[논문리뷰] Video Generation with Predictive Latents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yian Zhao, Feng Wang, Qiushan Guo, Chang Liu, Xiangyang Ji, Jian Zhang, Jie Chen, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Video VAE: 비디오 데이터를 고차원 픽셀 공간에서 압축된 저차원 시공간 Latent 공간으로 매핑하여 비디오 생성의 효율성과 안정성을 높이는 모델.
- Predictive Reconstruction (PR): 비디오 프레임의 일부를 의도적으로 제거(drop)하고 남은 관측치만을 사용하여 전체 시퀀스를 재구성하도록 학습함으로써, 모델이 Latent 공간 내에 시간적 역학(Temporal Dynamics)을 학습하도록 유도하는 핵심 기법.
- Diffusability: Latent 공간이 Diffusion 모델의 생성 과정에 얼마나 적합한지를 나타내는 지표로, 시공간적 일관성과 모션 정보를 얼마나 효과적으로 인코딩하는지가 관건.
- Motion-aware Objective: 정적인 배경 정보에 대한 과잉 최적화를 방지하고, 구조적 움직임(Structural Motion)과 시간적 변화에 집중하도록 강제하는 추가적인 학습 제약 조건.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 Video VAE가 단순히 비디오의 시각적 재구성 성능을 최적화하는 것만으로는 우수한 비디오 생성(Generative Performance)을 보장할 수 없다는 문제점을 해결하고자 한다. 기존 모델들은 주로 2D Image VAE를 비디오용으로 확장하는 방식을 취하는데, 이는 비디오 생성에 필수적인 고차원적 시간 역학이나 모션 정보를 Latent 공간 내에 효과적으로 반영하지 못한다. 결과적으로 이러한 Latent 공간은 Diffusion 모델의 학습 효율성을 저해하고 생성된 비디오의 일관성을 떨어뜨리는 한계가 있다. 저자들은 이 문제를 극복하기 위해 비디오의 미래 상태를 예측하는 세계 모델(World Modeling)의 원리를 비디오 VAE에 통합하는 새로운 접근 방식을 제안한다 [Figure 1].
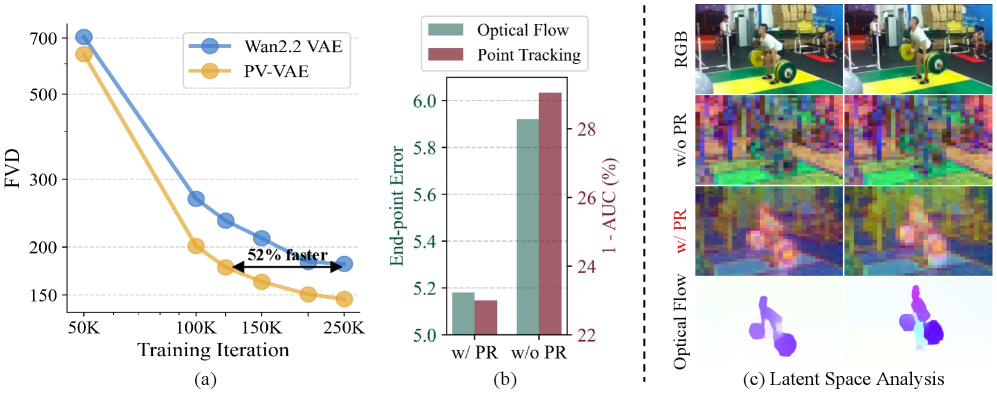
Figure 1 — PV-VAE의 성능 및 특성
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 미래 프레임을 랜덤하게 생략하고 과거 관측치만으로 전체 비디오를 재구성하게 하는 Predictive Reconstruction (PR) 프레임워크인 PV-VAE를 제안한다 [Figure 2]. 이 방법론은 Encoder가 시간적 맥락을 추론하여 Latent 공간에 인코딩하도록 강제하며, 정적인 영역에서의 'copy-shortcut'을 방지하기 위해 Motion-aware Objective를 함께 최적화한다. 또한, 고품질 재구성을 위해 추가적인 Decoder Fine-tuning 단계를 포함하는 전략을 사용한다. 실험 결과, PV-VAE는 UCF101 데이터셋에서 기존 Wan2.2 VAE 대비 52% 빠른 수렴 속도를 보였으며, FVD(Frechet Video Distance) 지표에서 34.42 개선된 성능을 달성했다 [Table 1]. 또한, 광학 흐름(Optical Flow)과 포인트 트래킹 등의 다운스트림 비디오 이해 태스크에서도 baseline 대비 일관된 성능 향상을 입증하였다 [Table 3]. [Figure 3]은 제안 방법론이 기존 모델 대비 뛰어난 시각적 충실도와 시간적 일관성을 확보함을 보여준다.
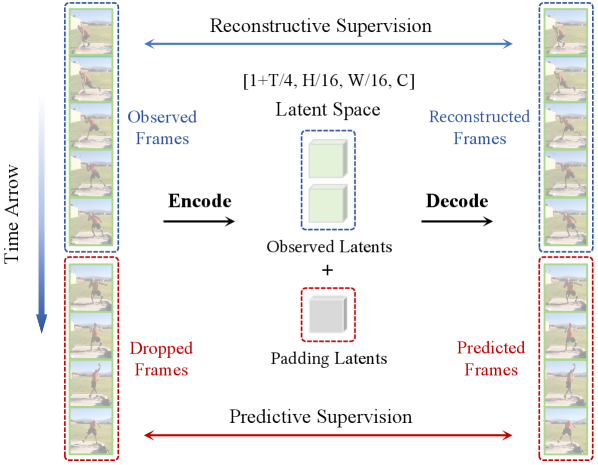
Figure 2 — PV-VAE 전체 파이프라인

Figure 3 — 생성 및 재구성 정성적 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 예측 학습을 비디오 재구성 프레임워크에 성공적으로 통합함으로써, 비디오 생성의 효율성과 품질을 동시에 극대화하는 PV-VAE를 제시하였다. 이는 단순한 시각적 복원을 넘어 비디오의 시간적 역학을 학습하는 Latent 공간의 중요성을 입증한 결과로 평가된다. 연구 결과는 향후 더 복잡한 비디오 시퀀스 생성 연구와 더불어, 효율적인 Transformer 기반 비디오 VAE 아키텍처 설계에 중요한 방향성을 제시한다. 이 연구가 학계와 산업계의 비디오 생성 시스템 구축 방식에 구조적 모션 인식을 강조하는 새로운 패러다임을 확립할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] CogOmniControl: Reasoning-Driven Controllable Video Generation via Creative Intent Cognition
- [논문리뷰] Motion Attribution for Video Generation
- [논문리뷰] MUG-V 10B: High-efficiency Training Pipeline for Large Video Generation Models
- [논문리뷰] VIST3A: Text-to-3D by Stitching a Multi-view Reconstruction Network to a Video Generator
- [논문리뷰] GigaWorld-1: A Roadmap to Build World Models for Robot Policy Evaluation
Review 의 다른글
- 이전글 [논문리뷰] The TTS-STT Flywheel: Synthetic Entity-Dense Audio Closes the Indic ASR Gap Where Commercial and Open-Source Systems Fail
- 현재글 : [논문리뷰] Video Generation with Predictive Latents
- 다음글 [논문리뷰] Workspace-Bench 1.0: Benchmarking AI Agents on Workspace Tasks with Large-Scale File Dependencies
댓글