 미래 토큰들을 추론하고 대형 모델(Target)이 이를 한 번에 검증하여 추론 속도를 높이는 프레임워크.
- SpecBlock: 각 Drafter Forward가 여러 개의 종속적인 토큰을 블록 단위로 생성하고, 이를 반복적으로 확장하여 Draft Tree를 구성하는 제안 방법론.
- Rank Head: Drafter의 은닉 상태를 분석하여 토큰별 순위(Rank)를 예측하고, 이를 바탕으로 Draft Tree의 Branching Factor를 동적으로 결정하는 모듈.
- Valid-prefix Curriculum Learning: 학습 시 Drafter가 추론 단계에서 직면할 실제 컨텍스트를 반영하기 위해, 경로상에서 첫 번째 오답 발생 이후의 손실 함수(Loss)를 마스킹하는 학습 기법.
- Cost-aware Serving-time Adaptation: Drafter의 성능이 저하되었을 때, Verifier의 피드백을 활용하여 업데이트의 기대 처리량(Throughput) 이득이 비용보다 클 경우에만 선별적으로 Drafter를 업데이트하는 메커니즘.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 Speculative Decoding의 Drafter들이 가진 상반된 한계점을 극복하기 위해 제안되었다. Autoregressive 방식의 Drafter는 토큰 간의 종속성을 잘 유지하여 높은 Acceptance Rate를 보이지만, 매 깊이마다 Drafter를 호출해야 하므로 Latency 오버헤드가 크다. 반면, Parallel 방식은 Drafter 호출 횟수를 획기적으로 줄이지만 독립적인 예측으로 인해 토큰 간 연관성이 낮아 Verifier가 검증 단계에서 많은 비용을 낭비하게 된다 [Figure 1]. 저자들은 이러한 Trade-off를 해결하고, 높은 처리량과 효율적인 Drafting 비용을 동시에 달성하는 새로운 접근 방식이 필요하다고 보았다.
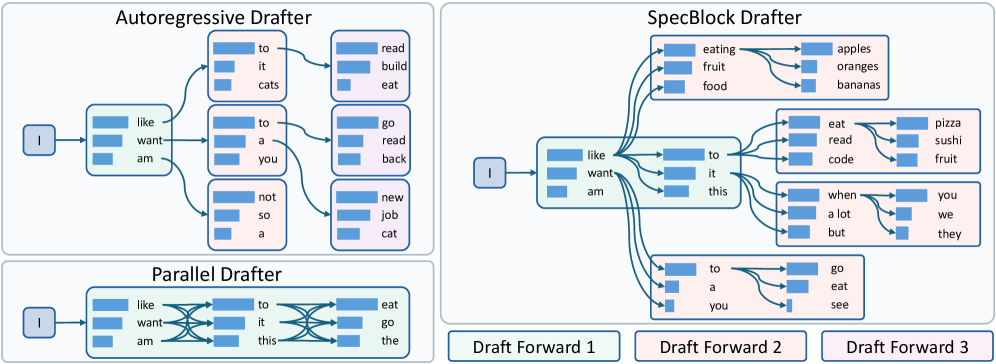
Figure 1 — 세 가지 드래프팅 방식 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 SpecBlock을 제안하며, 각 Drafting 단계를 K개의 종속적 토큰을 생성하는 블록으로 정의하고 이를 반복 확장하는 Block-Iterative 방식을 채택한다. 블록 내부의 종속성을 유지하기 위해 Layer-wise Shift 기법을 사용하여 이전 토큰의 은닉 상태를 다음 토큰으로 전파하며, Rank Head를 통해 토큰의 불확실성에 따라 Branching Factor를 동적으로 조절한다 [Figure 2]. 또한, 학습 과정에서 Valid-prefix Mask를 적용하여 잘못된 예측 경로에서의 불필요한 학습을 방지하였다. 실험 결과, SpecBlock은 EAGLE-3 대비 mean speedup을 8-13% 향상시켰으며, Drafting 비용은 EAGLE-3의 44-52% 수준으로 크게 절감하였다 [Table 1]. 특히, Cost-aware Serving-time Adaptation을 적용할 경우 이 격차는 11-19%까지 확대되는 우수한 성능을 보였다.
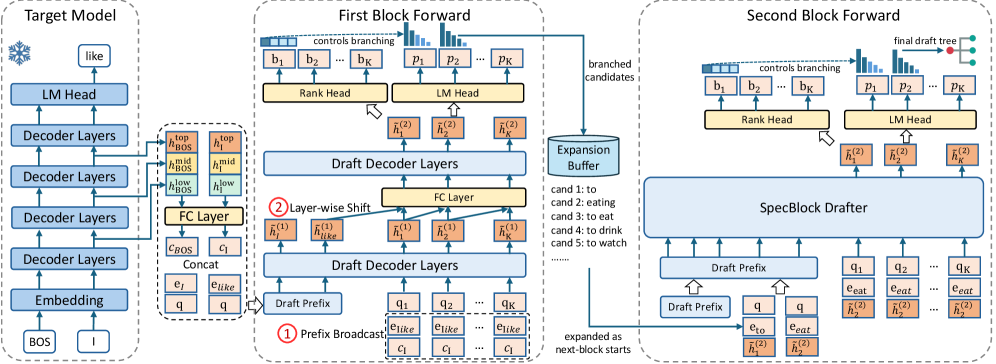
Figure 2 — SpecBlock 아키텍처 및 블록 반복 생성
4. Conclusion & Impact (결론 및 시사점)
본 연구는 블록 단위의 반복적 추론과 동적인 트리 생성을 통해 LLM 추론 효율성을 극대화하는 SpecBlock을 제안하였다. 이 연구는 기존의 고정된 Draft Tree 구조에서 벗어나, 학습과 추론 전 과정에 걸쳐 종속성을 유지하고 Verifier 피드백을 전략적으로 활용하는 새로운 방향성을 제시한다. 이러한 접근 방식은 컴퓨팅 자원이 제한된 환경에서 대규모 모델의 서빙 성능을 개선하는 데 중요한 기술적 토대를 제공하며, 향후 에너지 효율적인 LLM 서빙 연구에 큰 영향을 미칠 것으로 기대된다.
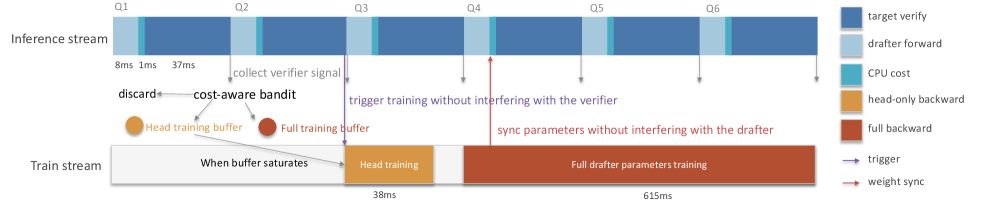
Figure 4 — 비용 인지 적응형 스케줄링
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] JetSpec: Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree Drafting
- [논문리뷰] VIA-SD: Verification via Intra-Model Routing for Speculative Decoding
- [논문리뷰] Speculative Pipeline Decoding: Higher-Accruacy and Zero-Bubble Speculation via Pipeline Parallelism
- [논문리뷰] Domino: Decoupling Causal Modeling from Autoregressive Drafting in Speculative Decoding
- [논문리뷰] LK Losses: Direct Acceptance Rate Optimization for Speculative Decoding
Review 의 다른글
- 이전글 [논문리뷰] Sparse Autoencoders as Plug-and-Play Firewalls for Adversarial Attack Detection in VLMs
- 현재글 : [논문리뷰] SpecBlock: Block-Iterative Speculative Decoding with Dynamic Tree Drafting
- 다음글 [논문리뷰] Steering Visual Generation in Unified Multimodal Models with Understanding Supervision
댓글