[논문리뷰] Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling
링크: 논문 PDF로 바로 열기
저자: Yafu Li, Runzhe Zhan, Haoran Zhang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- SU-01: 본 논문에서 제안하는 Olympiad급 추론 모델로, 30B-A3B backbone을 기반으로 훈련된 rigorous reasoning solver입니다.
- Reverse-Perplexity Curriculum (RPC): SFT 단계에서 데이터를 정렬하는 방식으로, 모델이 학습 초기 단계에서 가장 불일치하는(mismatched) 데이터부터 학습하게 하여 추론 능력을 보존하고 향상시키는 기법입니다.
- Refined RL: 기존의 정답 확인 기반 RL을 넘어, 증명의 엄격성, 논리적 타당성, 자기 수정(Self-refinement) 과정을 포함한 보상 모델을 통해 정책을 최적화하는 단계입니다.
- Test-time Scaling (TTS): 모델이 추론 시점에 여러 단계의 solve-verify-refine 과정을 반복하며 추가적인 컴퓨팅 자원을 할당하여 어려운 문제를 해결하는 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 고도의 수학 및 과학 Olympiad 문제에서 금메달 수준의 추론 능력을 갖춘 모델을 만들기 위한 간단하고 통합된 레시피를 제안합니다. 기존의 일반적인 추론 모델들은 수학적 문제 해결에서 단기적인 성과를 내지만, 복잡한 증명 문제에 필요한 엄격한 추론과 검증 능력이 부족하다는 한계가 있습니다. 특히, 30B 이하의 소형 backbone에서 이러한 최고 수준의 추론 능력을 끌어내는 효율적인 학습 파이프라인의 부재가 중요한 문제로 대두되었습니다 [Figure 2].
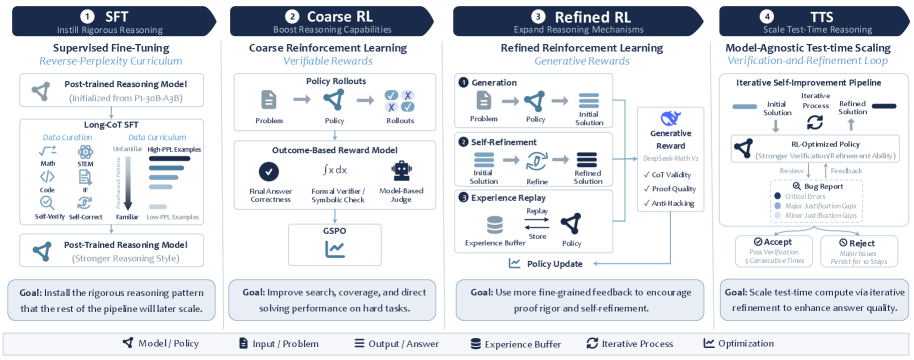
Figure 2 — SU-01 학습 및 추론 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 3단계 모듈형 파이프라인을 제안합니다: (1) 엄격한 proof-search 패턴을 주입하기 위한 Reverse-Perplexity Curriculum 기반의 SFT, (2) 검증 가능한 보상과 증명 수준의 보상을 결합한 2단계 RL, (3) 추론 시의 추가 컴퓨팅을 활용한 TTS입니다. 이러한 과정을 통해 30B-A3B backbone 모델인 SU-01을 성공적으로 학습시켰습니다.
주요 실험 결과로, SU-01은 IMO-ProofBench에서 TTS 적용 시 70.2%의 정확도를 기록하며 유사한 크기의 모델들을 압도했습니다 [Table 3]. 또한 USAMO 2026 문제에서 TTS를 통해 35점을 획득하여 최고 수준의 인간 경쟁자와 동등한 성능을 보였으며, 이는 해당 규모의 모델에서 유례없는 성과입니다 [Table 4].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 적절한 훈련 및 추론 레시피를 통해 소형 모델이 단순한 문제 풀이를 넘어 전문가 수준의 엄격한 증명 추론이 가능함을 입증했습니다. 이 연구는 대형 모델에 의존하지 않고도 compact한 backbone 모델이 과학적 영역 전반으로 일반화 가능한 추론 능력을 가질 수 있음을 보여주며, 학계와 산업계에 효율적인 고성능 추론 모델 설계의 방향성을 제시합니다.

Figure 3 — SFT 데이터 구성
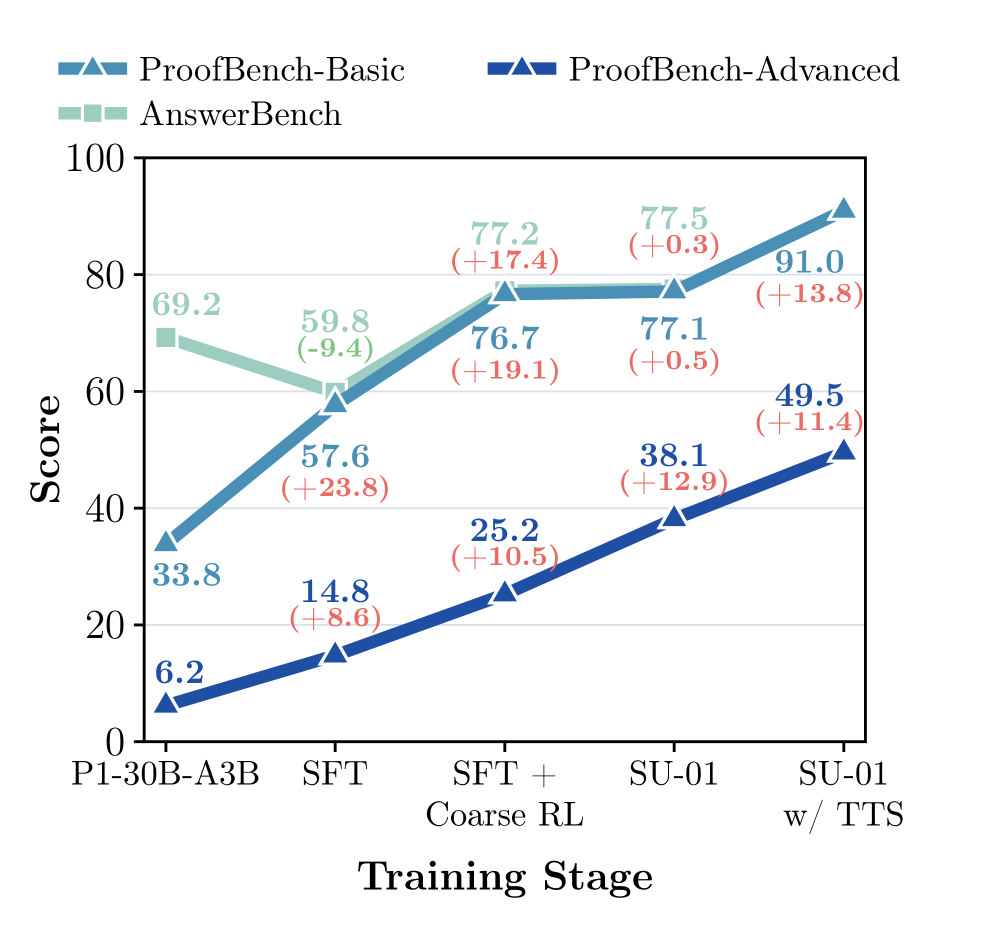
Figure 4 — 학습 단계별 추론 성능 향상
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Dockerless: Environment-Free Program Verifier for Coding Agents
- [논문리뷰] Native Active Perception as Reasoning for Omni-Modal Understanding
- [논문리뷰] VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models
- [논문리뷰] DenoiseRL: Bootstrapping Reasoning Models to Recover from Noisy Prefixes
- [논문리뷰] Macaron-A2UI: A Model for Generative UI in Personal Agents
Review 의 다른글
- 이전글 [논문리뷰] ATLAS: Agentic or Latent Visual Reasoning? One Word is Enough for Both
- 현재글 : [논문리뷰] Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling
- 다음글 [논문리뷰] Adaptive Teacher Exposure for Self-Distillation in LLM Reasoning
댓글