[논문리뷰] The TTS-STT Flywheel: Synthetic Entity-Dense Audio Closes the Indic ASR Gap Where Commercial and Open-Source Systems Fail
링크: 논문 PDF로 바로 열기
메타데이터
저자: Venkata Pushpak Teja Menta, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Entity-Dense Audio (EDA): 전화번호, 핀코드, 통화 금액, 브랜드명, 영어-인도어 코드믹스 등 일반적인 문장 기반 코퍼스(read-prose)가 잘 다루지 못하는 고유 명사 중심의 오디오 콘텐츠를 지칭함.
- TTS-STT Flywheel: TTS(Text-to-Speech)를 활용하여 합성 데이터를 생성하고 이를 통해 STT(Speech-to-Text) 모델을 고도화하는 데이터 순환 구조.
- Entity-Hit-Rate (EHR): 엔티티 클래스별 정규화된(semantic normalization) 평가 지표로, 일반적인 WER보다 엔티티 인식 정확도를 더 정밀하게 측정함.
- Script Fidelity Rate (SFR): 특정 언어의 기대 유니코드 블록 내에 포함된 문자 비율을 측정하여 언어별 스크립트 붕괴(Script Collapse) 현상을 정량화함.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 상용 및 오픈 소스 STT 시스템이 인도 언어의 특정 엔티티 인식에서 극도로 낮은 성능을 보이는 문제를 해결하고자 한다. 기존 시스템들은 Wikipedia나 뉴스 등 read-prose 중심의 데이터로 학습되어, 실제 현업에서 빈번한 엔티티 데이터에 취약하다. [Figure 1]에서 볼 수 있듯이 기존 SOTA 시스템은 엔티티 인식률(EHR)이 0.027~0.16 수준에 불과하다. 저자들은 이러한 성능 격차를 단순히 읽기 데이터(read-prose)를 추가하는 것만으로는 극복할 수 없으며, 엔티티 특화 합성 데이터 생성을 통한 방법론이 필요함을 역설한다.
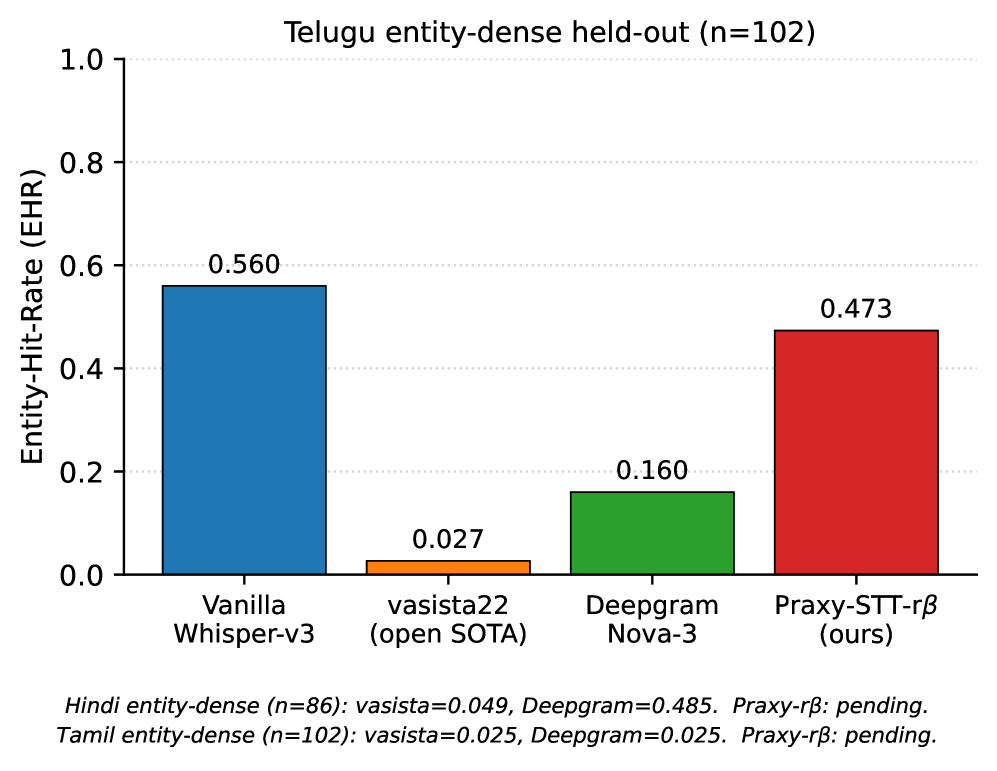
Figure 1 — 텔루구어 엔티티 인식 EHR 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 EDSA(Entity-Dense Synthetic Audio) 코퍼스를 생성하고 LoRA를 통해 Whisper-large-v2/v3 모델을 파인튜닝하는 TTS-STT Flywheel 방식을 제안한다. 약 22,000개의 엔티티 중심 발화를 생성하여 학습에 활용하였으며, 이는 기존 SOTA 대비 훨씬 저렴한 비용으로 구현되었다. 실험 결과, 제안 모델(Praxy-STT-rb)은 텔루구어 기준 EHR 0.473을 달성하여 기존 SOTA 대비 17배, 상용 모델 대비 3배 이상의 성능 향상을 보였다 [Figure 1]. 또한, 제안 방법론은 텔루구어 이외에도 타밀어 및 힌디어 등 타 언어에서도 유의미한 EHR 상승을 견인하였다. 주목할 점은 EDSA-isolation ablation 실험을 통해 학습 성능의 100%가 생성된 합성 데이터로부터 기인함을 증명하였으며, 읽기 데이터(FLEURS)로만 학습한 제어 모델은 EHR 0.020 수준에 머물렀다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 엔티티 중심의 합성 데이터를 활용한 Flywheel 아키텍처가 인도 언어 ASR의 성능 사각지대를 효율적으로 해소할 수 있음을 입증하였다. 특히, 상용 모델 대비 부족한 엔티티 인식 분야에서 오픈 소스 기반의 강력한 대안을 제시했다는 점에서 의의가 크다. 저자들은 또한 스크립트 붕괴(Script Collapse)를 언어별로 선별적으로 교정해야 한다는 중요한 실무 가이드를 제공하였다. 이 방법론은 비용 효율적인 모델 적응을 필요로 하는 다양한 저자원 언어 및 전문 도메인 ASR 분야에 큰 시사점을 준다.
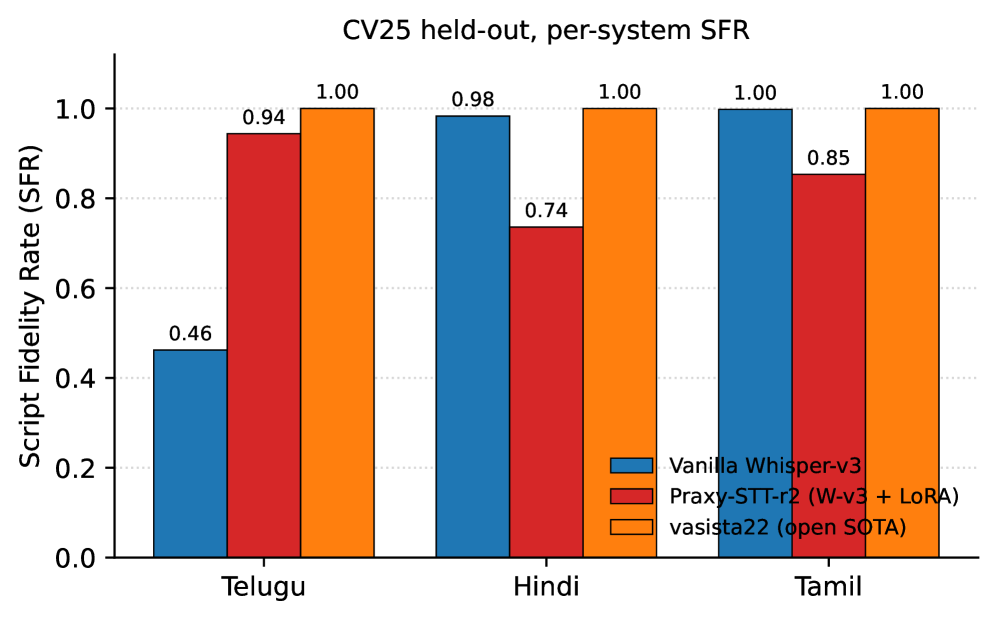
Figure 2 — 언어별 스크립트 붕괴 및 LoRA 교정
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Program-as-Weights: A Programming Paradigm for Fuzzy Functions
- [논문리뷰] From SRA to Self-Flow: Data Augmentation or Self-Supervision?
- [논문리뷰] Discrete Diffusion Language Models for Interactive Radiology Report Drafting
- [논문리뷰] AGVBench: A Reliability-Oriented Benchmark of Data Augmentation for Vein Recognition
- [논문리뷰] DreamForge-World 0.1 Preview: A Low-Compute Real-Time Controllable World Model
Review 의 다른글
- 이전글 [논문리뷰] TCDA: Thread-Constrained Discourse-Aware Modeling for Conversational Sentiment Quadruple Analysis
- 현재글 : [논문리뷰] The TTS-STT Flywheel: Synthetic Entity-Dense Audio Closes the Indic ASR Gap Where Commercial and Open-Source Systems Fail
- 다음글 [논문리뷰] Video Generation with Predictive Latents
댓글