[논문리뷰] Sparse Autoencoders enable Robust and Interpretable Fine-tuning of CLIP models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Fabian Morelli, Arnas Uselis, Ankit Sonthalia, Seong Joon Oh
1. Key Terms & Definitions (핵심 용어 및 정의)
- SAE-FT: Sparse Autoencoder를 활용하여 CLIP vision encoder의 fine-tuning 과정을 정규화하는 기법으로, 표현 공간 내의 의미 있는 특징(Feature)을 보존하며 최적화를 수행함.
- Representational Drift: Fine-tuning 과정에서 사전 학습된 모델의 내부 표현 공간이 의도치 않게 변형되어, 원래 모델이 가졌던 강건성(Robustness)이 손실되는 현상.
- Polysemantic Features: 고차원 임베딩 공간에서 여러 의미적 개념이 단일 차원이 아닌 superposition 형태로 압축되어 저장되는 현상.
- Top-k SAE: 고정된 수(k)의 특징만 활성화되도록 제약된 Sparse Autoencoder 구조로, 표현을 의미적으로 분해하는 데 사용됨.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 CLIP과 같은 대규모 vision-language 모델을 하위 태스크(downstream task)에 맞게 fine-tuning할 때 발생하는 OOD(Out-of-Distribution) 성능 저하 문제를 해결하고자 한다. 기존의 standard fine-tuning은 모델이 학습 데이터에 과적합되면서 사전 학습 단계에서 얻은 범용적인 표현들을 파괴(feature suppression)하는 문제가 있다. 이를 완화하기 위한 WiSE-FT나 기타 정규화 기법들이 존재하지만, 이들은 복잡한 텍스트 측 데이터 조작이나 연산 자원이 많이 드는 방식을 사용하거나, 정작 중요한 의미적 특징 보존에는 한계를 보인다 [Figure 1]. 따라서 본 연구는 모델의 시각적 표현 공간 내에서 의미적 특징을 보존하면서도 효율적으로 최적화를 유도하는 새로운 기법이 필요하다고 지적한다.
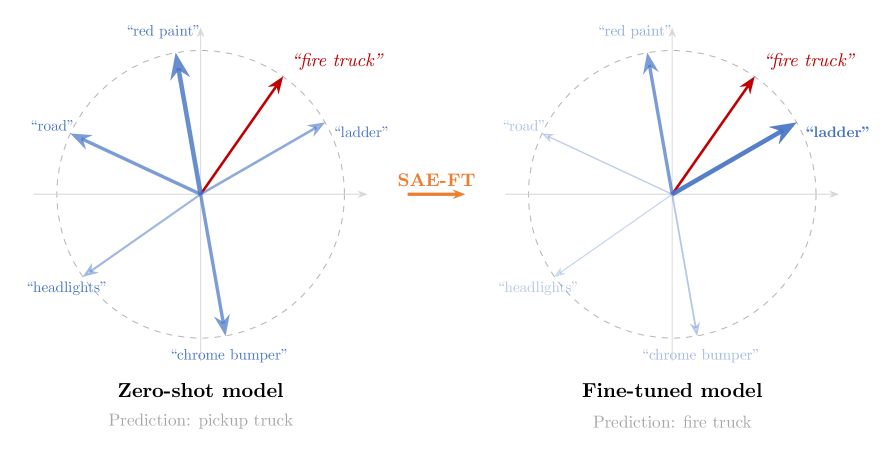
Figure 1 — SAE-FT의 직관적 작동 원리
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 사전 학습된 vision encoder의 표현을 고정된 SAE를 통해 의미적 단위로 분해하고, fine-tuning 중 발생하는 업데이트가 이들 특징들의 span 내에 머물도록 강제하는 SAE-FT를 제안한다. 제안된 방법론은 특징 간의 무분별한 추가/삭제를 억제하고, 오직 기존의 semantically meaningful 특징들을 재가중(re-weighting)함으로써 모델이 태스크 관련 정보에 집중하도록 한다 [Figure 3].
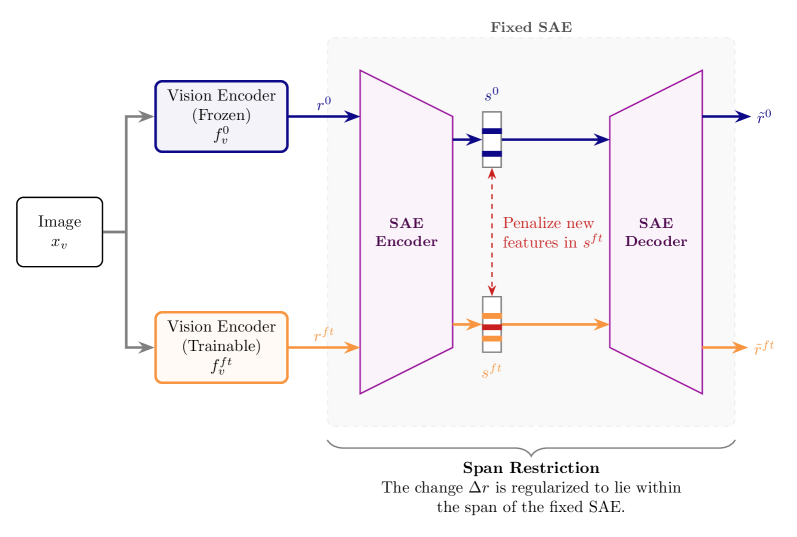
Figure 3 — SAE-FT 프레임워크 개요
실험 결과, SAE-FT는 ImageNet 및 여러 distribution shift 벤치마크에서 기존 vision encoder 전용 정규화 방법들보다 우수한 성능을 입증하였다. 특히, ImageNet 정확도 82.9%를 달성함과 동시에 OOD 성능 지표인 ImageNet-A와 ImageNet-R에서 기존 기법들을 상회하는 강건성을 보였다 [Table 3]. 또한, CIFAR-10, CIFAR-100 등 다양한 하위 데이터셋으로의 전이 학습에서도 가장 높은 평균 정확도를 기록하여, 사전 학습된 지식을 효과적으로 보존함을 입증하였다 [Table 4].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Sparse Autoencoder를 fine-tuning 최적화 루프에 도입함으로써, 모델의 표현 공간을 해석 가능한 단위로 제어하고 강건한 전이 학습을 가능하게 한다는 결론을 도출하였다. SAE-FT는 외부 데이터 증강이나 복잡한 텍스트 프롬프트 엔지니어링 없이도 vision-only 설정만으로 SOTA 급의 robust 성능을 달성할 수 있음을 보여준다. 이 연구는 foundation model의 내부 동작을 기계적으로 해석하고 제어하는 것이 모델 최적화에 실질적인 이득을 줄 수 있다는 중요한 시사점을 남기며, 향후 멀티모달 정규화로의 확장 가능성을 제시한다.
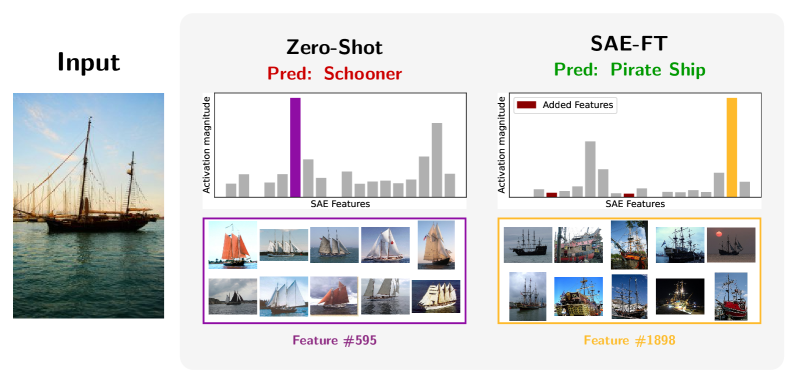
Figure 6 — SAE-FT의 특징 재가중 사례
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] SAE Interventions are Unreliable: Post-Intervention Recovery of Suppressed Behavior
- [논문리뷰] Sanity Checks for Sparse Autoencoders: Do SAEs Beat Random Baselines?
- [논문리뷰] BrainExplore: Large-Scale Discovery of Interpretable Visual Representations in the Human Brain
- [논문리뷰] RPCANet++: Deep Interpretable Robust PCA for Sparse Object Segmentation
- [논문리뷰] Vision as Unified Multimodal Generation
Review 의 다른글
- 이전글 [논문리뷰] Solvita: Enhancing Large Language Models for Competitive Programming via Agentic Evolution
- 현재글 : [논문리뷰] Sparse Autoencoders enable Robust and Interpretable Fine-tuning of CLIP models
- 다음글 [논문리뷰] Steered LLM Activations are Non-Surjective
댓글