[논문리뷰] ATLAS: Agentic or Latent Visual Reasoning? One Word is Enough for Both
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ziyu Guo, Rain Liu, Xinyan Chen, Pheng-Ann Heng, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Functional Token: 기존 VLM의 tokenizer vocabulary에 추가된 5개의 특수 토큰(
<|Manip|>,<|Shape|>,<|Line|>,<|Arrow|>,<|Text|>)으로, 외부 도구 호출 없이도 모델이 내부적으로 시각적 조작(Visual Operation)을 수행하도록 지시하는 단위입니다. - Agentic/Latent Visual Reasoning: Agentic 방식은 외부 도구/코드 실행을 통해, Latent 방식은 hidden embeddings를 통해 중간 단계의 추론을 수행하는 패러다임입니다.
- LA-GRPO (Latent-Anchored GRPO): 표준 GRPO의 시퀀스 단위 보상 최적화 과정에서 발생하는 희소한 Functional Token에 대한 'gradient dilution' 문제를 해결하기 위해, 해당 토큰 위치에 token-level의 보조 목적 함수(auxiliary objective)를 추가한 학습 방법론입니다.
- ATLAS-178K: 모델이 Functional Token을 사용하는 추론 궤적(Reasoning Trajectory)을 학습할 수 있도록 구축된 178K 규모의 SFT(Supervised Fine-Tuning) 데이터셋입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 Visual Reasoning 기법들이 직면한 연산 효율성 및 아키텍처 호환성 문제를 해결하고자 합니다. 기존 Agentic 방식은 외부 실행에 따른 context-switching latency를 초래하고, Latent 방식은 task generalization 부족과 병렬 학습의 어려움이라는 한계를 갖습니다 [Figure 1]. 또한, 직접적인 중간 이미지 생성(Unified models)은 과도한 계산 비용과 복잡한 아키텍처 변경을 요구합니다. 따라서 저자들은 외부 환경이나 별도의 latent 의존성 없이, 표준적인 autoregressive generation 루프 내에서 효율적으로 추론을 수행할 수 있는 프레임워크가 필요하다고 정의합니다.

Figure 1 — 시각적 추론 패러다임 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 시각적 조작을 표준 토큰화 과정에 포함하는 ATLAS 프레임워크를 제안합니다 [Figure 2]. ATLAS는 Qwen2.5-VL-7B를 기반으로 하며, 사전에 정의된 Functional Token들을 통해 시각적 작업(예: 영역 강조, 선 그리기)을 자연어 처리와 동일한 선상에서 수행합니다. 학습은 2단계로 진행되는데, 1단계에서는 ATLAS-178K 데이터셋을 활용한 SFT를 통해 Functional Token 사용법을 학습하고, 2단계에서는 LA-GRPO를 통해 강화학습을 수행합니다. 특히 LA-GRPO는 Functional Token이 전체 시퀀스에서 차지하는 비중이 매우 낮아 발생하는 gradient dilution을 보조 목적 함수로 상쇄함으로써 학습을 안정화합니다 [Figure 3]. 정량적 실험 결과, ATLAS는 BLINK 벤치마크에서 기존 모델 대비 월등한 성능 향상을 보였으며, 특히 ATLAS-LA-GRPO 모델은 평균 정확도 51.3%를 달성하여 강력한 추론 능력을 입증했습니다 [Table 3]. 또한 추론 효율성 측면에서 기존 V-Thinker 모델 대비 Latency를 18.83s에서 3.80s로 약 4.96배 개선하였습니다 [Table 4].
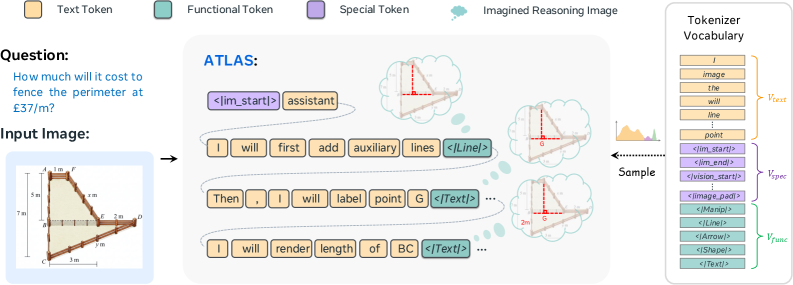
Figure 2 — ATLAS 전체 파이프라인
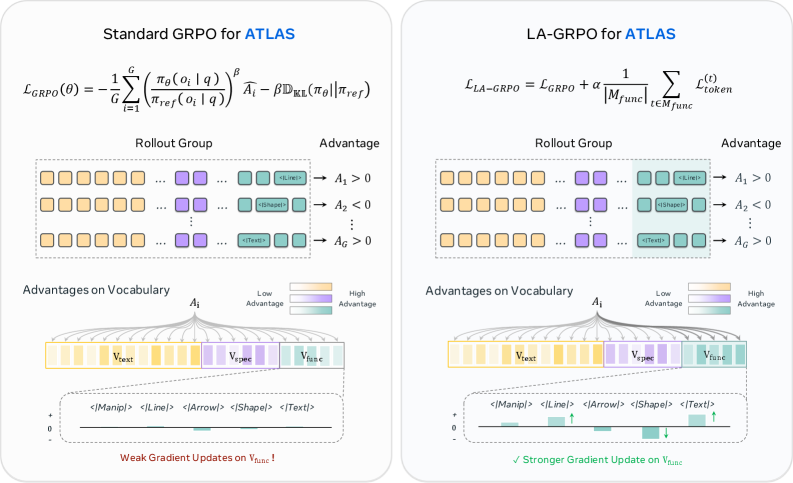
Figure 3 — LA-GRPO 아키텍처 및 보조 목표
4. Conclusion & Impact (결론 및 시사점)
본 연구는 ATLAS를 통해 visual reasoning을 별도의 도구 호출이나 이미지 생성 없이, 표준적인 autoregressive token generation 내부로 내재화하는 혁신적인 패러다임을 제시했습니다. LA-GRPO 기법은 희소한 제어 토큰에 대한 최적화를 성공적으로 수행하여 대규모 언어 모델의 추론 능력을 극대화했습니다. 이 연구는 향후 효율적이고 확장 가능한 multimodal reasoning 모델 설계에 있어 중요한 방법론적 토대를 제공하며, 산업계와 학계 모두에서 VLM의 효율적 배포를 위한 새로운 기준을 마련할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] AdaTooler-V: Adaptive Tool-Use for Images and Videos
- [논문리뷰] Latent Sketchpad: Sketching Visual Thoughts to Elicit Multimodal Reasoning in MLLMs
- [논문리뷰] Flex-Forcing: Towards a Unified Autoregressive and Bidirectional Video Diffusion Model
- [논문리뷰] LiveEdit: Towards Real-Time Diffusion-Based Streaming Video Editing
- [논문리뷰] SingGuard: A Policy-Adaptive Multimodal LLM Guardrail with Dynamic Reasoning
Review 의 다른글
- 이전글 [논문리뷰] WriteSAE: Sparse Autoencoders for Recurrent State
- 현재글 : [논문리뷰] ATLAS: Agentic or Latent Visual Reasoning? One Word is Enough for Both
- 다음글 [논문리뷰] Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling
댓글