[논문리뷰] PresentAgent-2: Towards Generalist Multimodal Presentation Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Wei Wu, Ziyang Xu, Zeyu Zhang, Yang Zhao, Hao Tang
1. Key Terms & Definitions (핵심 용어 및 정의)
- PresentAgent-2: 사용자 쿼리를 기반으로 주제 선정부터 심층 리서치, 멀티모달 자원 수집, 슬라이드/스크립트 생성, 최종 영상 합성을 수행하는 에이전트 프레임워크.
- Deep Research: 사용자의 오픈 엔드 쿼리를 해결하기 위해 웹 페이지, 튜토리얼 등 프레젠테이션에 최적화된 소스를 검색하고, 텍스트와 멀티모달 자원(이미지, GIF, 비디오)을 수집하는 과정.
- Three Presentation Modes: 하나의 통합 프레임워크 내에서 지원하는 3가지 전달 방식(단일 발표인 Single Presentation, 다중 화자 대화인 Discussion, 실시간 질의응답이 가능한 Interaction).
- PresentEval: 본 연구에서 제안하는 멀티모달 프레젠테이션 벤치마크로, Objective Quiz Evaluation과 Subjective Mode-specific Evaluation을 통해 성능을 측정함.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 문서 기반 프레젠테이션 자동화 도구가 가지는 제약을 극복하고, 사용자의 오픈 엔드 쿼리로부터 직접적인 프레젠테이션 영상을 생성하는 시스템을 목표로 한다. 기존 연구들은 주로 논문이나 보고서와 같은 완성된 문서를 입력으로 가정하여 슬라이드를 제작하지만, 실질적인 사용자 니즈는 구체적인 문서 없이 주제에 대한 설명을 요구하는 경우가 많다. 이 경우 시스템은 스스로 주제를 파악하고, 신뢰할 수 있는 멀티모달 자원을 검색하며, 구조화된 영상으로 변환해야 하는 도전에 직면한다. 이를 해결하기 위해 저자들은 PresentAgent-2를 제안하며, 이는 검색-계획-생성-합성 단계로 이어지는 엔드투엔드 파이프라인을 구축한다 [Figure 4].
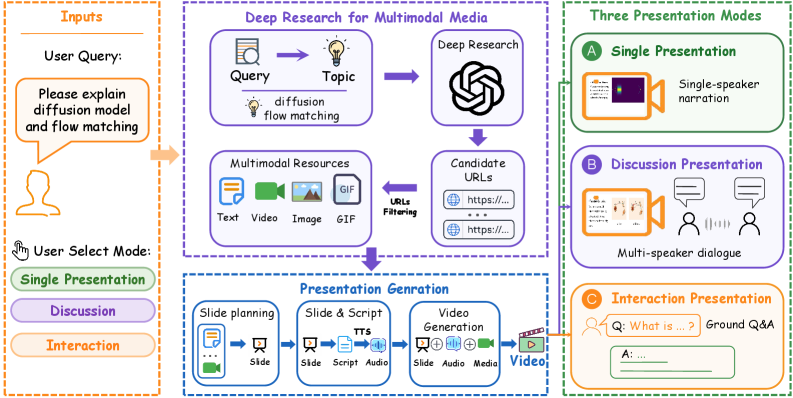
Figure 4 — PresentAgent-2 전체 프레임워크
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 사용자 쿼리에서 시작하여 멀티모달 프레젠테이션 영상을 생성하는 프레임워크인 PresentAgent-2를 제안한다. 이 시스템은 먼저 Deep Research를 통해 주제 관련 텍스트와 시각 자료를 확보하고, 이를 바탕으로 구조화된 슬라이드와 스크립트를 생성한 뒤, 동적 미디어를 보존한 상태로 영상을 합성한다 [Figure 4]. 특히, 단순 정적 스크린샷이 아닌, 동적인 GIF와 비디오를 프레젠테이션 내에 직접 임베딩하여 시각적 전달력을 극대화한다. 실험 결과, PresentAgent-2는 Qwen3.5-VL-Plus 모델 기반으로 세 가지 모드에서 모두 4.8점 이상의 높은 Quiz Score를 달성하여 우수한 지식 전달 성능을 입증했다 [Table 4]. 또한, 주관적 평가에서도 평균 4.4~4.5점 수준의 높은 Subjective Score를 기록하며, 인간이 만든 참조 영상과 비교해도 손색없는 콘텐츠 품질과 자연스러운 대화형 전달 능력을 보여주었다 [Table 4].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 오픈 엔드 쿼리 기반의 멀티모달 프레젠테이션 영상 생성을 위한 새로운 패러다임을 제시하며, 이를 체계적으로 평가할 수 있는 벤치마크를 구축하였다. 제안된 시스템은 단순한 문서 변환을 넘어 실제 교육 및 연구 환경에서 지식 전달의 형태를 다각화할 수 있는 가능성을 보여준다. 특히 멀티 화자 대화나 인터랙티브 질의응답을 지원함으로써 프레젠테이션의 상호작용성을 획기적으로 개선하였다. 본 연구는 향후 생성형 에이전트가 지식 기반 커뮤니케이션 도구로서 산업계와 학계에 깊이 침투하는 데 중요한 기술적 토대가 될 것으로 기대된다.
Figure 5 — 모드별 생성 결과 예시
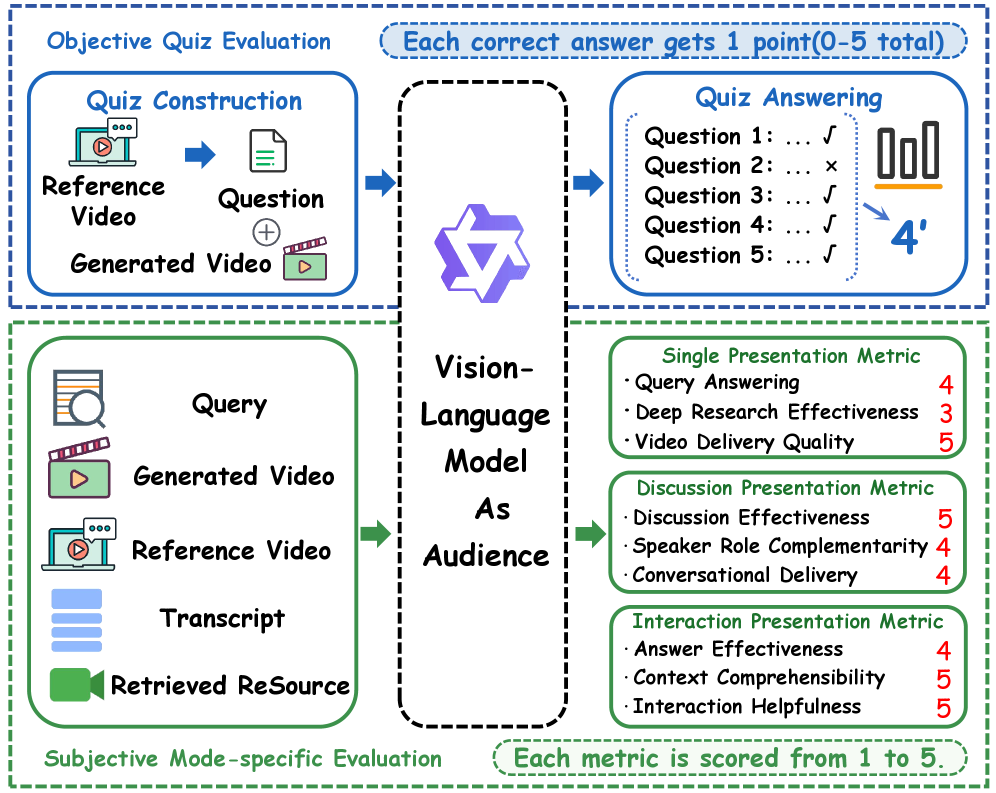
Figure 3 — 평가 파이프라인 개요
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Vision-DeepResearch Benchmark: Rethinking Visual and Textual Search for Multimodal Large Language Models
- [논문리뷰] DeepSearchQA: Bridging the Comprehensiveness Gap for Deep Research Agents
- [논문리뷰] RoboDojo: A Unified Sim-and-Real Benchmark for Comprehensive Evaluation of Generalist Robot Manipulation Policies
- [논문리뷰] MuseBench: Benchmarking Intent-Level Audiovisual Arts Understanding in MLLMs
- [논문리뷰] Speaker-Aware Temporal Aggregation Strategies on Segment Representations for Depression Detection in Dyadic Interaction: A Benchmark Study
Review 의 다른글
- 이전글 [논문리뷰] Predicting Decisions of AI Agents from Limited Interaction through Text-Tabular Modeling
- 현재글 : [논문리뷰] PresentAgent-2: Towards Generalist Multimodal Presentation Agents
- 다음글 [논문리뷰] RealICU: Do LLM Agents Understand Long-Context ICU Data? A Benchmark Beyond Behavior Imitation
댓글