[논문리뷰] Shallow Prefill, Deep Decoding: Efficient Long-Context Inference via Layer-Asymmetric KV Visibility
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jay-Yoon Lee, Kyongmin Kong, Hyunjune Ji, Hyeseo Jeon, Jungsuk Oh
1. Key Terms & Definitions (핵심 용어 및 정의)
- SPEED (Shallow Prefill, dEEp Decode): Prefill 단계의 토큰 KV state는 하위 레이어에서만 생성하고, Decode 단계의 토큰은 전체 레이어를 통과시켜 KV state를 생성하는 효율적인 추론 프레임워크입니다.
- KV-visibility: 특정 레이어에서 Decode 토큰이 참조할 수 있는 KV state의 집합을 의미하며, SPEED는 이를 Phase-asymmetric하게 제어합니다.
- BoS anchor: SPEED의 하위 레이어-only Prefill 체제에서 생성 안정성을 확보하기 위해, 시작 토큰(BoS)만을 전체 레이어에 걸쳐 유지하는 안정화 기법입니다.
- TTFT (Time-To-First-Token): 추론 요청 후 첫 번째 토큰이 생성되기까지 걸리는 시간으로, 주로 Prefill 단계의 성능에 의해 결정됩니다.
- TPOT (Time-Per-Output-Token): Decode 단계에서 각 토큰을 생성하는 데 걸리는 평균 시간입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 decoder-only 모델에서 long-context 추론 시 발생하는 Prefill 단계의 높은 계산 비용과 Decode 단계의 KV-cache 메모리 대역폭 한계를 해결하고자 합니다. 기존 연구들은 Prefill 단계에서 중복된 KV state를 압축하거나 상위 레이어의 KV state를 근사하는 방식을 사용했으나, 여전히 Decode 단계에서 반복적인 메모리 접근이 필요하거나 불필요하게 많은 KV memory를 점유한다는 한계가 있습니다 [Figure 1]. 저자들은 full-depth model의 Decode 단계에서 상위 레이어의 Prefill 토큰에 대한 attention이 매우 낮다는 사실을 포착하여, 아예 상위 레이어에서 Prefill 토큰의 KV state materialization을 제거하는 효율적인 접근 방식이 필요하다고 판단했습니다.
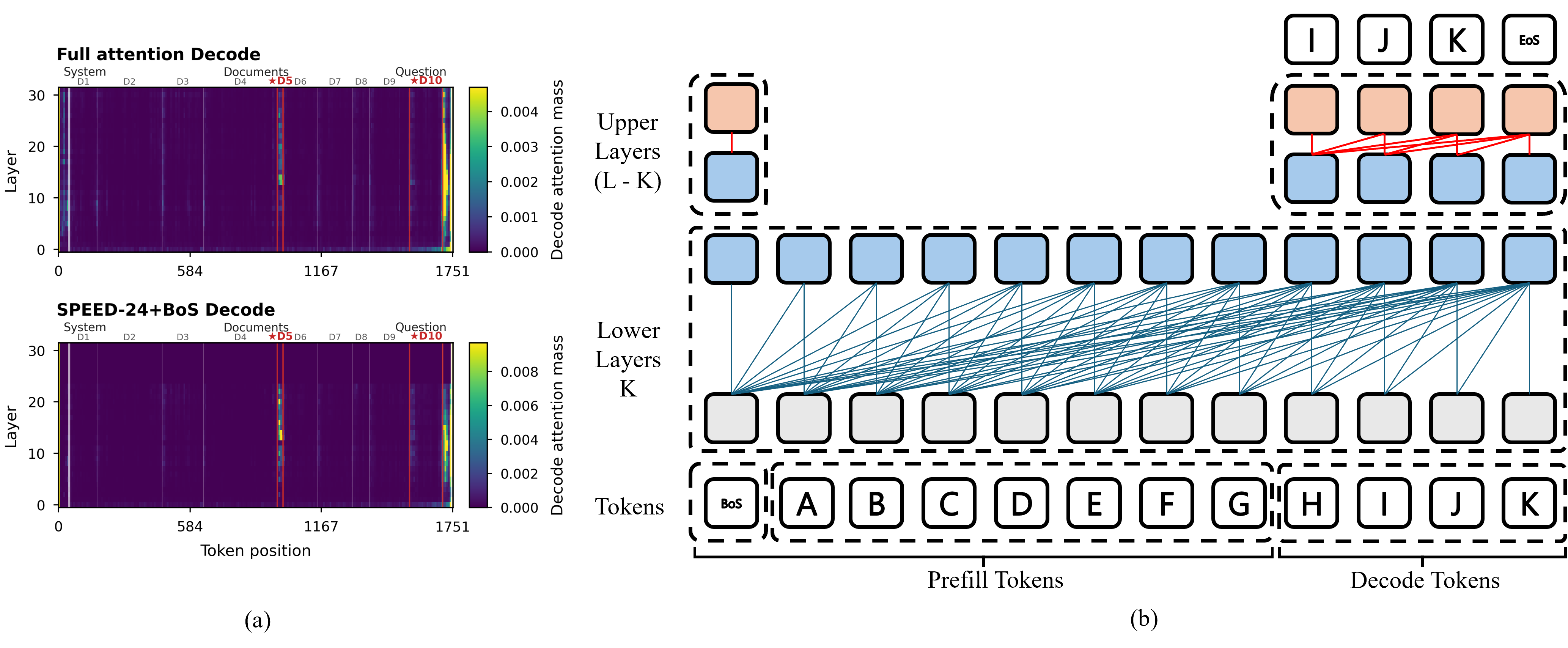
Figure 1 — SPEED의 작동 원리
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 prefill 토큰은 하위 K개 레이어에서만 처리하고, decode 토큰은 전체 레이어를 통과하도록 설계된 SPEED 정책을 제안합니다 [Figure 1]. 이 방식은 긴 문맥에서 dominant한 Prefill 측 KV 저장 공간을 $O(LN)$에서 $O(KN)$으로 효율화하며, Decode 시 상위 레이어에서 Prefill-cache를 읽는 오버헤드를 제거합니다. 생성 안정성을 보장하기 위해 BoS 토큰을 anchor로 활용하는 SPEED-24+BoS를 핵심 operating point로 정의했습니다. Llama-3.1-8B 모델 기반 실험 결과, SPEED-24+BoS는 Full-depth baseline 대비 51.2라는 경쟁력 있는 품질을 유지하면서도 128K context 환경에서 TTFT 33% 향상, TPOT 22% 향상, active KV memory 25.0% 감소를 달성했습니다 [Table 2]. Layer-wise diagnostic 결과, K=24는 모델의 주요 prompt-selection 및 representation-stabilization 레이어를 충분히 포함하고 있음이 확인되었습니다 [Figure 3].
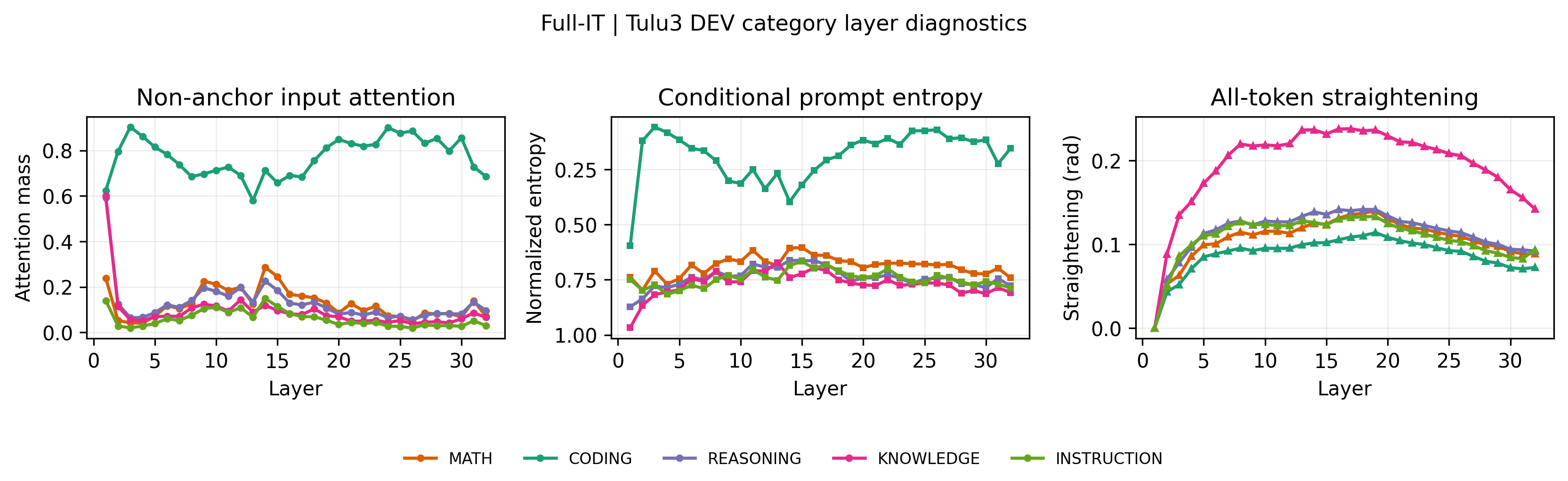
Figure 3 — 레이어별 진단 결과
4. Conclusion & Impact (결론 및 시사점)
본 연구는 long-context 효율성이 단순히 cache 압축이나 serving 최적화만으로 달성되는 것이 아니라, Prefill-side의 KV materialization 레이어를 의도적으로 비대칭화함으로써 근본적으로 개선될 수 있음을 증명했습니다. SPEED는 기존의 모델 아키텍처나 가중치를 수정하지 않고도 즉각적인 추론 성능 최적화를 가능하게 하며, 특히 보편적인 BoS 토큰을 활용한 안정화 기법은 실무적인 배포 가능성을 높입니다. 이러한 접근 방식은 향후 자원 제약이 있는 대규모 long-context 언어 모델 serving 환경에서 비용 효율적인 솔루션을 제공하는 중요한 지표가 될 것으로 기대됩니다.
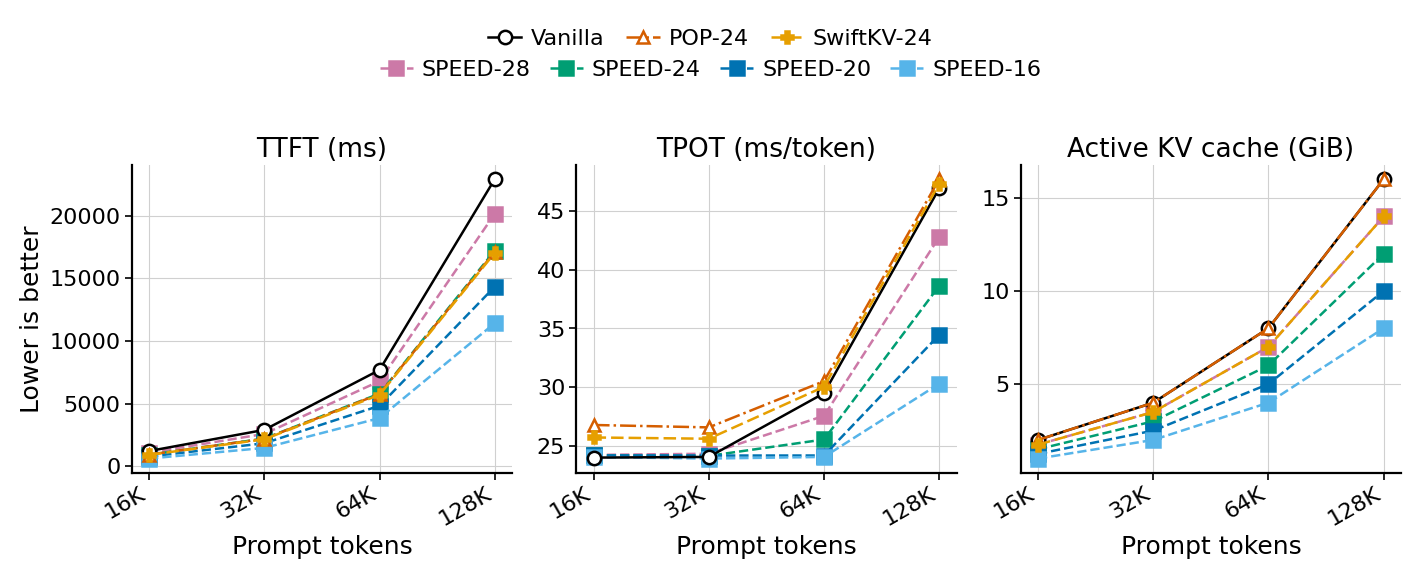
Figure 2 — 긴 문맥 효율성 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Token Sparse Attention: Efficient Long-Context Inference with Interleaved Token Selection
- [논문리뷰] GORGO: Online Tuning for Cross-Region Network-Aware LLM Serving
- [논문리뷰] PolyFlow: Continuous Topology Embedding Flow Matching for Artist-style Mesh Generation
- [논문리뷰] Bag of Dims: Training-Free Mechanistic Interpretability via Dimension-Level Sign Patterns
- [논문리뷰] Variable-Width Transformers
Review 의 다른글
- 이전글 [논문리뷰] Scaling Continual Learning to 300+ Tasks with Bi-Level Routing Mixture-of-Experts
- 현재글 : [논문리뷰] Shallow Prefill, Deep Decoding: Efficient Long-Context Inference via Layer-Asymmetric KV Visibility
- 다음글 [논문리뷰] SkCC: Portable and Secure Skill Compilation for Cross-Framework LLM Agents
댓글