[논문리뷰] Sparse Autoencoders as Plug-and-Play Firewalls for Adversarial Attack Detection in VLMs
링크: 논문 PDF로 바로 열기
메타데이터
저자: Hao Wang, Yiqun Sun, Pengfei Wei, Lawrence B. Hsieh, Daisuke Kawahara
1. Key Terms & Definitions (핵심 용어 및 정의)
- SAEgis: 본 논문에서 제안하는 VLM의 Adversarial Attack 감지를 위한 Sparse Autoencoder 기반의 경량화된 Plug-and-Play 프레임워크입니다.
- Sparse Autoencoder (SAE): 입력 데이터의 재구성(Reconstruction) 학습을 통해 데이터의 희소한 잠재 특성(Sparse Latent Features)을 추출하는 기법으로, 본 논문에서는 Adversarial 신호를 캡처하는 데 활용됩니다.
- Attack-Relevant Features: Adversarial 입력과 Clean 입력 간의 통계적 차이가 큰 잠재 특성들을 선별하여 구성한, 공격 탐지를 위한 핵심 지표입니다.
- Multi-Layer SAE Ensembling: VLM의 다양한 계층(Vision Encoder, Projection Layer 등)에 삽입된 SAE들의 신호를 결합하여 탐지의 안정성과 정밀도를 향상시키는 전략입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 최신 Vision-Language Models(VLMs)가 Adversarial 공격에 극도로 취약하며, 기존의 탐지 방식들은 실질적인 배포 환경에서의 강력한 공격이나 데이터 분포 변화에 대응하지 못한다는 문제를 해결하고자 합니다. 기존 연구들은 고정된 데이터셋이나 특정 공격 시나리오에 편향되어 평가되었으며, 실무 환경에서 중요한 Out-of-Domain 환경에 대한 일반화 능력이 부족합니다. 저자들은 추가적인 Adversarial Training 없이 기존 모델을 그대로 활용하면서도 최소한의 연산 비용으로 공격을 효과적으로 탐지할 수 있는 시스템이 필요함을 강조합니다 [Figure 1].
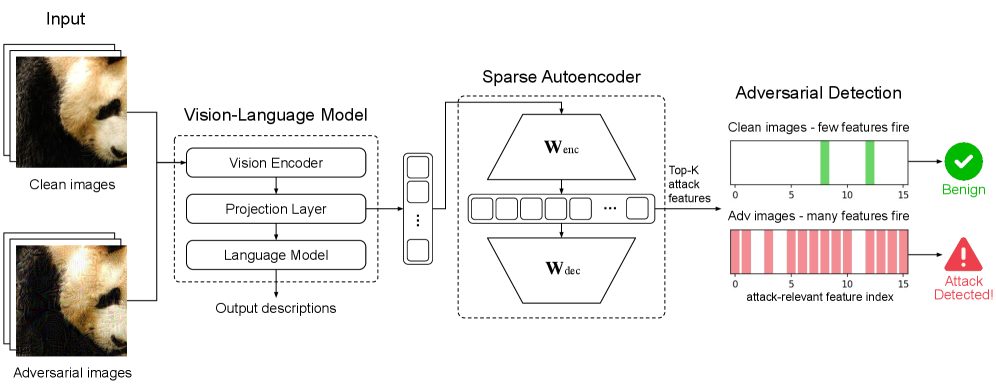
Figure 1 — SAEgis의 전체 작동 프레임워크
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 사전 학습된 VLM의 Vision Encoder나 Projection Layer에 SAE 모듈을 삽입하고, 표준 재구성 목적 함수(Standard Reconstruction Objective)로 학습시켜 모델이 공격을 탐지하게 하는 SAEgis를 제안합니다. 제안된 방법론은 Adversarial 샘플들로부터 통계적으로 높은 유의성을 보이는 Top-K 공격 관련 특성을 식별하고, 추론 시 이 특성들의 활성화 개수를 기반으로 공격 여부를 분류합니다. 실험 결과, SAEgis는 In-Domain 설정에서 우수한 성능을 보였을 뿐만 아니라, 기존 Baselines이 실패하는 Cross-Domain 및 Cross-Attack 시나리오에서도 높은 정밀도(Precision)와 재현율(Recall)을 유지합니다 [Table 1, Table 2]. 특히, 다중 계층(Multi-Layer)의 정보를 앙상블했을 때, 단일 계층 대비 F1-score가 크게 향상되는 안정적인 성능을 입증했습니다 [Table 5]. 아울러, 단 10개의 Adversarial 샘플만으로도 높은 수준의 탐지 성능을 확보할 수 있음을 보여주어 실용성을 극대화했습니다 [Figure 6].
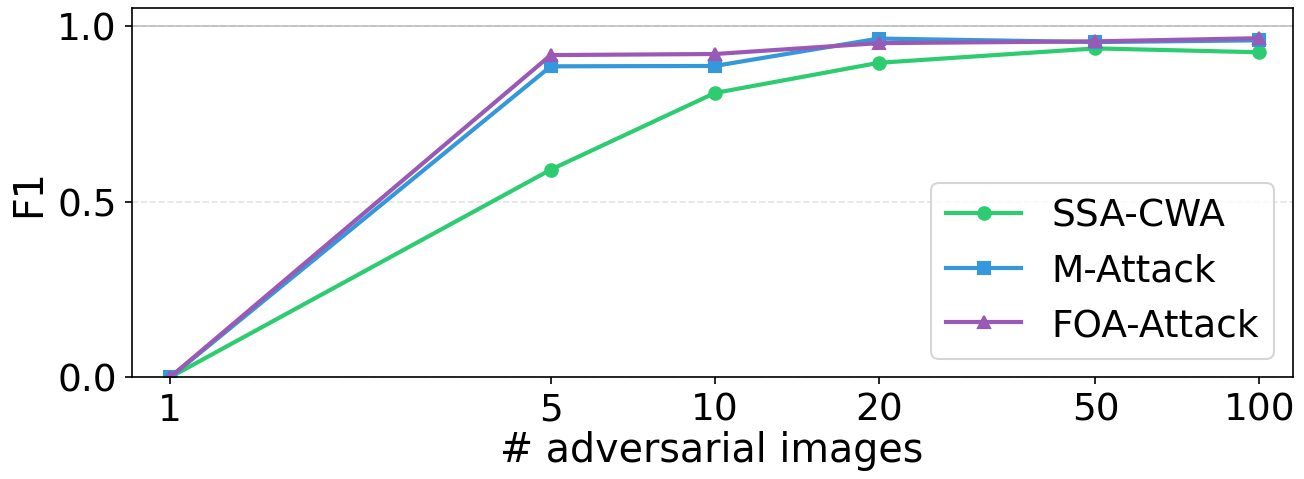
Figure 6 — 공격 샘플 수에 따른 탐지 성능
4. Conclusion & Impact (결론 및 시사점)
본 논문은 희소 오토인코더(SAE)가 VLM을 위한 Plug-and-Play 방화벽 역할을 수행하여 Adversarial 공격 탐지에 매우 효과적임을 입증합니다. 제안된 SAEgis 프레임워크는 별도의 재학습 없이 기존 VLM 시스템의 안전성을 강화할 수 있는 실용적인 아키텍처를 제공합니다. 이 연구는 최신 멀티모달 시스템이 직면한 보안 위협을 해결하는 기술적 토대를 마련하였으며, 향후 다양한 VLM 기반 에이전트 및 현실 배포 모델의 보안 프로토콜 구축에 큰 기여를 할 것으로 기대됩니다.
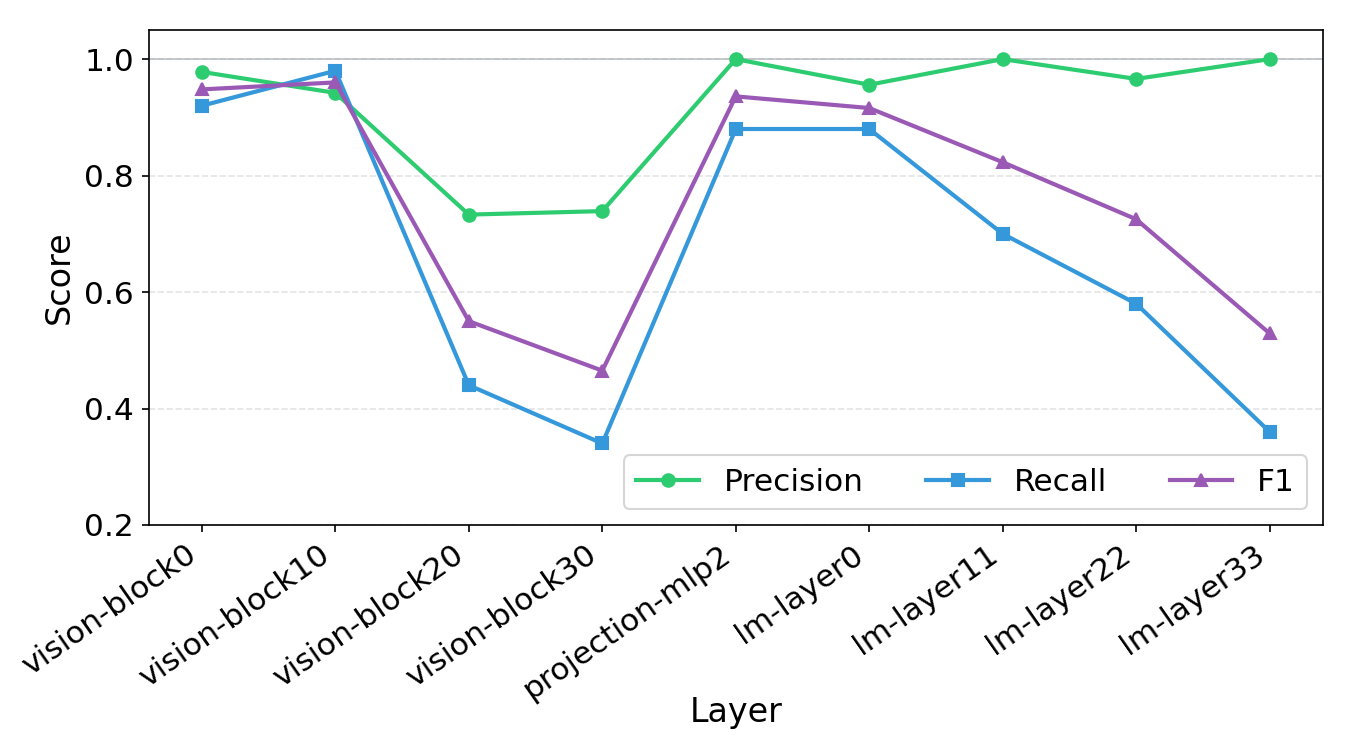
Figure 2 — SAE 삽입 위치별 성능 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] RoboStressBench: Benchmarking VLM Robustness to Physical Visual Stress in Embodied Scenes
- [논문리뷰] RadAgent: A tool-using AI agent for stepwise interpretation of chest computed tomography
- [논문리뷰] BrainExplore: Large-Scale Discovery of Interpretable Visual Representations in the Human Brain
- [논문리뷰] VoiceAssistant-Eval: Benchmarking AI Assistants across Listening, Speaking, and Viewing
- [논문리뷰] Rank-Then-Act: Reward-Free Control from Frame-Order Progress
Review 의 다른글
- 이전글 [논문리뷰] SkCC: Portable and Secure Skill Compilation for Cross-Framework LLM Agents
- 현재글 : [논문리뷰] Sparse Autoencoders as Plug-and-Play Firewalls for Adversarial Attack Detection in VLMs
- 다음글 [논문리뷰] SpecBlock: Block-Iterative Speculative Decoding with Dynamic Tree Drafting
댓글