[논문리뷰] WriteSAE: Sparse Autoencoders for Recurrent State
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jack Young
1. Key Terms & Definitions (핵심 용어 및 정의)
- WriteSAE: Gated DeltaNet, Mamba-2와 같은 모델의 matrix-recurrent cache write(rank-1 업데이트)를 직접적으로 분해하고 편집할 수 있도록 설계된 최초의 Sparse Autoencoder(SAE).
- Cache-slot substitution: 원본 모델의 rank-1 cache write를 학습된 rank-1 atom으로 교체하여 모델의 예측 성능을 테스트하는 Mechanistic Interpretability 기법.
- Register: 캐시 내에서 쓰기 방향(write direction)이 명확하게 복구되는 WriteSAE 디코더 atom 클래스.
- Bundle: 쓰기 작업이 캐시 전체에 분산되어 나타나는 WriteSAE 디코더 atom 클래스.
- Closed-form Logit-shift: 게이트(gate), 읽기(read), 언임베딩(unembed)의 3가지 요소를 결합하여 특정 feature 편집 시 발생하는 로그 확률 변화를 예측하는 수식.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 Residual SAE가 해결하지 못했던 state-space 및 hybrid recurrent language model의 matrix cache write 문제를 다룬다. Gated DeltaNet, Mamba-2, RWKV-7과 같은 현대 recurrent 모델들은 𝐤t𝐯t⊤ 형태의 rank-1 업데이트를 캐시에 기록하는데, 기존의 벡터 기반 SAE는 이 캐시를 직접 읽거나 수정하는 데 적합하지 않다 [Figure 1]. 이러한 모델들은 고정된 슬롯에 지속적으로 값을 중첩(superposition)하여 기록하므로, 해당 아키텍처의 쓰기 방식을 반영한 새로운 Sparse Autoencoder 구조가 필요하다.
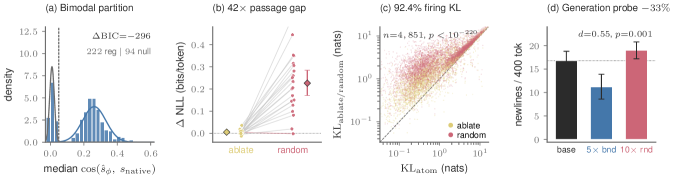
Figure 1 — WriteSAE atom의 캐시 대체 기법
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 각 디코더 atom을 원본 아키텍처와 동일한 rank-1 outer product 형태로 인코딩하는 WriteSAE를 제안한다. WriteSAE는 matched Frobenius norm 조건 하에 학습되어, 개별 캐시 슬롯을 독립적으로 대체할 수 있는 능력을 갖춘다. 주요 실험 결과로, Qwen3.5-0.8B 모델의 L9 H4 레이어에서 WriteSAE의 atom을 사용한 캐시 대치가 기존의 matched-norm ablation 대비 92.4%의 firing 상황에서 더 우수한 성능(낮은 KL 발산)을 기록했다 [Table 2]. 또한, 제안된 3요소 로그 확률 예측 수식은 실험적으로 측정된 결과와 median R²=0.98의 높은 상관관계를 보였다 [Figure 7]. 마지막으로, 3개의 캐시 슬롯에 대한 Closed-form generation intervention을 통해 midrank target 토큰의 생성 확률을 33.3%에서 100%로 성공적으로 끌어올리는 behavioral install 성과를 달성했다 [Figure 5].
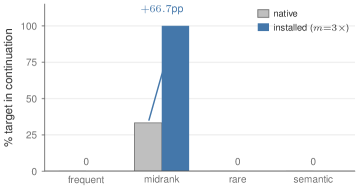
Figure 5 — 타겟 토큰 생성 확률 향상 효과
4. Conclusion & Impact (결론 및 시사점)
본 논문은 recurrent 모델의 핵심 쓰기 사이트인 캐시 상태를 해석하고 조작할 수 있는 WriteSAE를 통해 매트릭스 기반 모델의 메커니즘을 규명하였다. 이 연구는 단순히 residual stream을 해석하는 것을 넘어, 모델의 메모리 쓰기 과정 자체가 어떻게 해석 가능한 feature들을 수용하고 있는지를 보여준다. 제안된 방법론은 다양한 matrix-recurrent 아키텍처로 확장 가능하며, 특히 모델의 행동을 특정 목표로 정밀하게 steering하려는 후속 연구에 강력한 기반을 제공한다.
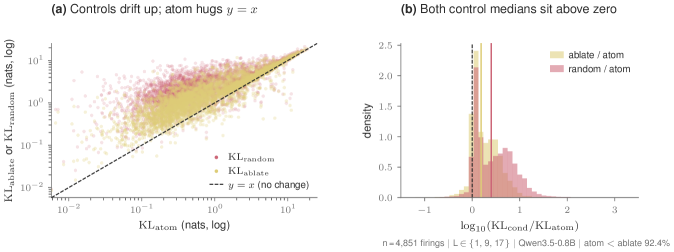
Figure 2 — 모델 예측 성능(KL) 비교 결과
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Unstable Features, Reproducible Subspaces: Understanding Seed Dependence in Sparse Autoencoders
- [논문리뷰] Interpreting and Steering a Text-to-Speech Language Model with Sparse Autoencoders
- [논문리뷰] Sanity Checks for Sparse Autoencoders: Do SAEs Beat Random Baselines?
- [논문리뷰] OrtSAE: Orthogonal Sparse Autoencoders Uncover Atomic Features
- [논문리뷰] CorrSteer: Steering Improves Task Performance and Safety in LLMs through Correlation-based Sparse Autoencoder Feature Selection
Review 의 다른글
- 이전글 [논문리뷰] Vividh-ASR: A Complexity-Tiered Benchmark and Optimization Dynamics for Robust Indic Speech Recognition
- 현재글 : [논문리뷰] WriteSAE: Sparse Autoencoders for Recurrent State
- 다음글 [논문리뷰] ATLAS: Agentic or Latent Visual Reasoning? One Word is Enough for Both
댓글