[논문리뷰] Predicting Decisions of AI Agents from Limited Interaction through Text-Tabular Modeling
링크: 논문 PDF로 바로 열기
저자: Eilam Shapira, Moshe Tennenholtz, Roi Reichart
1. Key Terms & Definitions (핵심 용어 및 정의)
- Target Agent: 예측의 대상이 되는 미지의 AI 에이전트로, 내부 프롬프트, 제어 로직, 구현 방식이 외부 관찰자에게 공개되지 않은 에이전트.
- LLM-as-Observer: frozen LLM을 활용하여 현재 게임 상태와 dialogue를 인코딩하고, 생성된 답변을 폐기한 뒤 내부 Hidden State를 결정론적 특징값(feature)으로 추출하는 기법.
- Target-adaptive Text-tabular Prediction: 각 decision point를 게임 상태 변수, 대화, 과거 이력을 포함한 테이블 행(row)으로 구조화하고, tabular foundation model을 통해 target 에이전트에 빠르게 적응시키는 예측 설정.
- Cross-population Transfer: frontier-LLM 기반의 source population에서 학습한 예측 모델이, scaffolding(제어 로직, 규칙 기반 fallback 등)으로 인해 이질성이 존재하는 target population으로 전이되는 성능 평가 방식.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 미지의 AI 에이전트가 제한된 과거 상호작용만으로 타 에이전트의 다음 결정을 예측할 수 있는지에 대한 핵심 질문을 다룬다. 실제 경제 활동에서의 AI 에이전트 간 상호작용은 상업적 비밀 및 통제된 환경의 부재로 인해 체계적인 모델링이 어렵다. 저자들은 기존의 LLM-as-Predictor 접근 방식이 단순한 in-context prompting에 의존하여 타겟 에이전트의 구체적 전략을 적응적으로 학습하는 데 한계가 있음을 지적한다 [Figure 2]. 따라서 언어 기반의 경제 게임(bargaining, negotiation) 환경에서 에이전트 간의 전략적 행동을 정교하게 예측할 수 있는 프레임워크가 요구된다.

Figure 2 — 예측 방법론 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 에이전트 예측을 target-adaptive text-tabular task로 공식화하고, LLM-as-Observer를 활용한 새로운 특징 추출 블록을 제안한다. 해당 방법론은 고정된 작은 크기의 frozen LLM을 인코더로 활용하여 상황을 파악하고, 그 내부 Hidden State를 Tabular Foundation Model(TabPFN)에 전달하여 최종 결정을 예측한다 [Figure 2]. 13개의 frontier-LLM 에이전트를 source로 학습하고 91개의 대학 해커톤 에이전트를 target으로 평가한 결과, 제안 모델은 baseline 대비 월등한 성능을 보였다. 특히 K=16 조건에서 Observer 특징을 활용할 경우, response prediction의 AUC가 양쪽 게임 가족(bargaining, negotiation)에서 약 4포인트 향상되었고, bargaining 상황에서의 제안 예측 오차(offer-prediction error)를 14% 감소시켰다 [Table 2]. 이는 단순한 LLM prompting보다 tabular 기반의 representation adaptation이 훨씬 효과적임을 입증한다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 AI 에이전트의 의사결정을 예측함에 있어 단순한 직접 prompting보다 representation 학습과 adaptation을 분리하는 text-tabular 방식이 우월함을 증명하였다. LLM-as-Observer를 통해 추출된 Hidden State는 기존의 직접적인 LLM 답변보다 훨씬 더 강력한 전략적 결정 신호를 제공하며, 이는 frozen LLM이 답변으로 드러내지 않는 심층적인 정보를 담고 있음을 시사한다. 이 연구는 향후 에이전트 기반 경제 시스템에서 타 에이전트의 전략을 파악하고 최적화하는 데 있어 중요한 기술적 토대를 마련할 것으로 기대된다.
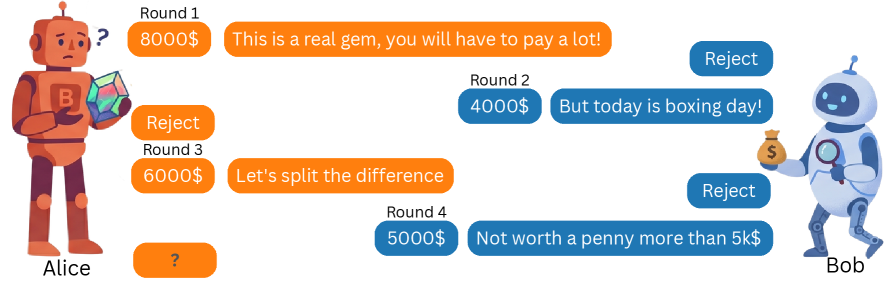
Figure 1 — 에이전트 예측 작업 설정
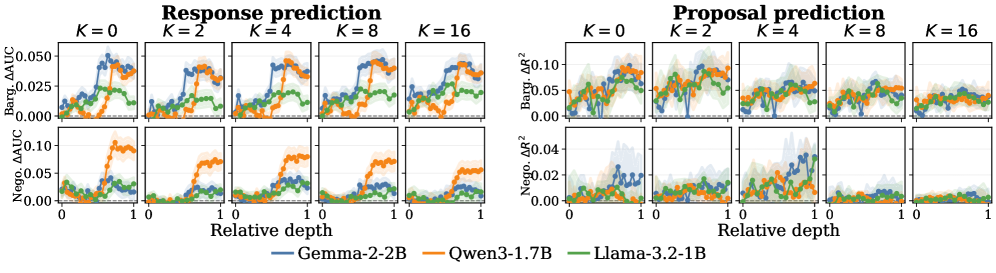
Figure 3 — 레이어 깊이에 따른 성능 안정성
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Guided Self-Evolving LLMs with Minimal Human Supervision
- [논문리뷰] Glance: Accelerating Diffusion Models with 1 Sample
- [논문리뷰] First Frame Is the Place to Go for Video Content Customization
- [논문리뷰] Thai Semantic End-of-Turn Detection for Real-Time Voice Agents
- [논문리뷰] AutoIntent: AutoML for Text Classification
Review 의 다른글
- 이전글 [논문리뷰] PersonalAI 2.0: Enhancing knowledge graph traversal/retrieval with planning mechanism for Personalized LLM Agents
- 현재글 : [논문리뷰] Predicting Decisions of AI Agents from Limited Interaction through Text-Tabular Modeling
- 다음글 [논문리뷰] PresentAgent-2: Towards Generalist Multimodal Presentation Agents
댓글