[논문리뷰] LiteFrame: Efficient Vision Encoders Unlock Frame Scaling in Video LLMs
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jihwan Kim, Nikhil Parthasarathy, Danfeng Qin, Junhwa Hur, Deqing Sun, Bohyung Han, Ming-Hsuan Yang, Boqing Gong
1. Key Terms & Definitions (핵심 용어 및 정의)
- LiteFrame: 본 논문에서 제안하는 효율적인 비디오 인코더로, 프레임 내 토큰 압축을 내재화하여 LLM과 ViT 간의 연산 병목을 동시에 해결하는 모델입니다.
- WAP (Weighted Average Pooling): 공간적·시간적 정보를 효과적으로 유지하면서 토큰 수를 줄이는 압축 프리미티브로, 본 논문의 CTD 학습을 위한 정답(Ground Truth) 생성에 사용됩니다.
- CTD (Compressed Token Distillation): 대형 Teacher 모델의 정보 밀도가 높은 압축된 표현을 경량 Student 모델이 직접 예측하도록 가르치는 새로운 학습 프레임워크입니다.
- LMA (Language Model Adaptation): 비디오-텍스트 쌍을 사용하여 LLM과 인코더를 미세 조정함으로써 모달리티 간극을 줄이고 긴 시간적 맥락을 처리하도록 최적화하는 단계입니다.
- Scaling Paradox: 기존의 Post-hoc 토큰 감소 방식이 LLM의 부하를 줄이지만, 역설적으로 시각적 인코더의 연산 비용이 새로운 병목 현상을 유발하여 전체적인 확장성을 제한하는 문제를 지칭합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 장편 비디오 이해를 위해 Video LLMs를 확장할 때 발생하는 고질적인 계산 복잡도와 효율성 병목 문제를 해결하는 데 집중합니다. 기존의 ‘extract-and-reduce’ 패러다임은 LLM의 2차 복잡도(Quadratic Complexity)를 해결하기 위해 Post-hoc 토큰 감소 기법을 사용하지만, 이는 오히려 매 프레임을 처리해야 하는 시각적 인코더(ViT)의 연산 비용을 새로운 병목 지점으로 만듭니다 [Figure 1]. 결과적으로 전체 파이프라인의 효율성 개선이 제한되며, 이는 장편 비디오 처리에 필요한 프레임 수 확장을 방해합니다. 저자들은 이러한 인코더의 연산 부담을 해소하면서도 정확도를 유지하는 것이 차세대 MLLM의 핵심 과제임을 지적합니다.
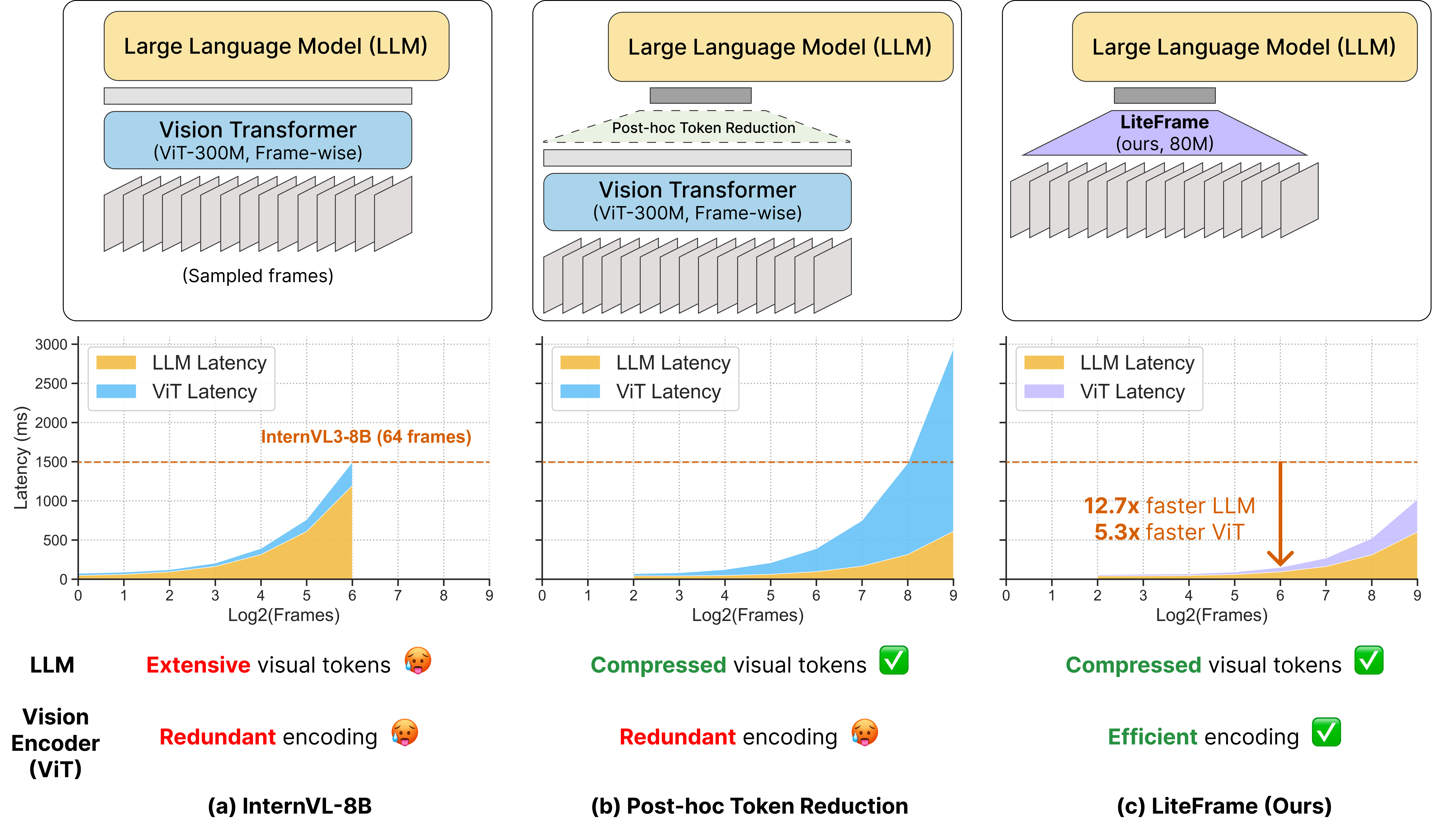
Figure 1 — Video LLM의 병목 문제 및 LiteFrame 해결책
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 LiteFrame을 통해 시각적 인코더 내부에서 spatio-temporal 토큰 압축을 수행하여 비디오 이해 효율을 극대화합니다. 먼저, student 인코더는 깊이별(Depth-wise) 1D 시간적 컨볼루션 레이어를 도입하여 연산량은 줄이면서 시간적 맥락을 포착하도록 설계되었습니다 [Table 2]. 이후 CTD를 통해 student 인코더가 Teacher의 WAP 결과값을 직접 예측하도록 학습하여 불필요한 연산 없이 밀도 높은 정보를 학습합니다 [Figure 4]. 마지막으로 LMA를 적용해 LLM을 확장된 시간적 맥락에 최적화합니다. 실험 결과, LiteFrame은 InternVL3-8B 대비 35% 의 End-to-End Latency 감소와 8배 더 많은 프레임 처리 능력을 달성했습니다 [Table 3]. 주요 벤치마크(Video-MME, MLVU, LongVideoBench 등)에서 기존 Post-hoc 기법들을 상회하는 높은 정확도를 보여주며 효율성-정확도 파레토 전선을 재정의했습니다 [Figure 2].
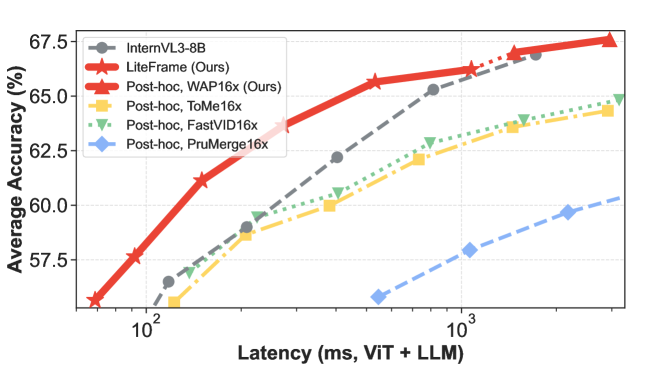
Figure 2 — 비디오 이해 효율 파레토 전선
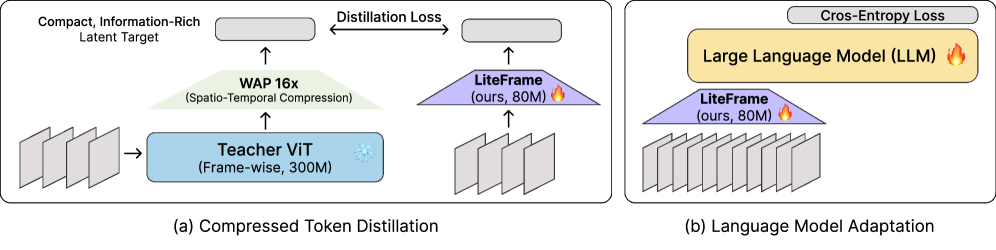
Figure 4 — LiteFrame 학습 프레임워크 개요
4. Conclusion & Impact (결론 및 시사점)
본 논문은 시각적 인코더 내부에 토큰 압축을 내재화하는 것이 장편 비디오 이해의 효율성을 달성하는 핵심 경로임을 입증했습니다. CTD와 LMA를 결합한 LiteFrame은 기존의 Post-hoc 방식이 가진 Latency 병목을 근본적으로 제거하여 더 긴 비디오를 효과적으로 분석할 수 있게 합니다. 이 연구는 고정된 컴퓨팅 자원 내에서 더 긴 비디오 정보를 수용하고자 하는 연구계와 산업계에 새로운 효율적 설계 방향을 제시합니다. 향후 더욱 가벼운 모델로의 확장이 가능해진다면, 모바일 및 엣지 환경에서의 Video LLMs 보급에도 상당한 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] EarlyTom: Early Token Compression Completes Fast Video Understanding
- [논문리뷰] Do All Visual Tokens Matter Equally? Object-Evidence Preserving Token Merging for Vision-Language Retrieval
- [논문리뷰] Rethinking RAG in Long Videos: What to Retrieve and How to Use It?
- [논문리뷰] PARCEL: Pool-Anchored Resampling with Conditioned Elastic Queries for Efficient Vision-Language Understanding
- [논문리뷰] OmniSIFT: Modality-Asymmetric Token Compression for Efficient Omni-modal Large Language Models
Review 의 다른글
- 이전글 [논문리뷰] Lance: Unified Multimodal Modeling by Multi-Task Synergy
- 현재글 : [논문리뷰] LiteFrame: Efficient Vision Encoders Unlock Frame Scaling in Video LLMs
- 다음글 [논문리뷰] LongLive-2.0: An NVFP4 Parallel Infrastructure for Long Video Generation
댓글